

Recursive operations in software development


Let’s take a look at this classic recursive factorial:
#include
int factorial(int n)
{
int previous = 0xdeadbeef;
if (n == 0 || n == 1) {
return 1;
}
previous = factorial(n-1);
return n * previous;
}
int main(int argc)
{
int answer = factorial(5);
printf("%d\n", answer);
}
Recursive factorial - factorial.c
The idea of a function calling itself is difficult to grasp at first. In order to make this process more vivid and concrete, the following figure shows the situation of the endpoint on the stack when factorial(5) is called and the line of code n == 1 is reached:

Every call to factorial generates a new stack frame. The creation and destruction of these stack frames is what makes the recursive version factorially slower than its corresponding iterative version. The accumulation of these stack frames may exhaust stack space before the call returns, causing your program to crash.
These worries often exist in theory. For example, the stack frame takes 16 bytes for each factorial (this may depend on the stack arrangement and other factors). If you're running a modern x86 Linux kernel on your computer, you typically have 8 GB of stack space, so n in a factorial program can go up to about 512,000. This is a huge result, and it takes 8,971,833 bits to represent it, so stack space is not an issue at all: a tiny integer—even a 64-bit integer—is stored in our stack space. It has overflowed thousands of times before it ran out.
We will look at the use of CPU in a while. For now, let’s take a step back from bits and bytes and treat recursion as a general technology. Our factorial algorithm boils down to pushing the integers N, N-1, … 1 onto a stack and multiplying them in reverse order. We actually use a program call stack to achieve this, here are the details of it: we allocate a stack on the heap and use it. Although the call stack has special characteristics, it is just another data structure that you can use however you want. I hope this diagram helps you understand this.
When you think of the call stack as a data structure, something becomes clearer: piling up those integers and then multiplying them together is not a good idea. That's a flawed implementation: it's like taking a screwdriver to drive a nail. It is more reasonable to use an iterative process to calculate the factorial.
However, there are so many screws that we can only pick one. There is a classic interview question where there is a mouse in a maze and you have to help the mouse find a piece of cheese. Suppose a rat can turn left or right in a maze. How do you model to solve this problem?
Like many problems in real life, you can simplify this problem of mice looking for cheese into a graph, with each node of a binary tree representing a position in the maze. You can then have the mouse turn left wherever possible, and when it reaches a dead end, backtrack and turn right again. Here’s an example of a mouse walking a maze:
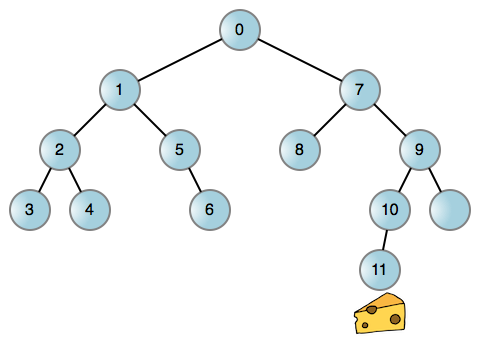
Every time it reaches the edge (line), let the mouse turn left or right to reach a new position. If you are blocked in any direction you turn, it means that the relevant edge does not exist. Now, let’s discuss it! This process, whether you use a call stack or other data structures, is inseparable from a recursive process. And using the call stack is very easy:
#include
#include "maze.h"
int explore(maze_t *node)
{
int found = 0;
if (node == NULL)
{
return 0;
}
if (node->hasCheese){
return 1;// found cheese
}
found = explore(node->left) || explore(node->right);
return found;
}
int main(int argc)
{
int found = explore(&maze);
}
Recursive Maze Solving Download
When we find cheese in maze.c:13, the stack looks like this. You can also see more detailed data in the GDB output, which is the data collected using the command.

It demonstrates the good behavior of recursion because this is a problem suitable for using recursion. And it's no surprise: when it comes to algorithms, recursion is the rule, not the exception. It shows up when you're searching, when you're traversing trees and other data structures, when you're parsing, when you need to sort -- it's everywhere. Just as pi or e are known as "gods" in mathematics because they are the basis of everything in the universe, recursion is the same: it just exists in the structure of calculations.
What’s great about Steven Skienna’s excellent book A Guide to Algorithm Design is that he interprets his work through “war stories” as a means to demonstrate the algorithms behind solving real-world problems. This is the best resource I know for expanding your knowledge of algorithms. Another reading is McCarthy's original paper on LISP implementation. Recursion is both its name and its fundamental principle in the language. The paper is both readable and interesting, and it's exciting to see a master's work at work.
迷路の問題に戻りましょう。ここで再帰を残すのは困難ですが、コールスタックを通じてそれを達成しなければならないという意味ではありません。 RRLL のような文字列を使用してターンを追跡し、この文字列を使用してマウスの次の動きを決定できます。あるいは、チーズハントの全体的なステータスを記録するために何か他のものを割り当てることもできます。引き続き再帰的なプロセスを実装しますが、必要なのは独自のデータ構造を実装することだけです。
スタック呼び出しの方が適しているため、これはより複雑に思えます。各スタック フレームは、現在のノードだけでなく、そのノードでの計算の状態も記録します (この場合、左のみに移動させたか、右に移動しようとしたか)。したがって、コードは重要ではなくなりました。しかし、オーバーフローや期待されるパフォーマンスを恐れて、この優れたアルゴリズムを放棄してしまうことがあります。それは愚かです!
ご覧のとおり、スタック領域は非常に大きく、スタック領域が使い果たされる前に他の制限が発生することがよくあります。一方で、問題の規模をチェックして、問題を安全に処理できるかどうかを確認できます。 CPU への懸念は、広く流通している 2 つの問題例、ダム階乗と恐ろしい記憶のない O(2n) フィボナッチ再帰によって引き起こされています。これらはスタック再帰アルゴリズムを正しく表現したものではありません。
実際、スタック操作は非常に高速です。通常、データへのスタック オフセットは非常に正確で、キャッシュ内のホット データであり、特殊な命令がそのデータに対して動作します。同時に、ヒープ上に割り当てられた独自のデータ構造の使用に伴うオーバーヘッドも大きくなります。スタック呼び出し再帰よりも複雑でパフォーマンスの悪い実装メソッドを作成する人がよくいます。最後に、最新の CPU のパフォーマンスは非常に優れており、一般に CPU がパフォーマンスのボトルネックになることはありません。プログラムのパフォーマンスとそのパフォーマンスの測定について常に考えるのと同じように、プログラムの単純さを犠牲にすることを検討するときは注意してください。
次の記事はスタックの探索シリーズの最後の記事になります。テールコール、クロージャ、およびその他の関連概念について学びます。次に、私たちの古い友人である Linux カーネルに飛び込みます。読んでいただきありがとうございます!

The above is the detailed content of Recursive operations in software development. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1384
1384
 52
52

 Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
The key differences between CentOS and Ubuntu are: origin (CentOS originates from Red Hat, for enterprises; Ubuntu originates from Debian, for individuals), package management (CentOS uses yum, focusing on stability; Ubuntu uses apt, for high update frequency), support cycle (CentOS provides 10 years of support, Ubuntu provides 5 years of LTS support), community support (CentOS focuses on stability, Ubuntu provides a wide range of tutorials and documents), uses (CentOS is biased towards servers, Ubuntu is suitable for servers and desktops), other differences include installation simplicity (CentOS is thin)
 How to install centos
Apr 14, 2025 pm 09:03 PM
How to install centos
Apr 14, 2025 pm 09:03 PM
CentOS installation steps: Download the ISO image and burn bootable media; boot and select the installation source; select the language and keyboard layout; configure the network; partition the hard disk; set the system clock; create the root user; select the software package; start the installation; restart and boot from the hard disk after the installation is completed.
 Centos options after stopping maintenance
Apr 14, 2025 pm 08:51 PM
Centos options after stopping maintenance
Apr 14, 2025 pm 08:51 PM
CentOS has been discontinued, alternatives include: 1. Rocky Linux (best compatibility); 2. AlmaLinux (compatible with CentOS); 3. Ubuntu Server (configuration required); 4. Red Hat Enterprise Linux (commercial version, paid license); 5. Oracle Linux (compatible with CentOS and RHEL). When migrating, considerations are: compatibility, availability, support, cost, and community support.
 How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use Docker Desktop? Docker Desktop is a tool for running Docker containers on local machines. The steps to use include: 1. Install Docker Desktop; 2. Start Docker Desktop; 3. Create Docker image (using Dockerfile); 4. Build Docker image (using docker build); 5. Run Docker container (using docker run).
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 What to do after centos stops maintenance
Apr 14, 2025 pm 08:48 PM
What to do after centos stops maintenance
Apr 14, 2025 pm 08:48 PM
After CentOS is stopped, users can take the following measures to deal with it: Select a compatible distribution: such as AlmaLinux, Rocky Linux, and CentOS Stream. Migrate to commercial distributions: such as Red Hat Enterprise Linux, Oracle Linux. Upgrade to CentOS 9 Stream: Rolling distribution, providing the latest technology. Select other Linux distributions: such as Ubuntu, Debian. Evaluate other options such as containers, virtual machines, or cloud platforms.
 What to do if the docker image fails
Apr 15, 2025 am 11:21 AM
What to do if the docker image fails
Apr 15, 2025 am 11:21 AM
Troubleshooting steps for failed Docker image build: Check Dockerfile syntax and dependency version. Check if the build context contains the required source code and dependencies. View the build log for error details. Use the --target option to build a hierarchical phase to identify failure points. Make sure to use the latest version of Docker engine. Build the image with --t [image-name]:debug mode to debug the problem. Check disk space and make sure it is sufficient. Disable SELinux to prevent interference with the build process. Ask community platforms for help, provide Dockerfiles and build log descriptions for more specific suggestions.
 What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
