

First of all we must have Go installed, Instructions to download and install Go.
We create a new folder for the project, move to the directory and execute the following command:
go mod init scraper
? The go mod init command is used to initialize a new Go module in the directory where it is run and creates a go.mod file to track code dependencies. Dependency management
Now let's install Colibri:
go get github.com/gonzxlez/colibri
? Colibri is a Go package that allows us to crawl and extract structured data on the web using a set of rules defined in JSON. Repository
We define the rules that colibri will use to extract the data we need. Documentation
We are going to make an HTTP request to the URL https://pkg.go.dev/search?q=xpath which contains the results of a query for Go packages related to xpath in Go Packages.
Using the development tools included in our web browser, we can inspect the HTML structure of the page. What are the browser development tools?
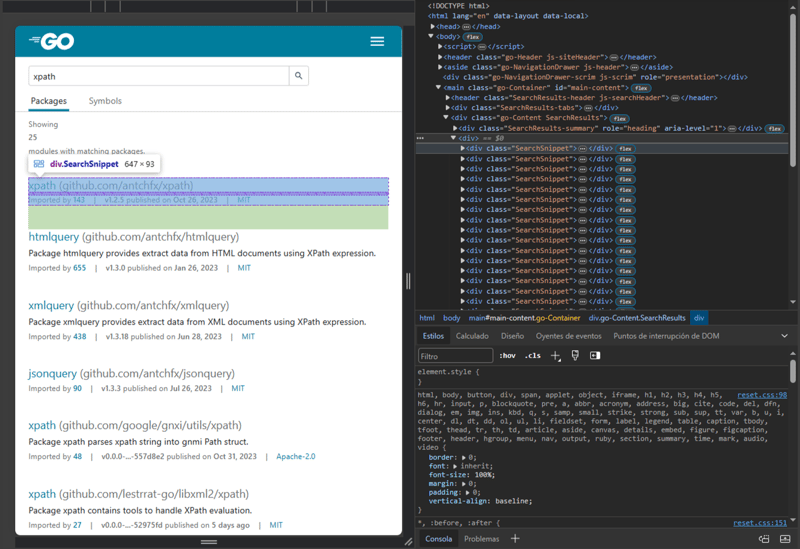
<div class="SearchSnippet">
<div class="SearchSnippet-headerContainer">
<h2>
<a href="/github.com/antchfx/xpath" data-gtmc="search result" data-gtmv="0" data-test-id="snippet-title">
xpath
<span class="SearchSnippet-header-path">(github.com/antchfx/xpath)</span>
</a>
</h2>
</div>
<div class="SearchSnippet-infoLabel">
<a href="/github.com/antchfx/xpath?tab=importedby" aria-label="Go to Imported By">
<span class="go-textSubtle">Imported by </span><strong>143</strong>
</a>
<span class="go-textSubtle">|</span>
<span class="go-textSubtle">
<strong>v1.2.5</strong> published on <span data-test-id="snippet-published"><strong>Oct 26, 2023</strong></span>
</span>
<span class="go-textSubtle">|</span>
<span data-test-id="snippet-license">
<a href="/github.com/antchfx/xpath?tab=licenses" aria-label="Go to Licenses">
MIT
</a>
</span>
</div>
</div>
Fragment of the HTML structure that represents a result of the query.
Then we need a selector “packages” that will find all the div elements in the HTML with the class SearchSnippet, from those elements a selector “name” will take the text of the element a inside an element h2 and a selector “path” will take the value of the href attribute of the a element within an h2 element. . In other words, “name” will take the name of the Go package and “path” the path of the package :)
{
"method": "GET",
"url": "https://pkg.go.dev/search?q=xpath",
"timeout": 10000,
"selectors": {
"packages": {
"expr": "div.SearchSnippet",
"all": true,
"type": "css",
"selectors": {
"name": "//h2/a/text()",
"path": "//h2/a/@href"
}
}
}
}
We are ready to create a scraper.go file, import the necessary packages and define the main function:
package main
import (
"encoding/json"
"fmt"
"github.com/gonzxlez/colibri"
"github.com/gonzxlez/colibri/webextractor"
)
var rawRules = `{
"method": "GET",
"url": "https://pkg.go.dev/search?q=xpath",
"timeout": 10000,
"selectors": {
"packages": {
"expr": "div.SearchSnippet",
"all": true,
"type": "css",
"selectors": {
"name": "//h2/a/text()",
"path": "//h2/a/@href"
}
}
}
}`
func main() {
we, err := webextractor.New()
if err != nil {
panic(err)
}
var rules colibri.Rules
err = json.Unmarshal([]byte(rawRules), &rules)
if err != nil {
panic(err)
}
output, err := we.Extract(&rules)
if err != nil {
panic(err)
}
fmt.Println("URL:", output.Response.URL())
fmt.Println("Status code:", output.Response.StatusCode())
fmt.Println("Content-Type", output.Response.Header().Get("Content-Type"))
fmt.Println("Data:", output.Data)
}
? WebExtractor are default interfaces for Colibri ready to start crawling or extracting data on the web.
Using the New function of webextractor, we generate a Colibri structure with what is necessary to start extracting data.
Then we convert our rules in JSON to a Rules structure and call the Extract method sending the rules as arguments.
We obtain the output and the URL of the HTTP response, the HTTP status code, the content type of the response and the data extracted with the selectors are printed on the screen. See the documentation for the Output structure.
We execute the following command:
go mod tidy
? The go mod tidy command makes sure that the dependencies in the go.mod match the module source code.
Finally we compile and run our code in Go with the command:
go run scraper.go
In this post, we have learned how to perform Web Scraping in Go using the Colibri package, defining extraction rules with CSS and XPath selectors. Colibri emerges as a tool for those looking to automate web data collection in Go. Its rules-based approach and ease of use make it an attractive option for developers of all experience levels.
In short, Web Scraping in Go is a powerful and versatile technique that can be used to extract information from a wide range of websites. It is important to highlight that Web Scraping must be carried out ethically, respecting the terms and conditions of the websites and avoiding overloading their servers.
The above is the detailed content of Web Scraping a Go. For more information, please follow other related articles on the PHP Chinese website!
 How to restart the service in swoole framework
How to restart the service in swoole framework
 The relationship between bandwidth and network speed
The relationship between bandwidth and network speed
 How to switch between Huawei dual systems
How to switch between Huawei dual systems
 Python online playback function implementation method
Python online playback function implementation method
 Remove header line
Remove header line
 What is the difference between a demo machine and a real machine?
What is the difference between a demo machine and a real machine?
 What are the common secondary developments in PHP?
What are the common secondary developments in PHP?
 Introduction to article tag attributes
Introduction to article tag attributes








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



