
 Hardware Tutorial
Hardware Review
Big models have their own understanding of language! MIT paper reveals the 'thought process' of large models
Hardware Tutorial
Hardware Review
Big models have their own understanding of language! MIT paper reveals the 'thought process' of large models
Big models have their own understanding of language! MIT paper reveals the 'thought process' of large models

大きなモデルは、現実世界についての独自の理解を形成することができます!
MITの研究によると、モデルの能力が高まるにつれて、現実の理解は単なる模倣を超えたものになる可能性があります。
たとえば、大型モデルが匂いを嗅いだことがない場合、それは匂いを理解できないことを意味しますか?
研究により、理解を容易にするためにいくつかの概念を自発的にシミュレートできることが判明しました。
この研究は、将来、大規模なモデルが言語と世界をより深く理解できることが期待されることを意味します この論文は、トップカンファレンスである ICML 24 に採択されました。

この論文の著者は、MIT コンピューター人工知能研究所 (CSAIL) の中国人博士課程学生 Charles Jin とその指導教員 Martin Rinard 教授です。
研究では、著者は大規模なモデルにコードテキストのみを学習するように依頼したところ、モデルがその背後にある意味を徐々に理解していることがわかりました。
リナード教授は、この研究は現代の人工知能の中核となる問題に直接取り組んでいると述べました -
大規模モデルの能力は単に大規模な統計的相関によるものなのか、それともそうでしょうか彼らが取り組む現実世界の問題について有意義な理解を生み出すということは本当ですか?
△出典:MIT公式ウェブサイト
同時に、この研究は多くの議論を引き起こしました。
一部のネチズンは、大きなモデルは人間とは異なる言語を理解するかもしれないが、この研究は少なくともモデルがトレーニングデータを記憶するだけではないことを示していると述べました。

大規模モデルに純粋なコードを学習させよう
大規模モデルが意味レベルの理解を生み出すことができるかどうかを調査するために、著者は、プログラム コードとそれに対応する入力と出力で構成される合成データ セットを構築しました。
これらのコード プログラムは、Karel と呼ばれる教育言語で書かれており、主に 2D グリッド世界でナビゲートするロボットのタスクを実装するために使用されます。
このグリッドの世界は 8x8 のグリッドで構成されており、各グリッドには障害物、マーカー、またはオープン スペースを含めることができます。ロボットはグリッド間を移動し、マーカーの配置/ピックアップなどの操作を実行できます。
カレル言語には、move (1 歩進む)、turnLeft (左に 90 度回転)、turnRight (右に 90 度回転)、pickMarker (マーカーを拾う)、putMarker (マーカーを配置) の 5 つの原始操作が含まれています。オブジェクト)、プログラムはこれらの基本的な操作のシーケンスで構成されます。
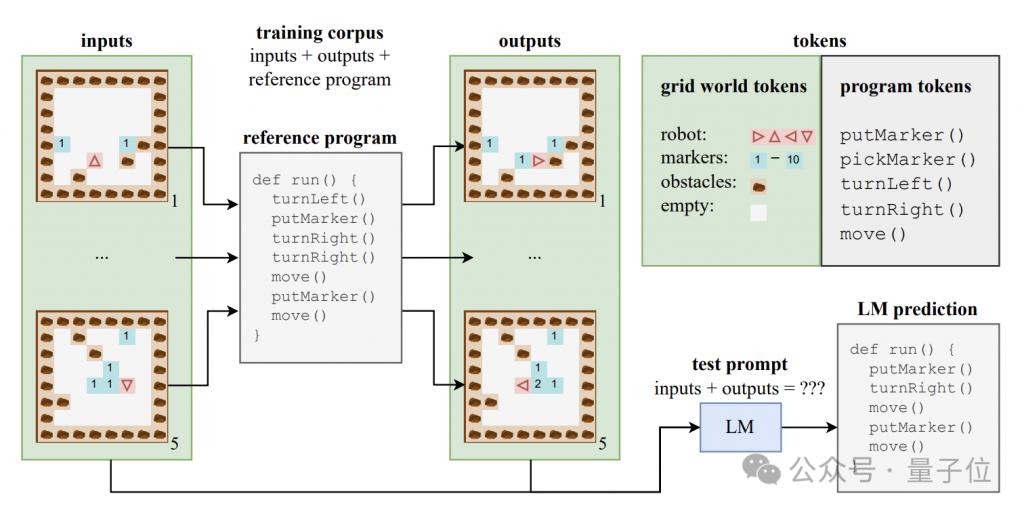
著者らは、各プログラムの長さが 6 ~ 10 の 500,000 個のカレル プログラムを含むトレーニング セットをランダムに生成しました。
各トレーニング サンプルは、5 つの入力状態、5 つの出力状態、および完全なプログラム コードの 3 つの部分で構成されます。入力状態と出力状態は特定の形式の文字列にエンコードされます。
このデータを使用して、著者らは標準の Transformer アーキテクチャの CodeGen モデルのバリアントをトレーニングしました。
トレーニング プロセス中、モデルは各サンプルの入出力情報とプログラム プレフィックスにアクセスできますが、プログラム実行の完全な軌跡と中間状態を確認することはできません。
トレーニング セットに加えて、著者はモデルの汎化パフォーマンスを評価するために 10,000 個のサンプルを含むテスト セットも構築しました。
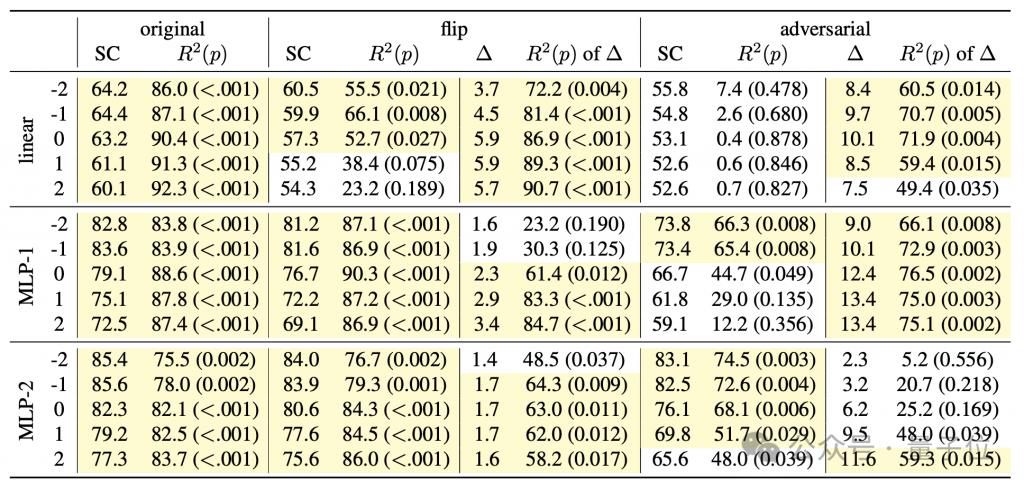
言語モデルがコードの背後にあるセマンティクスを把握しているかどうかを研究し、同時にモデルの「思考プロセス」を深く理解するために、著者は一連の検出器を設計しました。線形分類器と単一/二重隠れ層 MLP を含む組み合わせ。
検出器の入力は、プログラムトークンの生成過程における言語モデルの隠れた状態であり、予測ターゲットは、プログラムトークンに対するロボットの向きや偏差を含む、プログラム実行の中間状態です。初期位置とは、変位(位置)と障害物に正面を向いているかどうか(障害物)の 3 つの特性です。
生成モデルのトレーニング プロセス中、著者は 4000 ステップごとに上記の 3 つの特徴を記録し、検出器のトレーニング データ セットを形成するために生成モデルの隠れた状態も記録しました。
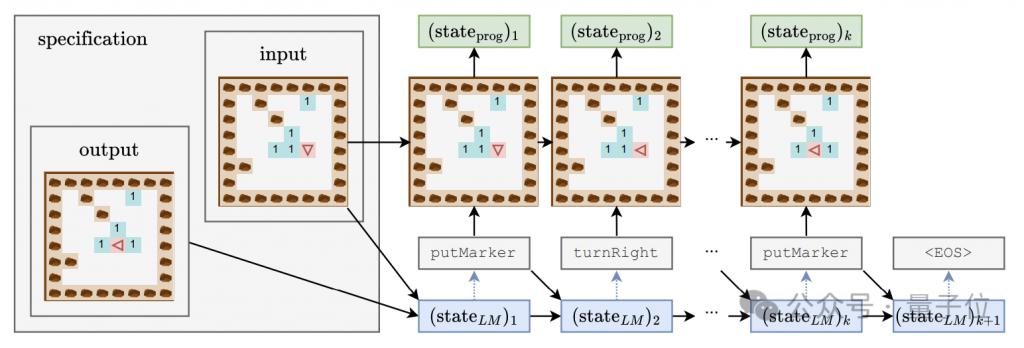
大規模モデル学習の 3 段階
言語によって生成されたプログラムの多様性、複雑さ、その他の指標を観察することによってモデル トレーニング プロセスが変化するにつれて、著者はトレーニング プロセスを 3 つのステージに分割します -
喃語 (ナンセンス) ステージ: 出力プログラムは反復性が高く、検出器の精度は不安定です。
文法習得段階: プログラムの多様性が急速に増加し、生成精度がわずかに増加し、混乱が減少します。これは、言語モデルがプログラムの構文構造を学習したことを示しています。
意味獲得段階: プログラムの多様性と構文構造の習熟度は安定していますが、生成精度と検出器のパフォーマンスは大幅に向上しており、言語モデルがプログラムの意味を学習していることを示しています。
Specifically, the Babbling stage occupies the first 50% of the entire training process. For example, when the training reaches about 20%, no matter what specification is input, the model will only generate a fixed program - "pickMarker" Repeat 9 times.
The grammar acquisition stage is at 50% to 75% of the training process. The model’s perplexity on the Karel program has dropped significantly, indicating that the language model has begun to better adapt to the statistical characteristics of the Karel program, but the generated The accuracy of the program has not improved much (from about 10% to about 25%), and it still cannot complete the task accurately.
The semantic acquisition stage is the final 25%, and the accuracy of the program has improved dramatically, from about 25% to more than 90%, and the generated program can accurately complete the given task.
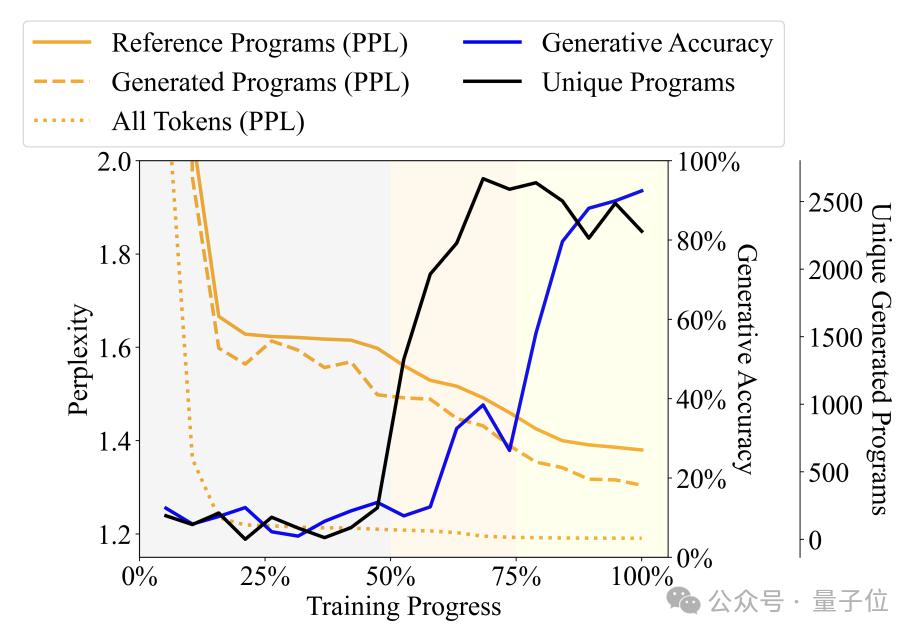
Further experiments found that the detector can not only predict the synchronized time step at time t, but also predict the program execution status of subsequent time steps.
For example, assume that the generative model generates token "move" at time t and will generate "turnLeft" at time t+1.
At the same time, the program state at time t is that the robot is facing north and is located at coordinates (0,0), while the robot at time t+1 will be that the robot will be facing west, with the position unchanged.
If the detector can successfully predict from the hidden state of the language model at time t that the robot will face the west at time t+1, it means that the hidden state is already included before generating "turnLeft" The status change information brought by this operation.
This phenomenon shows that the model does not only have a semantic understanding of the generated program part, but at each step of generation, it has already anticipated and planned the content to be generated next, showing that Develop preliminary future-oriented reasoning abilities.
But this discovery has brought new questions to this research-
Is the accuracy improvement observed in the experiment really an improvement in the generative model? , or is it the result of the detector's own inference?
In order to resolve this doubt, the author added a semantic detection intervention experiment.
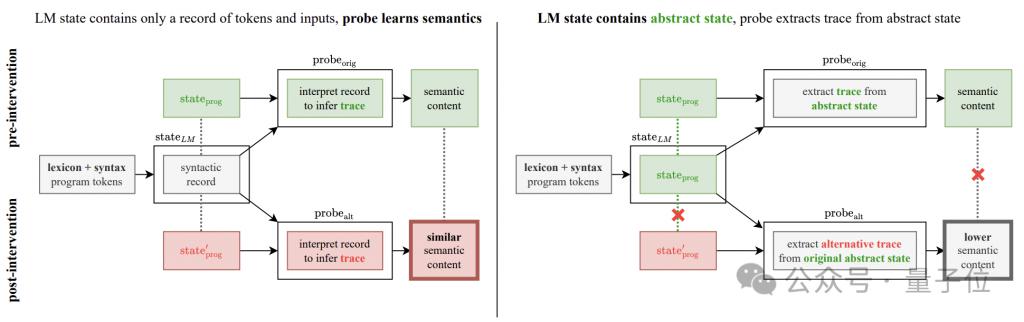
The basic idea of the experiment is to change the semantic interpretation rules of program operations, which are divided into two methods: "flip" and "adversarial".
"flip" is a forced reversal of the meaning of the instruction. For example, "turnRight" is forcibly interpreted as "turn left". However, only "turnLeft" and "turnRight" can perform this kind of reversal; #🎜 🎜#
"adversarial" randomly scrambles the semantics corresponding to all instructions. The specific method is as shown in the table below.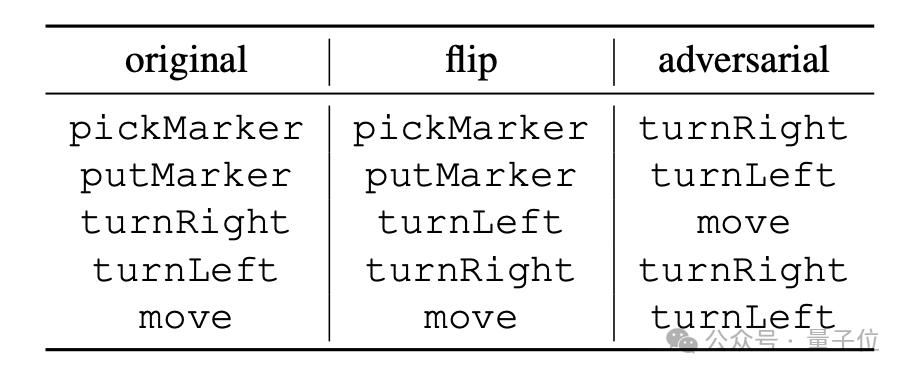
# 🎜🎜# [ 1 ] https://news.mit.edu/2024/llms-develop-own-understanding-of-reality-as-language-abilities-improve-0814
[ 2 ] https://www.reddit.com/r/LocalLLaMA/comments/1esxkin/llms_develop_their_own_understanding_of_reality/
The above is the detailed content of Big models have their own understanding of language! MIT paper reveals the 'thought process' of large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
