

In the past few years, the Transformer architecture has achieved great success, and it has also spawned a large number of variants, such as Vision Transformer (ViT), which is good at processing visual tasks. The Body Transformer (BoT) introduced in this article is a Transformer variant that is very suitable for robot strategy learning.
We know that when a physical agent performs correction and stabilization of actions, it often gives a spatial response based on the location of the external stimulus it feels. For example, human response circuits to these stimuli are located at the level of spinal neural circuits, and they are specifically responsible for the response of a single actuator. Corrective local execution is a major factor in efficient movements, which is particularly important for robots as well.
But previous learning architectures usually did not establish the spatial correlation between sensors and actuators. Given that robotic strategies use architectures that are largely developed for natural language and computer vision, they often fail to effectively exploit the structure of the robot body.
However, Transformer still has great potential in this regard. Studies have shown that Transformer can effectively handle long sequence dependencies and can easily absorb large amounts of data. The Transformer architecture was originally developed for unstructured natural language processing (NLP) tasks. In these tasks (such as language translation), the input sequence is usually mapped to an output sequence.
Based on this observation, a team led by Professor Pieter Abbeel of the University of California, Berkeley proposed the Body Transformer (BoT), which adds attention to the spatial location of sensors and actuators on the robot body.

Paper title: Body Transformer: Leveraging Robot Embodiment for Policy Learning
Paper address: https://arxiv.org/pdf/2408.06316v1
Project website: https://sferrazza .cc/bot_site
Code address: https://github.com/carlosferrazza/BodyTransformer
Specifically, BoT models the robot body into a graph, and the nodes in it are its sensors and actuators. It then uses a highly sparse mask on the attention layer to prevent each node from paying attention to parts other than its immediate neighbors. Connecting multiple structurally identical BoT layers brings together information from the entire graph without compromising the representational capabilities of the architecture. BoT performs well in both imitation learning and reinforcement learning, and is even considered by some to be the “Game Changer” of strategy learning.
Body Transformer
If the robot learning strategy uses the original Transformer architecture as the backbone, the useful information provided by the robot body structure is usually ignored. But in fact, this structural information can provide a stronger inductive bias for Transformer. The team leveraged this information while retaining the representational capabilities of the original architecture.
Body Transformer (BoT) architecture is based on masked attention. At each layer of this architecture, a node can only see information about itself and its immediate neighbors. In this way, information flows according to the structure of the graph, with upstream layers performing inferences based on local information and downstream layers gathering more global information from more distant nodes.
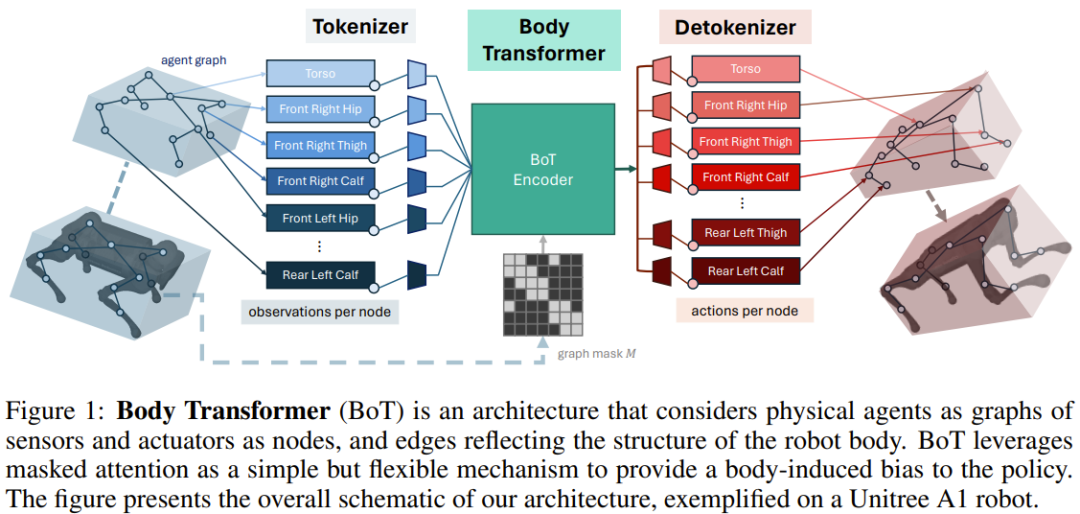
As shown in Figure 1, the BoT architecture contains the following components:
1.tokenizer: projects the sensor input into the corresponding node embedding;
2.Transformer encoder: processes the input embedding and generates output of the same dimension Features;
3.detokenizer: Detokenization, that is, decoding features into actions (or the value used for reinforcement learning criticism training).
tokenizer
The team chose to map observation vectors into graphs composed of local observations.
In practice, they assign global quantities to the root elements of the robot body and local quantities to the nodes representing the corresponding limbs. This allocation is similar to the previous GNN method.
Then, use a linear layer to project the local state vector into an embedding vector. The state of each node is fed into its node-specific learnable linear projection, resulting in a sequence of n embeddings, where n represents the number of nodes (or sequence length). This is different from previous works, which usually only use a single shared learnable linear projection to handle different numbers of nodes in multi-task reinforcement learning.
BoT Encoder
The backbone network used by the team is a standard multi-layer Transformer encoder, and there are two variants of this architecture:
BoT-Hard: Mask each layer using a binary mask that reflects the structure of the graph. Specifically, the way they construct the mask is M = I_n + A, where I_n is the n-dimensional identity matrix and A is the adjacency matrix corresponding to the graph. Figure 2 shows an example. This allows each node to see only itself and its immediate neighbors, and can introduce considerable sparsity to the problem - which is particularly attractive from a computational cost perspective.
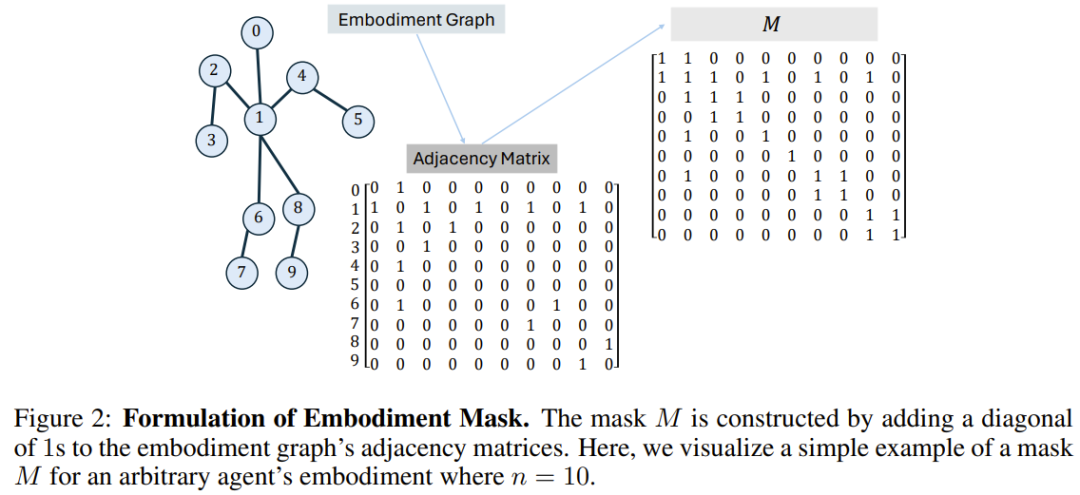
BoT-Mix: interweaves layers with masked attention (like BoT-Hard) with layers with unmasked attention.
detokenizer
Transformer The features output by the encoder are fed to the linear layer and then projected into actions associated with the limb of the node; these actions are assigned based on the proximity of the corresponding actuator to the limb . Again, these learnable linear projection layers are separate for each node. If BoT is used as a critical architecture in a reinforcement learning setting, the detokenizer outputs not actions but values, which are then averaged over body parts.
Experiments
The team evaluated the performance of BoT in imitation learning and reinforcement learning settings. They maintained the same structure as Figure 1, only replacing the BoT encoder with various baseline architectures to determine the effectiveness of the encoder.
The goal of these experiments is to answer the following questions:
Can masked attention improve the performance and generalization ability of imitation learning?
Compared to the original Transformer architecture, can BoT show a positive scaling trend?
Is BoT compatible with reinforcement learning frameworks, and what are some reasonable design choices to maximize performance?
Can BoT strategies be applied to real-world robotic tasks?
What are the computational advantages of masked attention?
Imitation Learning Experiment
The team evaluated the imitation learning performance of the BoT architecture on the body tracking task, which was defined through the MoCapAct dataset.
The results are shown in Figure 3a, and it can be seen that BoT always performs better than the MLP and Transformer baselines. It is worth noting that the advantages of BoT over these architectures will further increase on unseen verification video clips, which proves that body-aware inductive bias can lead to improved generalization capabilities.
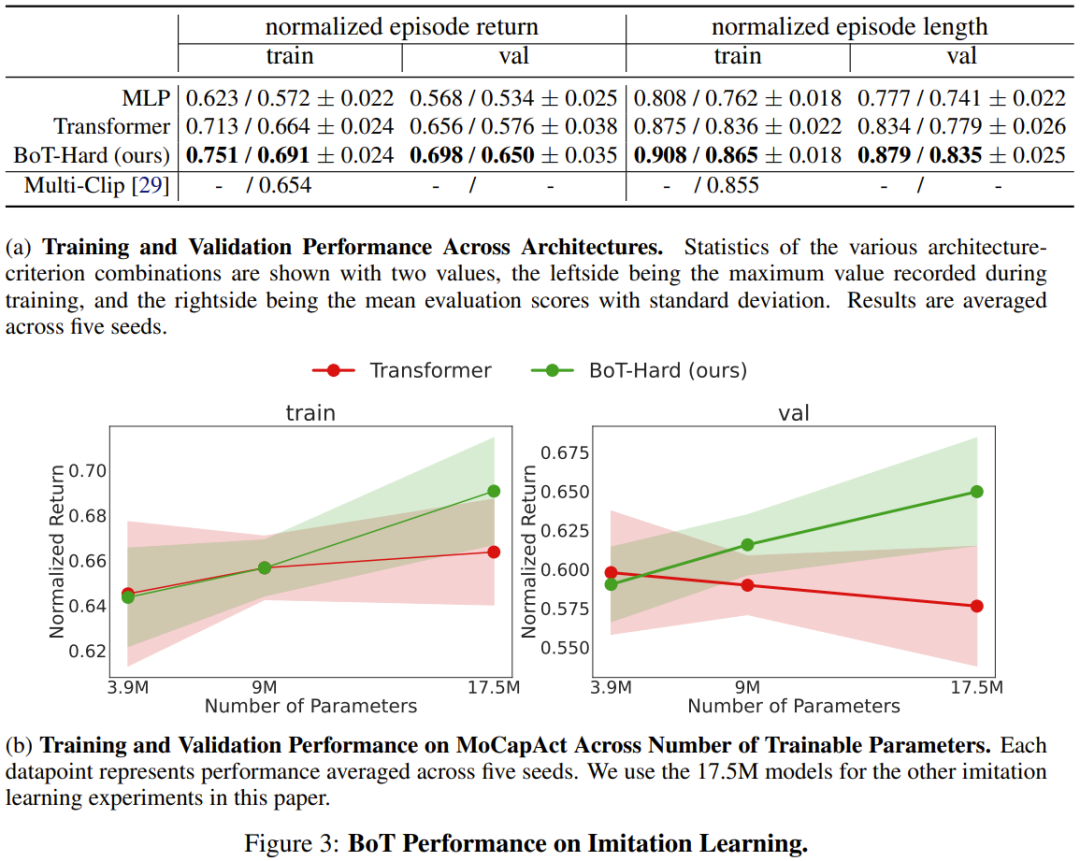
And Figure 3b shows that BoT-Hard has good scalability. Compared with the Transformer baseline, its performance on both training and verification video clips increases as the number of trainable parameters increases, which further shows that BoT-Hard tends to overfit the training data, and this overfitting is caused by embodiment bias. More experimental examples are shown below, see the original paper for details.


Reinforcement Learning Experiment
The team evaluated the reinforcement learning performance of BoT on 4 robot control tasks in Isaac Gym versus a baseline using PPO. The 4 tasks are: Humanoid-Mod, Humanoid-Board, Humanoid-Hill and A1-Walk.
Figure 5 shows the average plot returns of evaluation rollout during training for MLP, Transformer and BoT (Hard and Mix). where the solid line corresponds to the mean and the shaded area corresponds to the standard error of the five seeds.
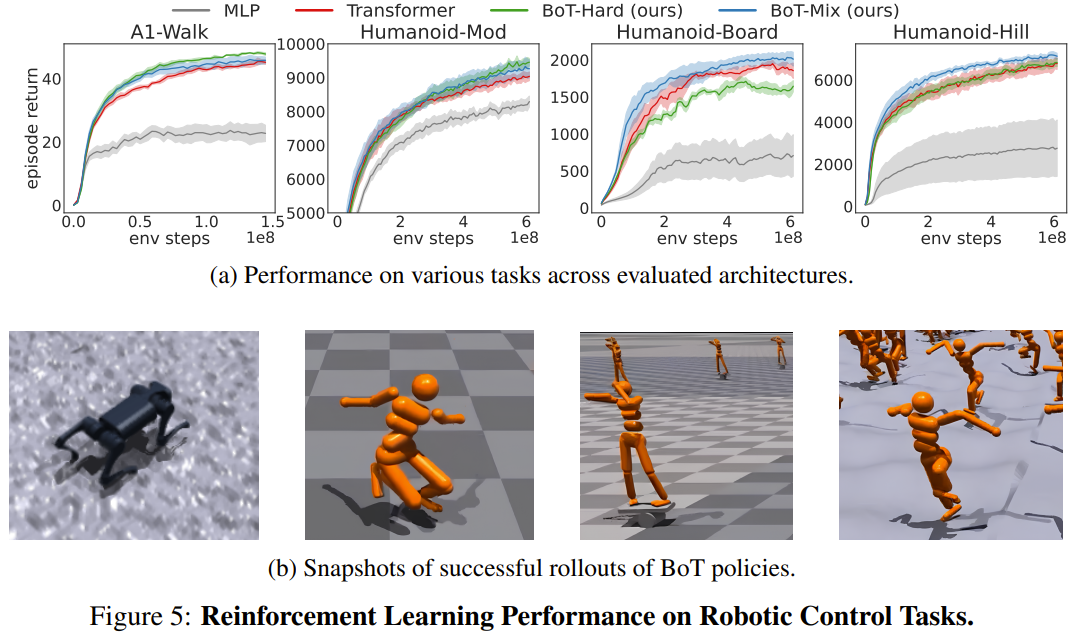

The results show that BoT-Mix consistently outperforms the MLP and original Transformer baselines in terms of sample efficiency and asymptotic performance. This illustrates the usefulness of integrating biases from the robot body into the policy network architecture.
Meanwhile, BoT-Hard performs better than the original Transformer on simpler tasks (A1-Walk and Humanoid-Mod), but performs worse on more difficult exploration tasks (Humanoid-Board and Humanoid-Hill) . Given that masked attention hinders the propagation of information from distant body parts, BoT-Hard's strong limitations in information communication may hinder the efficiency of reinforcement learning exploration.
Real World Experiment
Isaac Gym 模拟的运动环境常被用于将强化学习策略从虚拟迁移到真实环境,并且还不需要在真实世界中进行调整。为了验证新提出的架构是否适用于真实世界应用,该团队将上述训练得到的一个 BoT 策略部署到了一台 Unitree A1 机器人中。从如下视频可以看出,新架构可以可靠地用于真实世界部署。

计算分析
该团队也分析了新架构的计算成本,如图 6 所示。这里给出了新提出的掩码式注意力与常规注意力在不同序列长度(节点数量)上的规模扩展结果。
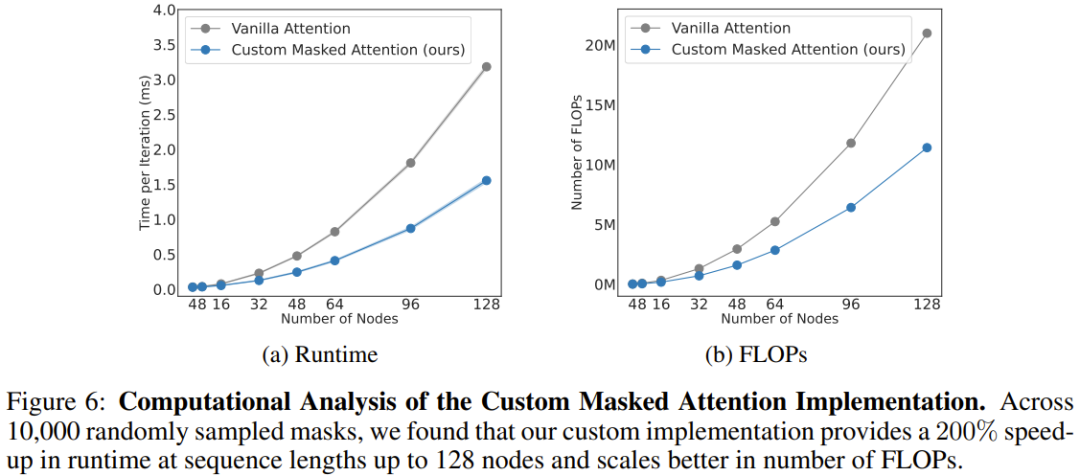
可以看到,当有 128 个节点时(相当于拥有灵巧双臂的类人机器人),新注意力能将速度提升 206%。
总体而言,这表明 BoT 架构中的源自机体的偏置不仅能提高物理智能体的整体性能,而且还可受益于架构那自然稀疏的掩码。该方法可通过充分的并行化来大幅减少学习算法的训练时间。
The above is the detailed content of Game Changer for robot strategy learning? Berkeley proposes Body Transformer. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



