Now, Long Context Visual Language Model (VLM) has a new full-stack solution - LongVILA, which integrates system, model training and data set development.
At this stage, it is very important to combine the multi-modal understanding of the model with the long context capability. The basic model that supports more modalities can accept more flexible input signals so that people can Diverse ways to interact with models. And longer context allows the model to process more information, such as long documents and long videos. This ability also provides the functionality needed for more real-world applications. However, the current problem is that some work has enabled long-context visual language models (VLM), but usually in a simplified approach rather than providing a comprehensive solution. Full-stack design is crucial for long-context visual language models. Training large models is usually a complex and systematic task that requires data engineering and system software co-design. Unlike text-only LLMs, VLMs (e.g., LLaVA) often require unique model architectures and flexible distributed training strategies. In addition, long context modeling requires not only long context data, but also an infrastructure that can support memory-intensive long context training. Therefore, a well-planned full-stack design (covering system, data, and pipeline) is essential for long-context VLM. In this article, researchers from NVIDIA, MIT, UC Berkeley, and the University of Texas at Austin introduce LongVILA, a full-stack solution for training and deploying long-context visual language models, including system design, Model training strategy and data set construction.
- Paper address: https://arxiv.org/pdf/2408.10188
- Code address: https://github.com/NVlabs/VILA/blob/main/LongVILA.md
- Title of the paper: LONGVILA: SCALING LONG-CONTEXT VISUAL LANGUAGE MODELS FOR LONG VIDEOS
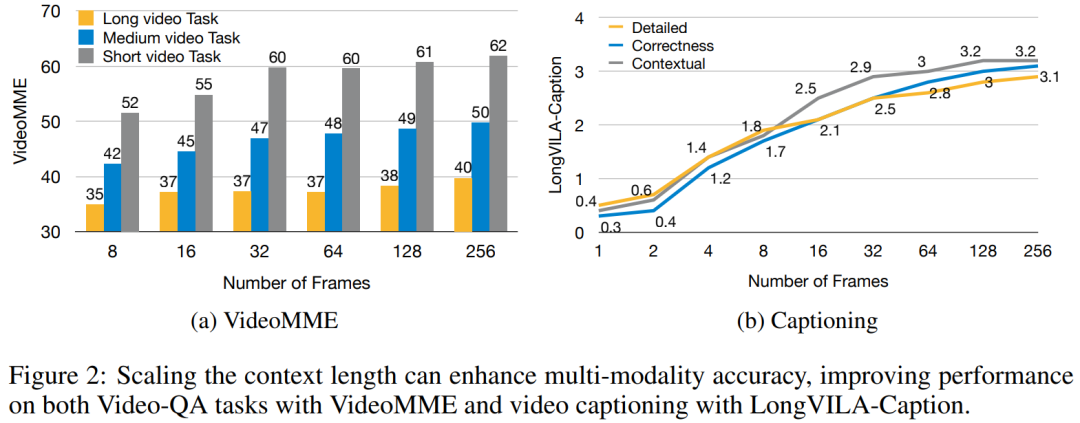
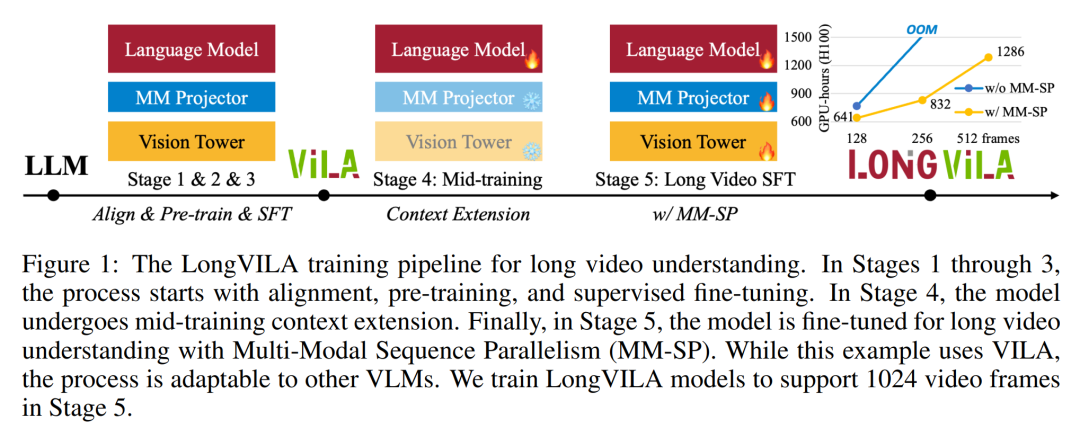
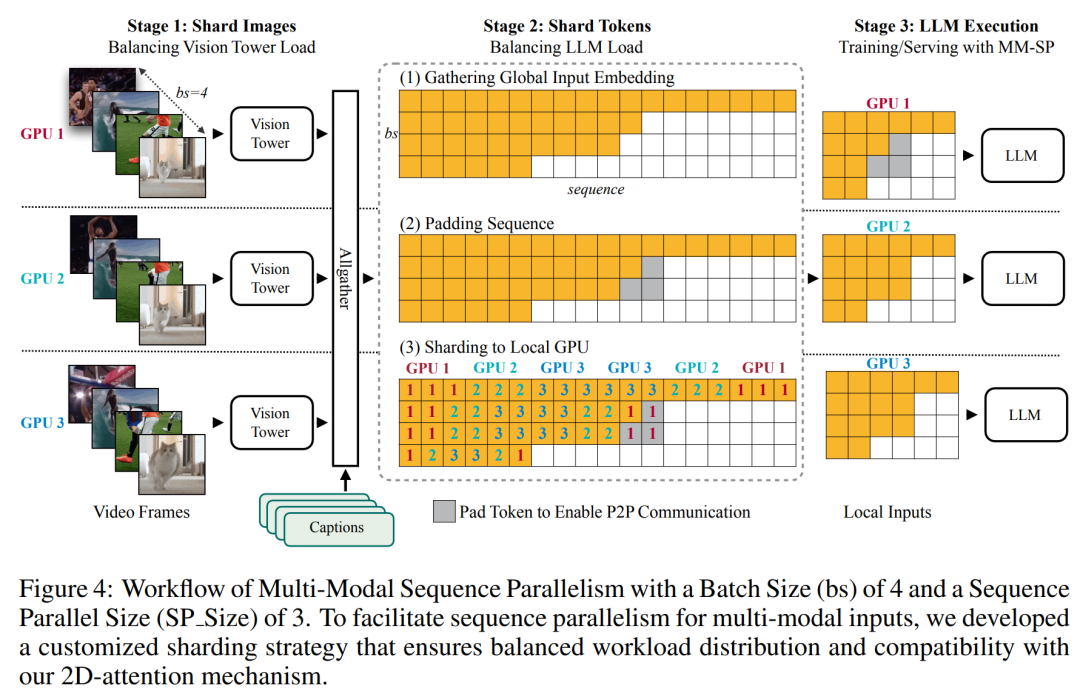
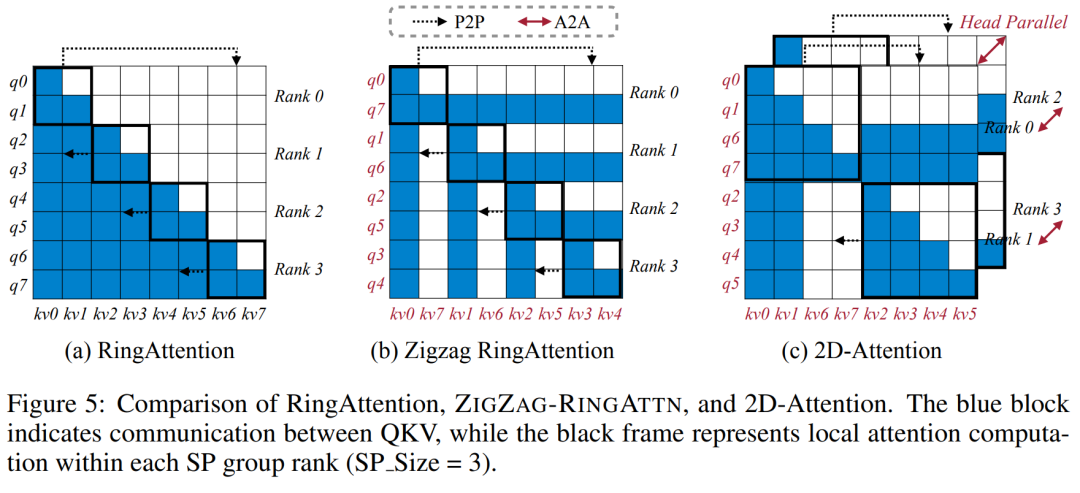
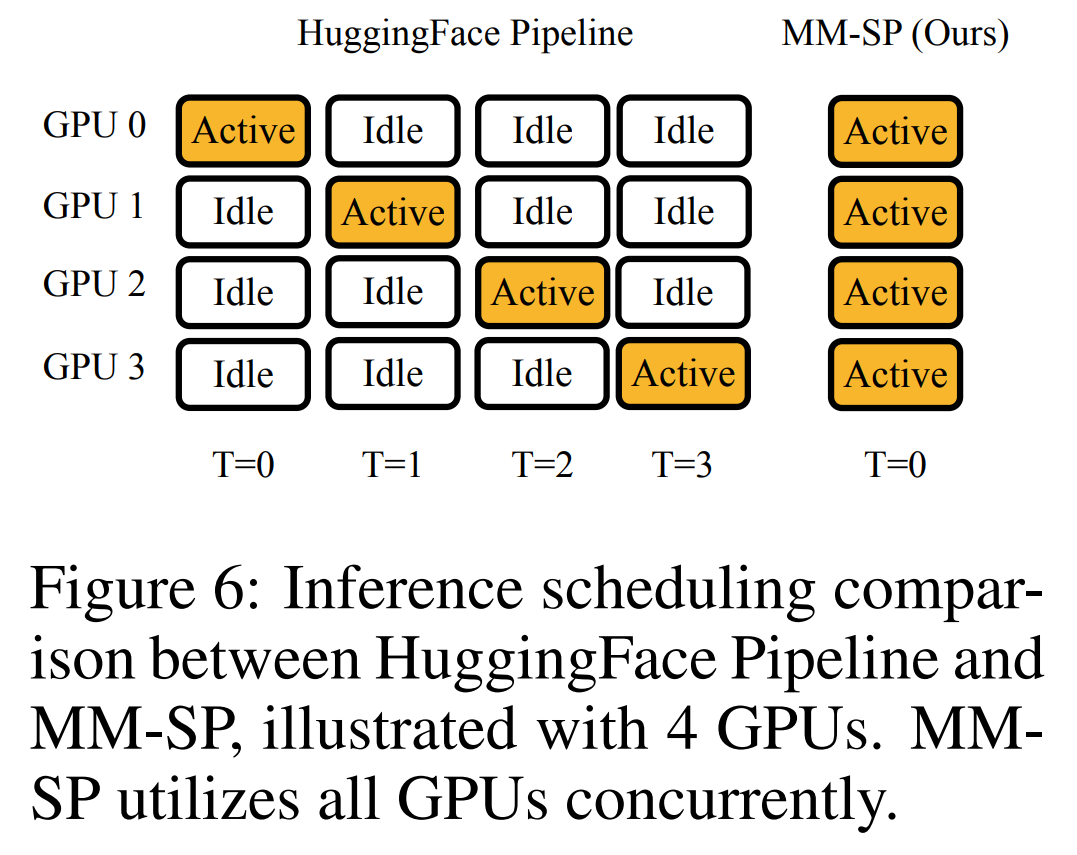
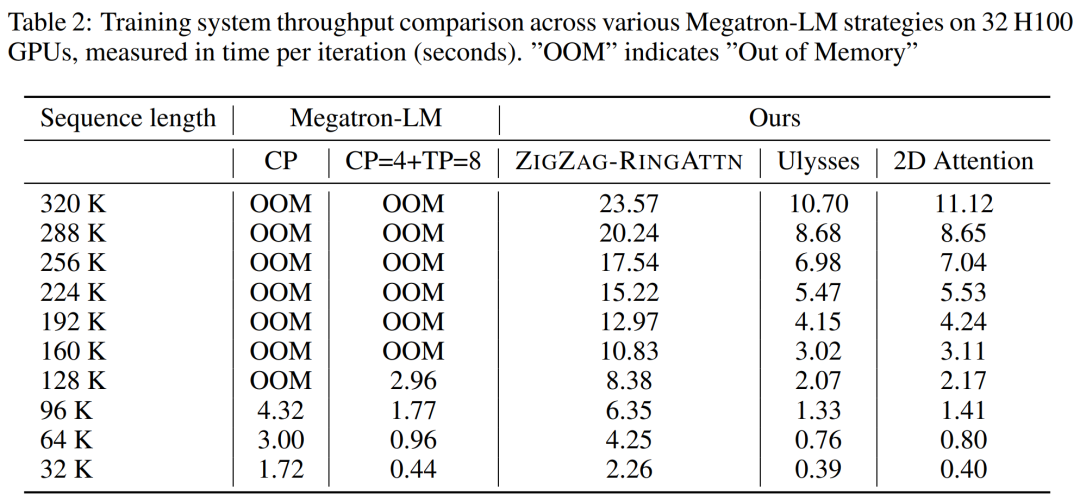
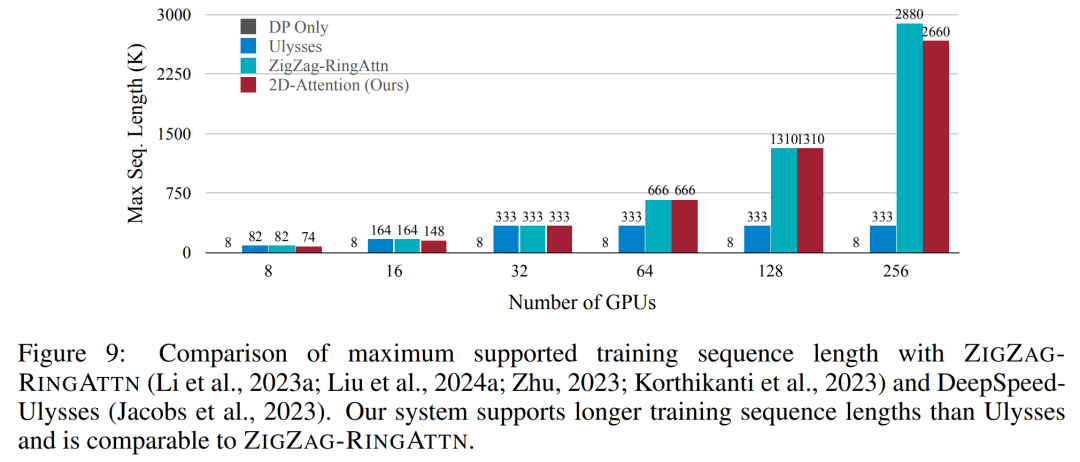
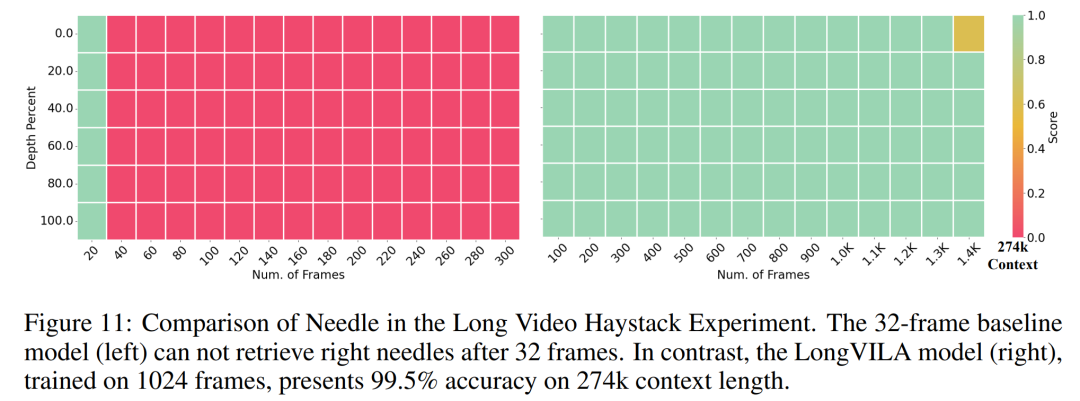
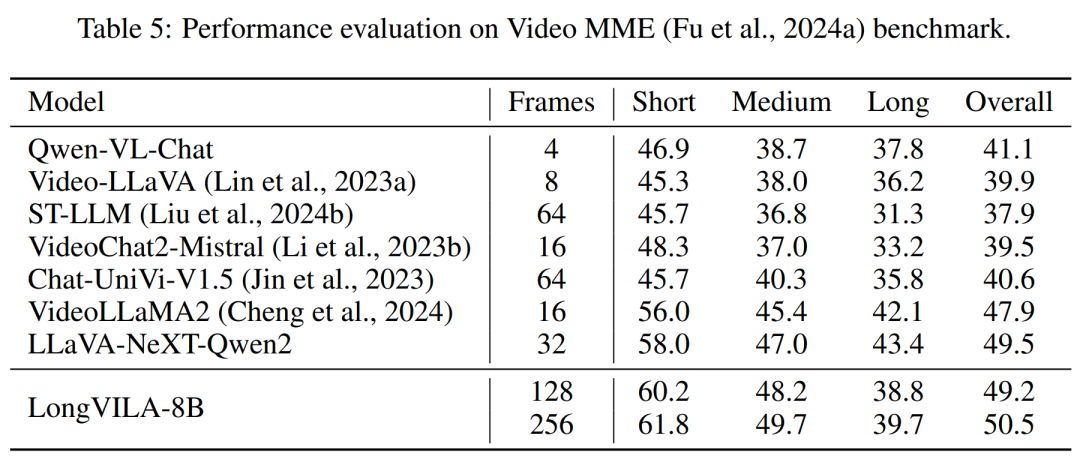
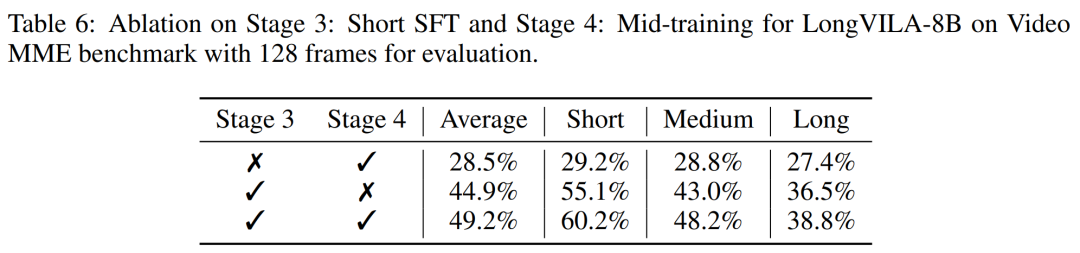
For the training infrastructure, the study established an efficient and user-friendly framework, namely Multimodal Sequence Parallel (MM-SP) ), which supports training memory - dense long context VLM. For the training pipeline, the researchers implemented a five-stage training process, as shown in Figure 1: namely (1) multi-modal alignment, (2) large-scale pre-training, (3) short-supervised fine-tuning, ( 4) contextual extension of LLM, and (5) long-supervised fine-tuning. For inference, MM-SP solves the challenge of KV cache memory usage, which can become a bottleneck when processing very long sequences. By using LongVILA to increase the number of video frames, experimental results show that the performance of this study continues to improve on VideoMME and long video subtitle tasks (Figure 2). The LongVILA model trained on 1024 frames achieved 99.5% accuracy in the needle-in-a-haystack experiment of 1400 frames, equivalent to a context length of 274k tokens. In addition, the MM-SP system can effectively extend the context length to 2 million tokens without gradient checkpoints, achieving 2.1x to 5.7x speedup compared to ring sequence parallelism and Megatron context parallelism+ Tensor parallelism achieves 1.1x to 1.4x speedup compared to Tensor Parallel.  The picture below is an example of LongVILA technology when processing long video subtitles: At the beginning of the subtitles, the 8-frame baseline model only describes a static image and two cars. In comparison, 256 frames of LongVILA depict a car on snow, including front, rear, and side views of the vehicle. In terms of detail, the 256-frame LongVILA also depicts close-ups of the ignition button, gear lever, and instrument cluster, which are missing from the 8-frame baseline model. Multi-modal sequence parallelism Training long-context visual language models (VLM) creates significant memory requirements. For example, in the long video training of Stage 5 in Figure 1 below, a single sequence contains 200K tokens that generate 1024 video frames, which exceeds the memory capacity of a single GPU. Researchers developed a customized system based on sequence parallelism. Sequential parallelism is a technique commonly used in current base model systems to optimize text-only LLM training. However, researchers found that existing systems are neither efficient nor scalable enough to handle long-context VLM workloads.After identifying the limitations of existing systems, the researchers concluded that an ideal multi-modal sequence parallel approach should prioritize efficiency and scalability by addressing modal and network heterogeneity, and Scalability should not be limited by the number of attention heads. MM-SP workflow. To address the challenge of modal heterogeneity, researchers propose a two-stage sharding strategy to optimize the computational workload in the image encoding and language modeling stages. As shown in Figure 4 below, the first stage first evenly distributes images (such as video frames) among devices within the sequential parallel process group to achieve load balancing during the image encoding stage. In the second stage, researchers aggregate global visual and textual inputs for token-level sharding. 2D attention parallelism. In order to solve network heterogeneity and achieve scalability, researchers combine the advantages of Ring sequence parallelism and Ulysses sequence parallelism. Specifically, they regard parallelism across sequence dimensions or attention head dimensions as "1D SP". The method scales through parallel computation across attention heads and sequence dimensions, converting a 1D SP into a 2D grid composed of independent groups of Ring (P2P) and Ulysses (A2A) processes. As shown on the left side of Figure 3 below, in order to achieve 8-degree sequence parallelism across 2 nodes, the researcher used 2D-SP to build a 4×2 communication grid. In addition, in Figure 5 below, to further explain how ZIGZAG-RINGATTN balances calculations and how the 2D-Attention mechanism operates, the researchers explain the attention calculation plan using different methods. Compared with HuggingFace’s native pipeline parallel strategy, the inference mode of this article is more efficient because all devices participate in the calculation at the same time, thereby accelerating the process in proportion to the number of machines, as shown in Figure 6 below. At the same time, this inference mode is scalable, with memory evenly distributed across devices to use more machines to support longer sequences. LongVILA training processAs mentioned above, the training process of LongVILA is completed in 5 stages. The main tasks of each stage are as follows: In Stage 1, only the multi-modal mapper can be trained, and other mappers are frozen. In Stage 2, the researchers froze the visual encoder and trained the LLM and multi-modal mapper. In Stage 3, researchers comprehensively fine-tune the model for short data instruction following tasks, such as using image and short video data sets. In Stage 4, researchers use text-only datasets to extend the context length of LLM in a continuous pre-training manner. In Stage 5, researchers use long video supervision to fine-tune to enhance instruction following ability. It is worth noting that all parameters are trainable in this stage. The researchers evaluated the full-stack solution in this article from two aspects: system and modeling. They first present training and inference results, illustrating the efficiency and scalability of a system that can support long-context training and inference. We then evaluate the performance of the long context model on captioning and instruction following tasks. Training and Inference SystemThis study provides a quantitative evaluation of the throughput of the training system, the latency of the inference system, and the maximum sequence length supported. Table 2 shows the throughput results. Compared with ZIGZAG-RINGATTN, this system achieves an acceleration of 2.1 times to 5.7 times, and the performance is comparable to DeepSpeed-Ulysses. A speedup of 3.1x to 4.3x is achieved compared to the more optimized ring sequence parallel implementation in Megatron-LM CP.この調査では、メモリ不足エラーが発生するまでシーケンス長を 1k から 10k まで徐々に増加させて、固定数の GPU でサポートされる最大シーケンス長を評価します。結果を図 9 にまとめます。 256 GPU にスケールすると、私たちのメソッドはコンテキスト長の約 8 倍をサポートできます。さらに、提案されたシステムは、ZIGZAG-RINGATTN と同様のコンテキスト長スケーリングを実現し、256 個の GPU で 200 万を超えるコンテキスト長をサポートします。 表 3 はサポートされるシーケンスの最大長を比較しており、この研究で提案された方法は HuggingFace Pipeline でサポートされるシーケンスよりも 2.9 倍長いシーケンスをサポートします。 図 11 は、干し草の山の実験における長いビデオ ニードルの結果を示しています。対照的に、LongVILA モデル (右) は、さまざまなフレーム番号と深度にわたってパフォーマンスが向上しています。 表 5 は、ビデオ MME ベンチマークにおけるさまざまなモデルのパフォーマンスをリストし、短い、中程度、長いビデオの長さでの有効性と全体的なパフォーマンスを比較しています。 LongVILA-8B は 256 フレームを使用し、総合スコアは 50.5 です。 研究者らは、表 6 のステージ 3 と 4 の影響に関するアブレーション研究も実施しました。 表 7 は、さまざまなフレーム数 (8、128、256) でトレーニングおよび評価された LongVILA モデルのパフォーマンス メトリクスを示しています。フレーム数が増えると、モデルのパフォーマンスが大幅に向上します。具体的には、平均スコアが 2.00 から 3.26 に増加し、より多くのフレームで正確で豊富な字幕を生成するモデルの能力が強調されました。
The picture below is an example of LongVILA technology when processing long video subtitles: At the beginning of the subtitles, the 8-frame baseline model only describes a static image and two cars. In comparison, 256 frames of LongVILA depict a car on snow, including front, rear, and side views of the vehicle. In terms of detail, the 256-frame LongVILA also depicts close-ups of the ignition button, gear lever, and instrument cluster, which are missing from the 8-frame baseline model. Multi-modal sequence parallelism Training long-context visual language models (VLM) creates significant memory requirements. For example, in the long video training of Stage 5 in Figure 1 below, a single sequence contains 200K tokens that generate 1024 video frames, which exceeds the memory capacity of a single GPU. Researchers developed a customized system based on sequence parallelism. Sequential parallelism is a technique commonly used in current base model systems to optimize text-only LLM training. However, researchers found that existing systems are neither efficient nor scalable enough to handle long-context VLM workloads.After identifying the limitations of existing systems, the researchers concluded that an ideal multi-modal sequence parallel approach should prioritize efficiency and scalability by addressing modal and network heterogeneity, and Scalability should not be limited by the number of attention heads. MM-SP workflow. To address the challenge of modal heterogeneity, researchers propose a two-stage sharding strategy to optimize the computational workload in the image encoding and language modeling stages. As shown in Figure 4 below, the first stage first evenly distributes images (such as video frames) among devices within the sequential parallel process group to achieve load balancing during the image encoding stage. In the second stage, researchers aggregate global visual and textual inputs for token-level sharding. 2D attention parallelism. In order to solve network heterogeneity and achieve scalability, researchers combine the advantages of Ring sequence parallelism and Ulysses sequence parallelism. Specifically, they regard parallelism across sequence dimensions or attention head dimensions as "1D SP". The method scales through parallel computation across attention heads and sequence dimensions, converting a 1D SP into a 2D grid composed of independent groups of Ring (P2P) and Ulysses (A2A) processes. As shown on the left side of Figure 3 below, in order to achieve 8-degree sequence parallelism across 2 nodes, the researcher used 2D-SP to build a 4×2 communication grid. In addition, in Figure 5 below, to further explain how ZIGZAG-RINGATTN balances calculations and how the 2D-Attention mechanism operates, the researchers explain the attention calculation plan using different methods. Compared with HuggingFace’s native pipeline parallel strategy, the inference mode of this article is more efficient because all devices participate in the calculation at the same time, thereby accelerating the process in proportion to the number of machines, as shown in Figure 6 below. At the same time, this inference mode is scalable, with memory evenly distributed across devices to use more machines to support longer sequences. LongVILA training processAs mentioned above, the training process of LongVILA is completed in 5 stages. The main tasks of each stage are as follows: In Stage 1, only the multi-modal mapper can be trained, and other mappers are frozen. In Stage 2, the researchers froze the visual encoder and trained the LLM and multi-modal mapper. In Stage 3, researchers comprehensively fine-tune the model for short data instruction following tasks, such as using image and short video data sets. In Stage 4, researchers use text-only datasets to extend the context length of LLM in a continuous pre-training manner. In Stage 5, researchers use long video supervision to fine-tune to enhance instruction following ability. It is worth noting that all parameters are trainable in this stage. The researchers evaluated the full-stack solution in this article from two aspects: system and modeling. They first present training and inference results, illustrating the efficiency and scalability of a system that can support long-context training and inference. We then evaluate the performance of the long context model on captioning and instruction following tasks. Training and Inference SystemThis study provides a quantitative evaluation of the throughput of the training system, the latency of the inference system, and the maximum sequence length supported. Table 2 shows the throughput results. Compared with ZIGZAG-RINGATTN, this system achieves an acceleration of 2.1 times to 5.7 times, and the performance is comparable to DeepSpeed-Ulysses. A speedup of 3.1x to 4.3x is achieved compared to the more optimized ring sequence parallel implementation in Megatron-LM CP.この調査では、メモリ不足エラーが発生するまでシーケンス長を 1k から 10k まで徐々に増加させて、固定数の GPU でサポートされる最大シーケンス長を評価します。結果を図 9 にまとめます。 256 GPU にスケールすると、私たちのメソッドはコンテキスト長の約 8 倍をサポートできます。さらに、提案されたシステムは、ZIGZAG-RINGATTN と同様のコンテキスト長スケーリングを実現し、256 個の GPU で 200 万を超えるコンテキスト長をサポートします。 表 3 はサポートされるシーケンスの最大長を比較しており、この研究で提案された方法は HuggingFace Pipeline でサポートされるシーケンスよりも 2.9 倍長いシーケンスをサポートします。 図 11 は、干し草の山の実験における長いビデオ ニードルの結果を示しています。対照的に、LongVILA モデル (右) は、さまざまなフレーム番号と深度にわたってパフォーマンスが向上しています。 表 5 は、ビデオ MME ベンチマークにおけるさまざまなモデルのパフォーマンスをリストし、短い、中程度、長いビデオの長さでの有効性と全体的なパフォーマンスを比較しています。 LongVILA-8B は 256 フレームを使用し、総合スコアは 50.5 です。 研究者らは、表 6 のステージ 3 と 4 の影響に関するアブレーション研究も実施しました。 表 7 は、さまざまなフレーム数 (8、128、256) でトレーニングおよび評価された LongVILA モデルのパフォーマンス メトリクスを示しています。フレーム数が増えると、モデルのパフォーマンスが大幅に向上します。具体的には、平均スコアが 2.00 から 3.26 に増加し、より多くのフレームで正確で豊富な字幕を生成するモデルの能力が強調されました。 The above is the detailed content of Supporting 1024 frames and nearly 100% accuracy, NVIDIA 'LongVILA” begins to develop long videos. For more information, please follow other related articles on the PHP Chinese website!






 How to flash Xiaomi phone
How to flash Xiaomi phone
 How to center div in css
How to center div in css
 How to open rar file
How to open rar file
 Methods for reading and writing java dbf files
Methods for reading and writing java dbf files
 How to solve the problem that the msxml6.dll file is missing
How to solve the problem that the msxml6.dll file is missing
 Commonly used permutation and combination formulas
Commonly used permutation and combination formulas
 Virtual mobile phone number to receive verification code
Virtual mobile phone number to receive verification code
 dynamic photo album
dynamic photo album








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



