The AIxiv column is a column where academic and technical content is published on this site. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Unit testing is a key link in the software development process and is mainly used for Verify that the smallest testable unit, function, or module in the software works as expected. The goal of unit testing is to ensure that each independent code fragment can correctly perform its function, which is of great significance for improving software quality and development efficiency. However, large models by themselves are unable to generate high-coverage test sample sets for complex functions under test (cyclocomplexity greater than 10). In order to solve this pain point, Professor Li Ge's team from Peking University proposed a new method to improve test case coverage. This method uses program slicing (Method Slicing) to decompose complex functions under test into several simple fragments based on semantics. Then let the large model generate test cases for each simple fragment separately. When generating a single test case, the large model only needs to analyze a fragment of the original function to be tested, which reduces the difficulty of analysis and the difficulty of generating unit tests that cover this fragment. This promotion can improve the code coverage of the overall test sample set. The related paper "HITS: High-coverage LLM-based Unit Test Generation via Method Slicing" was recently published by ASE 2024 (at the 39th IEEE/ACM International Conference on Automated Software Engineering ) will be accepted. 
Paper address: https://www.arxiv.org/pdf/2408.11324Look next The specific content of the Peking University team’s paper research: HITS uses large models for program shardingProgram sharding refers to dividing a program into several problem-solving stages based on semantics. A program is a formal expression of a solution to a problem. A problem solution usually consists of multiple steps, each step corresponding to a slice of code in the program. As shown in the figure below, a color block corresponds to a piece of code and a step to solve the problem.
HITS requires the large model to design unit test code for each piece of code that can efficiently cover it. Taking the above figure as an example, when we obtain the slices as shown in the figure, HITS requires the large model to generate test samples for Slice 1 (green), Slice 2 (blue), and Slice 3 (red) respectively. The test samples generated for Slice 1 should cover Slice 1 as much as possible, regardless of Slice 2 and Slice 3. The same applies to other code pieces. HITS works for two reasons. First, large models need to consider reducing the amount of code covered. Taking the above figure as an example, when generating test samples for Slice 3, only the conditional branches in Slice 3 need to be considered. To cover some conditional branches in Slice 3, you only need to find an execution path in Slice 1 and Slice 2, without considering the impact of this execution path on the coverage of Slice 1 and Slice 2. Second, code pieces segmented based on semantics (problem-solving steps) help large models grasp the intermediate states of code execution. Generating test cases for later blocks of code requires taking into account changes to the program state caused by previous code. Because code blocks are segmented according to actual problem-solving steps, the operations of previous code blocks can be described in natural language (as shown in the annotation in the figure above). Since most current large language models are the product of mixed training between natural language and programming language, good natural language summarization can help large models more accurately grasp changes in program status caused by code. HITS uses large models for program sharding. The problem-solving steps are usually expressed in natural language with the subjective color of the programmer, so large models with superior natural language processing capabilities can be directly used. Specifically, HITS uses in-context learning to call large models. The team used its past practical experience in real scenarios to manually write several program sharding samples. After several adjustments, the effect of the large model on program sharding met the research team's expectations. Generate test examples for code snippetsGiven the code snippet to be covered , to generate corresponding test samples, you need to go through the following three steps: 1. Analyze the input of the fragment; 2. Construct a prompt to instruct the large model to generate an initial test sample; 3. Use rule post-processing and large model self-debug adjustment Test the sample so that it runs correctly. Analyze the input of the fragment, which means extracting all external input accepted by the fragment to be covered for subsequent prompt use. External input refers to local variables defined by previous fragments to which this fragment is applied, formal parameters of the method under test, methods called within the fragment, and external variables. The value of external input directly determines the execution of the fragment to be covered, so extracting this information to prompt the large model helps to design test cases in a targeted manner. The research team found in experiments that large models have a good ability to extract external inputs, so large models are used to complete this task in HITS. Next, HITS builds a chain-of-thought prompt to guide the large model to generate test samples. The reasoning steps are as follows. The first step is to give the external input and analyze the permutations and combinations of the various conditional branches in the code piece to be covered. What properties do the external inputs need to satisfy? For example: combination 1, string a needs to contain the character 'x', The integer variable i needs to be non-negative; in combination 2, the string a needs to be non-empty, and the integer variable i needs to be a prime number. In the second step, for each combination in the previous step, analyze the nature of the environment in which the corresponding code under test is executed, including but not limited to the characteristics of actual parameters and the settings of global variables. The third step is to generate a test sample for each combination. The research team hand-built examples for each step so that the large model could correctly understand and execute the instructions. Finally, HITS enables test samples generated by large models to run correctly through post-processing and self-debug. Test samples generated by large models are often difficult to use directly, and there will be various compilation errors and runtime errors caused by incorrectly written test samples. The research team designed several rules and common error repair cases based on their own observations and summaries of existing papers. First try to fix according to the rules. If the rule cannot be repaired, use the self-debug function of the large model to repair it. Repair cases of common errors are provided in the prompt for the reference of the large model.
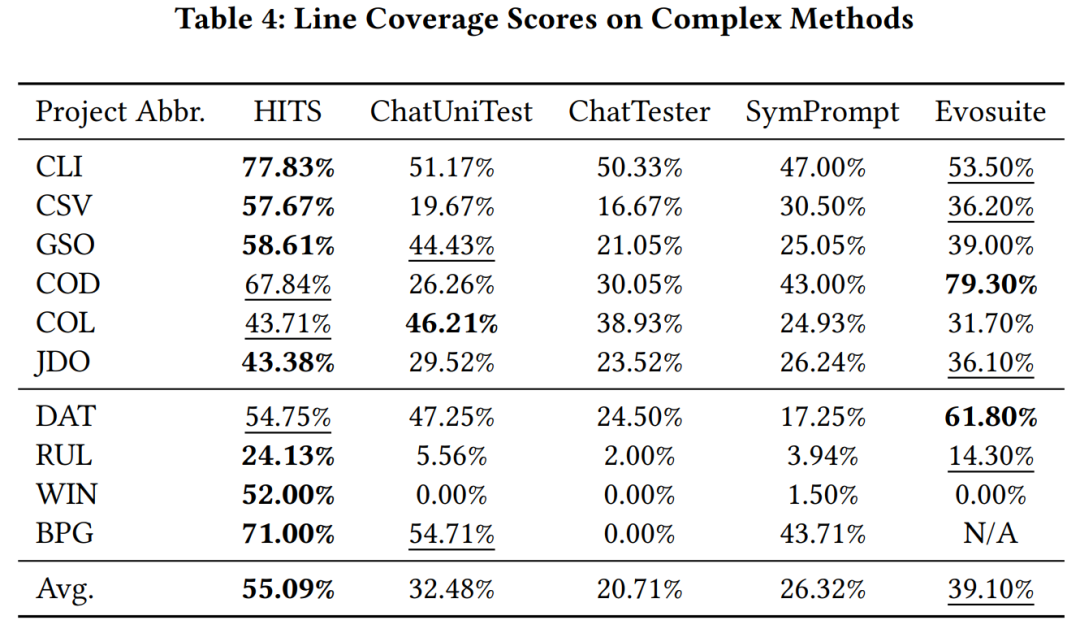
研究チームは、HITS によって呼び出される大規模モデルとして gpt-3.5-turbo を使用し、大規模モデルによって学習された Java プロジェクトとevosuite を使用した他の大規模なモデルベースの単体テスト方法とコード カバレッジは学習されていません。実験結果は、比較した方法と比較して、HITS のパフォーマンスが大幅に向上していることを示しています。
サンプルを分析してコードを改善する方法のスライスメソッドを表示する方法カバレッジ。写真の通り。
この場合、ベースライン メソッドによって生成されたテスト サンプルは、スライス 2 の赤いコード フラグメントを完全にカバーできませんでした。ただし、HITS はスライス 2 に焦点を当てていたため、参照する外部変数を分析し、「赤色のコード フラグメントをカバーしたい場合は、変数 'arguments' が空でない必要がある」という特性を捕捉し、テスト サンプルを構築しました。このプロパティに基づいて、赤色の市外局番のカバレッジを正常に達成しました。
単体テストのカバレッジを改善し、システムの信頼性と安定性を強化し、それによってソフトウェアの品質を向上させます。 HITS はプログラム シャーディング実験を使用して、このテクノロジーがテスト サンプル セット全体のコード カバレッジを大幅に向上させるだけでなく、将来的にはチームが開発エラーを発見して修正するのに役立つことが期待されています。現実のシナリオの実践を早期に開始し、ソフトウェア配信の品質を向上させます。 The above is the detailed content of Peking University Li Ge's team proposed a new method for generating single tests for large models, significantly improving code test coverage.. For more information, please follow other related articles on the PHP Chinese website!
























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



