

The most critical features of a new social network for users fed up with Musk and Twitter, are as follows;
Less critical but definitely helpful features of the platform;
In this post, we'll focus on the first feature. Importing Twitter's archive.zip file.
Twitter haven't made your data all that easy to obtain. It's great that they give you access to it (legally, they have to). The format is crap.
It actually comes as a mini web archive and all your data is stuck in JavaScript files. It is more of a web app than convenient storage of data.
When you open up the Your archive.html file you get something like this;
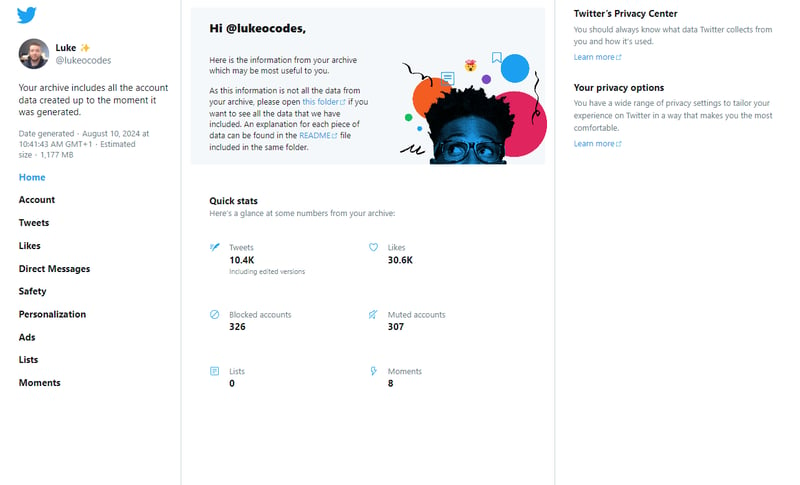
Note: I made the descision pretty early on to build using Next.js for the site, Go and GraphQL for the backend.
So, what do you do when your data isn't structured data?
Well, you parse it.
Head on over to the official docs on how to get started with Go, and set up your project directory.
We're going to hack this process together. It seems one of the most important features to attract people who feel too attached to TwitterX.
First step is to create a main.go file. In this file we'll GO (hah) and do some STUFF;
package main
import (
"fmt"
"os"
)
func run(path string) {
fmt.Println("Path:", path)
}
func main() {
if len(os.Args) < 2 {
fmt.Println("Please provide a path as an argument.")
return
}
path := os.Args[1]
run(path)
}
At every step, we'll run the file like so;
go run main.go twitter.zip
If you don't have a Twitter archive export, create a simple manifest.js file and give it the following JavaScript.
window.__THAR_CONFIG = {
"userInfo" : {
"accountId" : "1234567890",
"userName" : "lukeocodes",
"displayName" : "Luke ✨"
},
};
Compress that into your twitter.zip file that we'll use throughout.
The next step is to read the contents of the zip file. We want to do this as efficiently as possible, and reduce time data is extracted on the disk.
There are many files in the zip that don't need to be extracted, too.
We'll edit the main.go file;
package main
import (
"archive/zip"
"fmt"
"log"
"os"
)
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("Files in the zip archive:")
for _, f := range r.File {
fmt.Println(f.Name)
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
path:= os.Args[1]
run(path)
}
This archive file is seriously unhelpful. We want to check for just .js files, and only in the /data directory.
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"strings"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated? :/
if err != nil {
log.Fatal(err)
}
// Print the contents
fmt.Printf("Contents of %s:\n", file.Name)
fmt.Println(string(contents))
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("JavaScript files in the zip archive:")
for _, f := range r.File {
// Use filepath.Ext to check the file extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
path:= os.Args[1]
run(path)
}
We've found the structured data. Now we need to parse it. The good news is there are existing packages for using JavaScript inside Go. We'll be using goja.
If you're on this section, familiar with Goja, and you've seen the output of the file, you may see we're going to have errors in our future.
Install goja:
go get github.com/dop251/goja
Now we're going to edit the main.go file to do the following;
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"strings"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated? :/
if err != nil {
log.Fatal(err)
}
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(contents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
fmt.Printf("Parsed JavaScript file: %s\n", file.Name)
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("JavaScript files in the zip archive:")
for _, f := range r.File {
// Use filepath.Ext to check the file extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
path:= os.Args[1]
run(path)
}
SUPRISE. window is not defined might be a familiar error. Basically goja runs an EMCA runtime. window is browser context and sadly unavailable.
I went through a few issues at this point. Including not being able to return data because it's a top level JS file.
Long story short, we need to modify the contents of the files before loading them into the runtime.
Let's modify the main.go file;
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"regexp"
"strings"
"github.com/dop251/goja"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc)
if err != nil {
log.Fatal(err)
}
// Regular expressions to replace specific patterns
reConfig := regexp.MustCompile(`window\.\w+\s*=\s*{`)
reArray := regexp.MustCompile(`window\.\w+\.\w+\.\w+\s*=\s*\[`)
// Replace patterns in the content
processedContents := reConfig.ReplaceAllStringFunc(string(contents), func(s string) string {
return "var data = {"
})
processedContents = reArray.ReplaceAllStringFunc(processedContents, func(s string) string {
return "var data = ["
})
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(processedContents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
// Retrieve the value of the 'data' variable from the JavaScript context
value := vm.Get("data")
if value == nil {
log.Fatalf("No data variable found in the JS file")
}
// Output the parsed data
fmt.Printf("Processed JavaScript file: %s\n", file.Name)
fmt.Printf("Data extracted: %v\n", value.Export())
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
for _, f := range r.File {
// Check if the file is in the /data directory and has a .js extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
path:= os.Args[1]
run(path)
}
Hurrah. Assuming I didn't muck up the copypaste into this post, you should now see a rather ugly print of the struct data from Go.
Edit the main.go file to marshall the JSON output.
package main
import (
"archive/zip"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"regexp"
"strings"
"github.com/dop251/goja"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated :/
if err != nil {
log.Fatal(err)
}
// Regular expressions to replace specific patterns
reConfig := regexp.MustCompile(`window\.\w+\s*=\s*{`)
reArray := regexp.MustCompile(`window\.\w+\.\w+\.\w+\s*=\s*\[`)
// Replace patterns in the content
processedContents := reConfig.ReplaceAllStringFunc(string(contents), func(s string) string {
return "var data = {"
})
processedContents = reArray.ReplaceAllStringFunc(processedContents, func(s string) string {
return "var data = ["
})
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(processedContents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
// Retrieve the value of the 'data' variable from the JavaScript context
value := vm.Get("data")
if value == nil {
log.Fatalf("No data variable found in the JS file")
}
// Convert the data to a Go-native type
data := value.Export()
// Marshal the Go-native type to JSON
jsonData, err := json.MarshalIndent(data, "", " ")
if err != nil {
log.Fatalf("Error marshalling data to JSON: %v", err)
}
// Output the JSON data
fmt.Println(string(jsonData))
}
func run(zipFilePath string) {
// Open the zip file
r, err := zip.OpenReader(zipFilePath)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
for _, f := range r.File {
// Check if the file is in the /data directory and has a .js extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file
}
}
}
func main() {
// Example usage
if len(os.Args) < 2 {
log.Fatal("Please provide the path to the zip file as an argument.")
}
zipFilePath := os.Args[1]
run(zipFilePath)
}
That's it!
go run main.go twitter.zip
}
"userInfo": {
"accountId": "1234567890",
"displayName": "Luke ✨",
"userName": "lukeocodes"
}
}
I'll be open sourcing a lot of this work so that others who want to parse the data from the archive, can store it how they like.
The above is the detailed content of Time to Leave? Time to Rebuild! Making Twitter. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



