

As AI continues to shape the way we work and interact with technology, many businesses are looking for ways to leverage their own data within intelligent applications. If you've used tools like ChatGPT or Azure OpenAI, you're already familiar with how generative AI can improve processes and enhance user experiences. However, for truly customized and relevant responses, your applications need to incorporate your proprietary data.
This is where Retrieval-Augmented Generation (RAG) comes in, providing a structured approach to integrating data retrieval with AI-powered responses. With frameworks like LlamaIndex, you can easily build this capability into your solutions, unlocking the full potential of your business data.
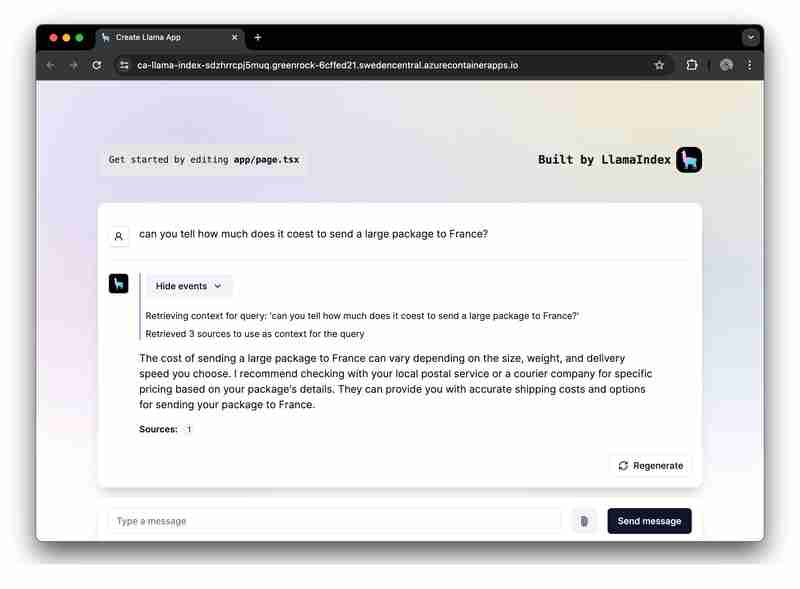
Want to quickly run and explore the app? Click here.
Retrieval-Augmented Generation (RAG) is a neural network framework that enhances AI text generation by including a retrieval component to access relevant information and integrate your own data. It consists of two main parts:
The retriever finds relevant documents, and the generator uses them to create more accurate and informative responses. This combination allows the RAG model to leverage external knowledge effectively, improving the quality and relevance of the generated text.
To implement a RAG system using LlamaIndex, follow these general steps:
For a practical example, we have provided a sample application to demonstrate a complete RAG implementation using Azure OpenAI.
We'll now focus on building a RAG application using LlamaIndex.ts (the TypeScipt implementation of LlamaIndex) and Azure OpenAI, and deploy on it as a serverless Web Apps on Azure Container Apps.
You will find the getting started project on GitHub. We recommend you to fork this template so you can freely edit it when needed:

The getting started project application is built based on the following architecture:

デプロイされるリソースの詳細については、すべてのサンプルで利用可能な infra フォルダーを確認してください。
サンプル アプリケーションには、2 つのワークフローのロジックが含まれています。
データ取り込み: データがフェッチされ、ベクトル化され、検索インデックスが作成されます。 PDF や Word ファイルなどのファイルをさらに追加したい場合は、ここに追加する必要があります。
npm run generate
プロンプト リクエストの処理: アプリはユーザー プロンプトを受信し、Azure OpenAI に送信し、ベクトル インデックスを取得者として使用してこれらのプロンプトを拡張します。
サンプルを実行する前に、必要な Azure リソースがプロビジョニングされていることを確認してください。
GitHub コードスペースで GitHub テンプレートを実行するには、
をクリックするだけです
Codespaces インスタンスで、ターミナルから Azure アカウントにサインインします。
azd auth login
単一のコマンドを使用して、サンプル アプリケーションをプロビジョニング、パッケージ化し、Azure にデプロイします。
azd up
アプリケーションをローカルで実行して試すには、npm の依存関係をインストールしてアプリを実行します。
npm install npm run dev
アプリは、Codespaces インスタンスのポート 3000、またはブラウザの http://localhost:3000 で実行されます。
このガイドでは、LlamaIndex.ts と Azure OpenAI を使用して、Microsoft Azure にデプロイされたサーバーレス RAG (Retrieval-Augmented Generation) アプリケーションを構築する方法を説明しました。このガイドに従うことで、Azure のインフラストラクチャと LlamaIndex の機能を活用して、データに基づいてコンテキストに応じて強化された応答を提供する強力な AI アプリケーションを作成できます。
この入門用アプリケーションで皆さんが何を構築するか楽しみにしています。最新のアップデートや機能を受け取るには、お気軽にフォークして GitHub リポジトリに「いいね!」してください。
The above is the detailed content of Building a RAG app with LlamaIndex.ts and Azure OpenAI: Getting started!. For more information, please follow other related articles on the PHP Chinese website!
 What drawing software are there?
What drawing software are there?
 Recommended order for learning c++ and c language
Recommended order for learning c++ and c language
 How to withdraw money on WeChat without handling fees
How to withdraw money on WeChat without handling fees
 The performance of microcomputers mainly depends on
The performance of microcomputers mainly depends on
 How to use jsp programming software
How to use jsp programming software
 The Metaverse recognizes the top ten potential coins
The Metaverse recognizes the top ten potential coins
 How to delete a folder in linux
How to delete a folder in linux
 What to do if 302 found
What to do if 302 found
 what is ed
what is ed








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



