

Présentation
La pratique rend parfait.
Quelque chose qui a beaucoup en commun avec le fait d'être un data scientist. La théorie n’est qu’un aspect de l’équation ; l’aspect le plus crucial est de mettre la théorie en pratique. Je ferai l'effort d'enregistrer l'ensemble du processus actuel de développement de mon projet de synthèse, qui impliquera l'étude d'un ensemble de données cinématographiques.
Voici les objectifs :
Objectif :
1. Collecte de données
J'ai décidé d'utiliser Kaggle pour trouver mon ensemble de données. Il est essentiel de garder à l'esprit les variables cruciales que vous souhaiterez pour l'ensemble de données avec lequel vous travaillez. Il est important de noter que mon ensemble de données doit inclure les éléments suivants : les tendances de l'année de sortie, la popularité des réalisateurs, les audiences et les genres de films. Par conséquent, je dois m'assurer que l'ensemble de données que je choisis contient au minimum les éléments suivants.
Mon ensemble de données se trouvait sur Kaggle et je fournirai le lien ci-dessous. Vous pouvez obtenir la version CSV du fichier en téléchargeant l'ensemble de données, en le décompressant et en l'extrayant. Vous pouvez le consulter pour comprendre ce que vous avez déjà et vraiment comprendre quels types d'informations vous espérez obtenir à partir des données que vous examinerez.
2. Décrire les données
Tout d'abord, nous devons importer les bibliothèques requises et charger les données nécessaires. J'utilise le langage de programmation Python et Jupyter Notebooks pour mon projet afin de pouvoir écrire et voir mon code plus efficacement.
Vous importerez les bibliothèques que nous utiliserons et chargerez les données comme indiqué ci-dessous.
Nous exécuterons ensuite la commande suivante pour obtenir plus de détails sur notre ensemble de données.
data.head() # dispalys the first rows of the dataset. data.tail() # displays the last rows of the dataset. data.shape # Shows the total number of rows and columns. len(data.columns) # Shows the total number of columns. data.columns # Describes different column names. data.dtypes # Describes different data types.
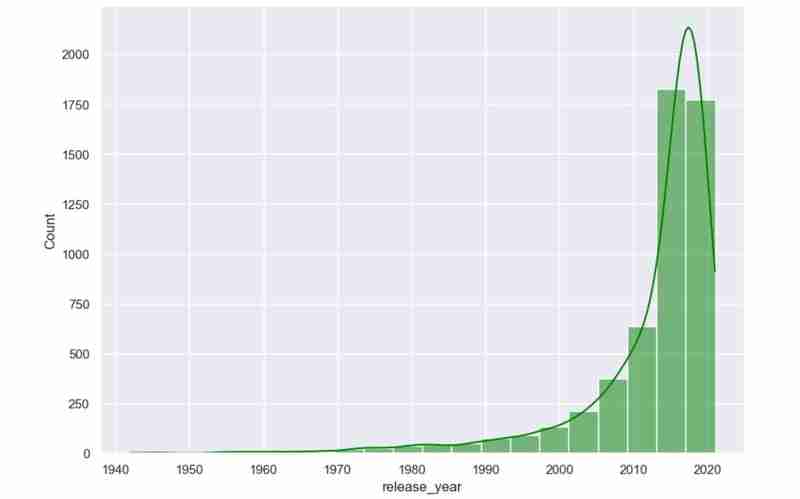
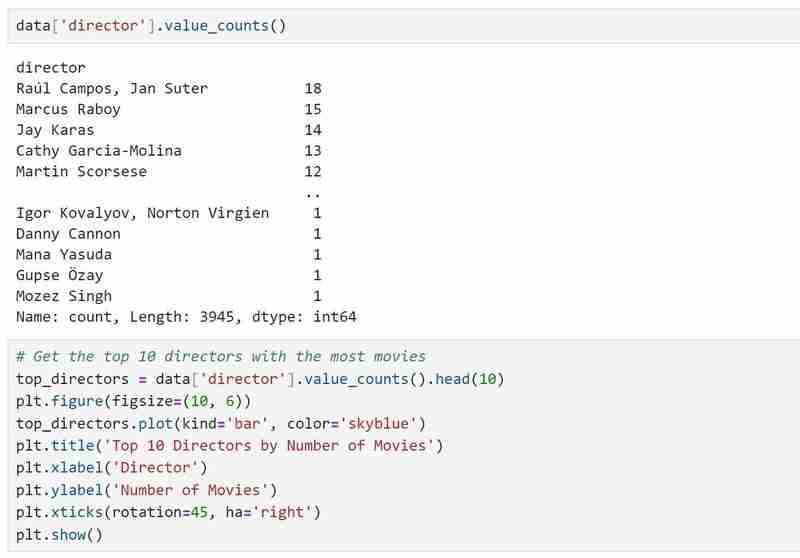
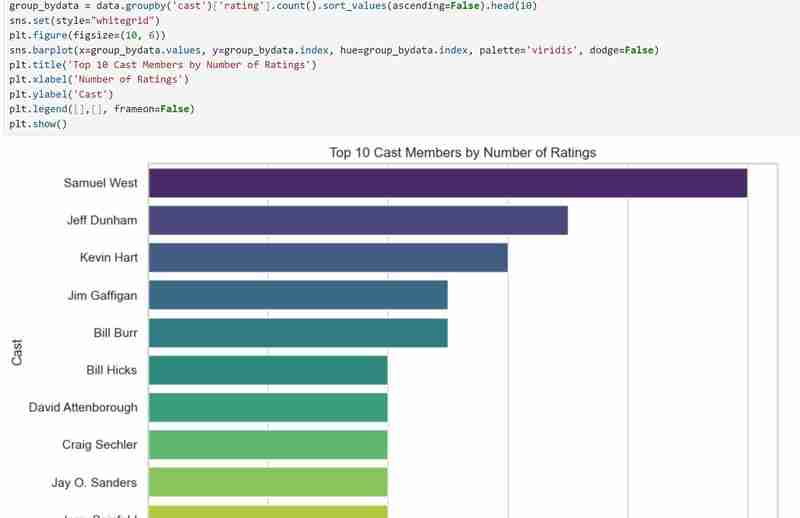
Nous savons maintenant ce que comprend l'ensemble de données et les informations que nous espérons extraire après avoir obtenu toutes les descriptions dont nous avons besoin. Exemple : à l'aide de mon ensemble de données, je souhaite étudier les modèles de popularité des réalisateurs, de répartition des audiences et des genres de films. Je souhaite également suggérer des films en fonction des préférences sélectionnées par l'utilisateur, telles que les réalisateurs et les genres préférés.
3. Nettoyage des données
Cette phase consiste à rechercher toutes les valeurs nulles et à les supprimer. Afin de passer à la visualisation des données, nous examinerons également notre ensemble de données pour détecter les doublons et supprimerons ceux que nous trouverons. Pour ce faire, nous allons exécuter le code qui suit :
1. data['show_id'].value_counts().sum() # Checks for the total number of rows in my dataset 2. data.isna().sum() # Checks for null values(I found null values in director, cast and country columns) 3. data[['director', 'cast', 'country']] = data[['director', 'cast', 'country']].replace(np.nan, "Unknown ") # Fill null values with unknown.
Nous supprimerons ensuite les lignes avec des valeurs inconnues et confirmerons que nous les avons toutes supprimées. Nous vérifierons également le nombre de lignes restantes qui ont nettoyé les données.
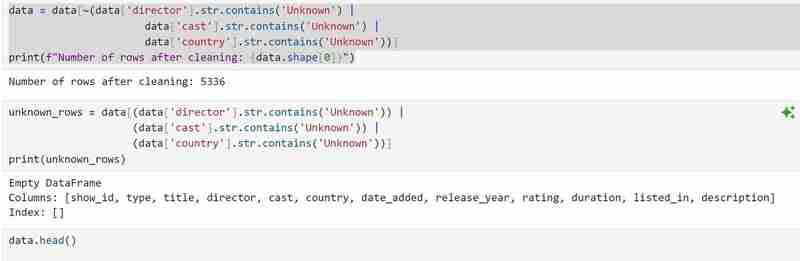
Le code qui suit recherche les caractéristiques uniques et les doublons. Bien qu'il n'y ait pas de doublons dans mon ensemble de données, vous devrez peut-être quand même l'utiliser au cas où de futurs ensembles de données le feraient.
data.duplicated().sum() # Checks for duplicates data.nunique() # Checks for unique features data.info # Confirms if nan values are present and also shows datatypes.
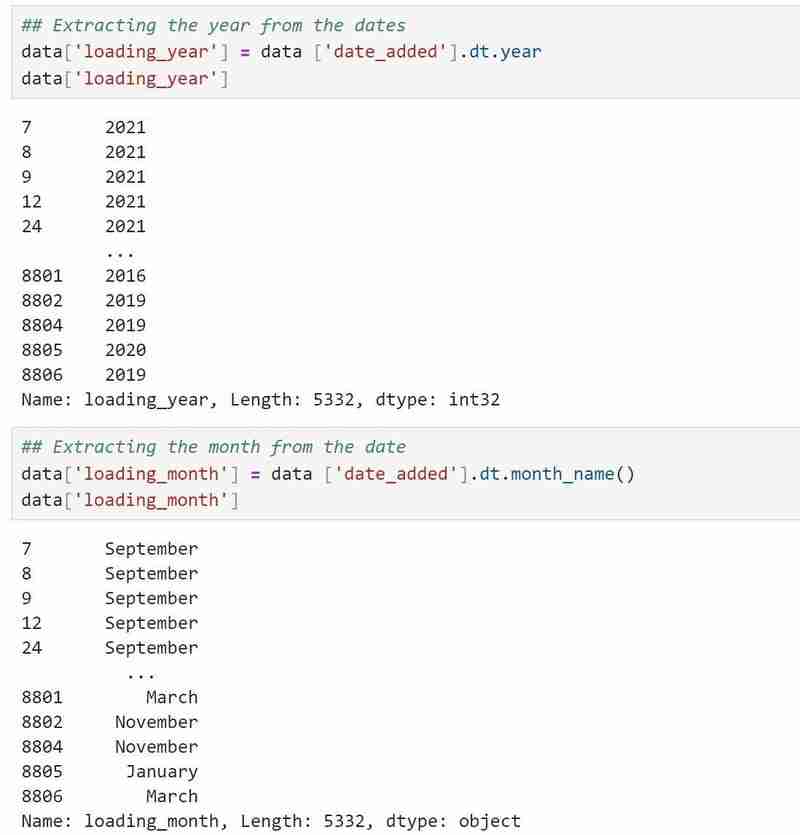
Mon type de données date/heure est un objet et j'aimerais qu'il soit au format date/heure approprié, j'ai donc utilisé
data['date_added']=data['date_added'].astype('datetime64[ms]')pour le convertir au format approprié.
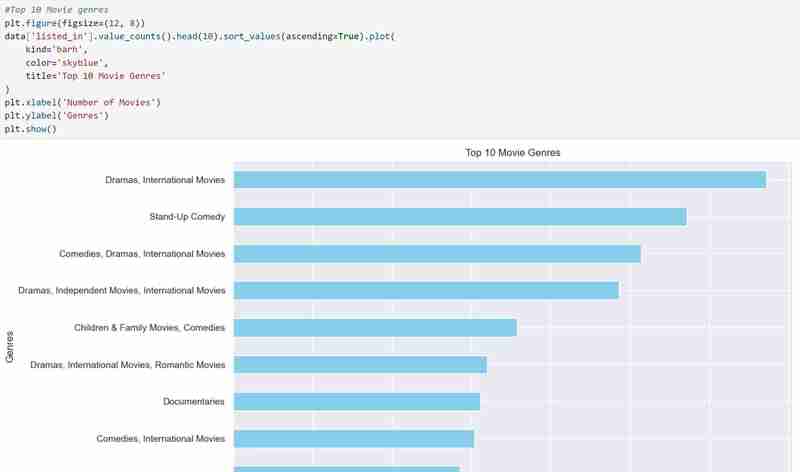
4. Visualisation des données
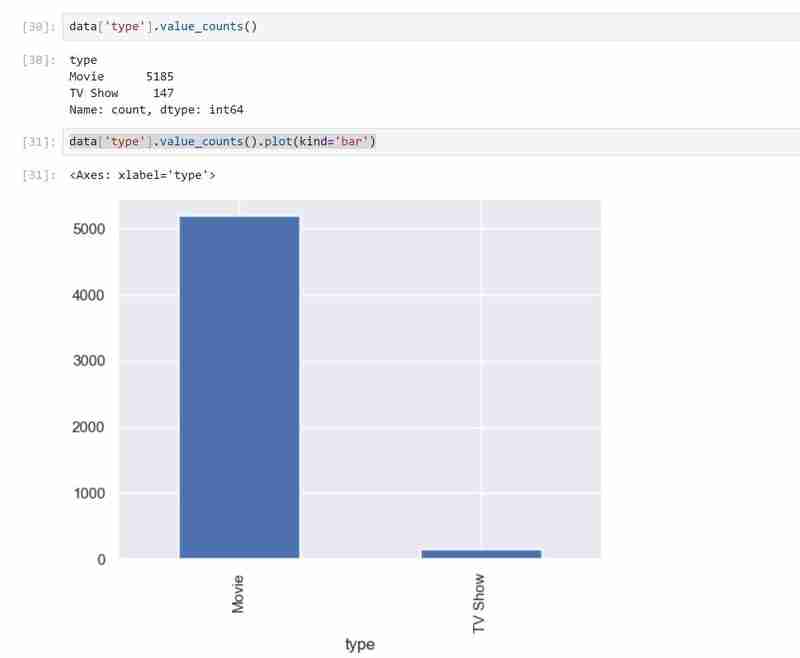
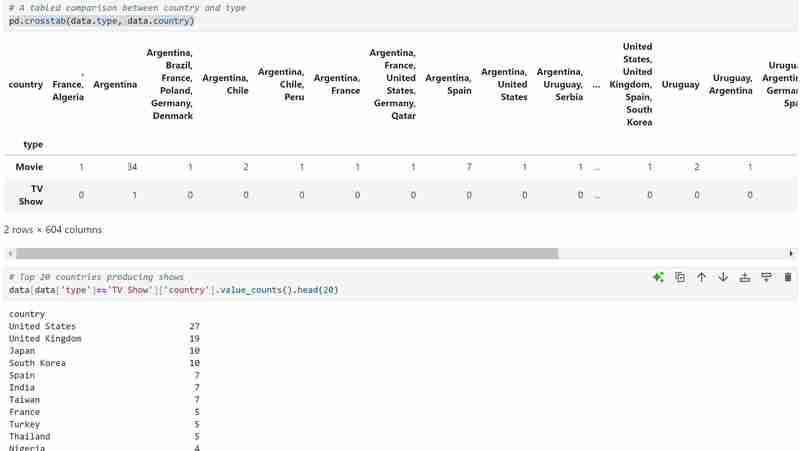
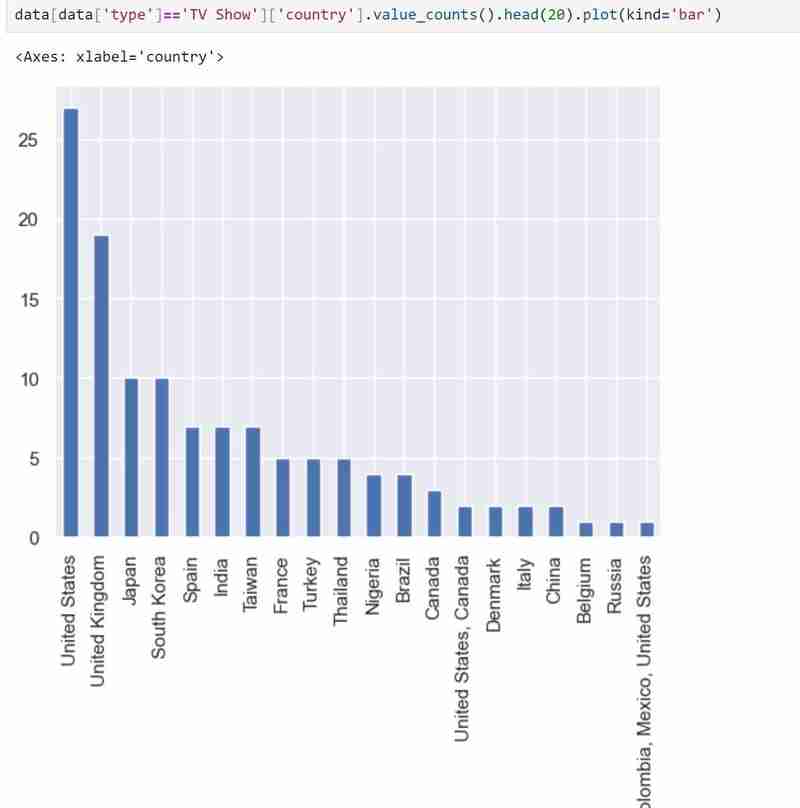
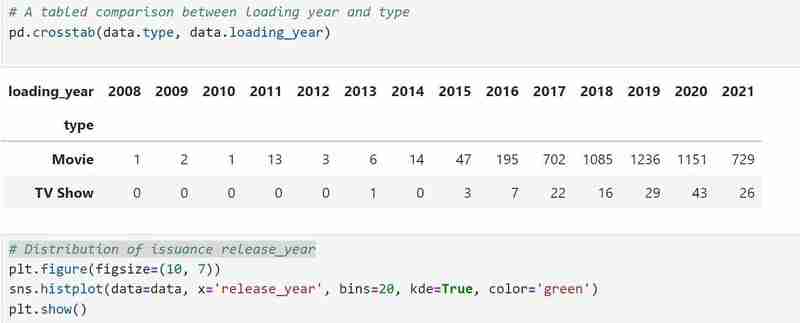
Mon ensemble de données comporte deux types de variables, à savoir les émissions de télévision et les films dans les types et j'ai utilisé un graphique à barres pour présenter les données catégorielles avec les valeurs qu'elles représentent.
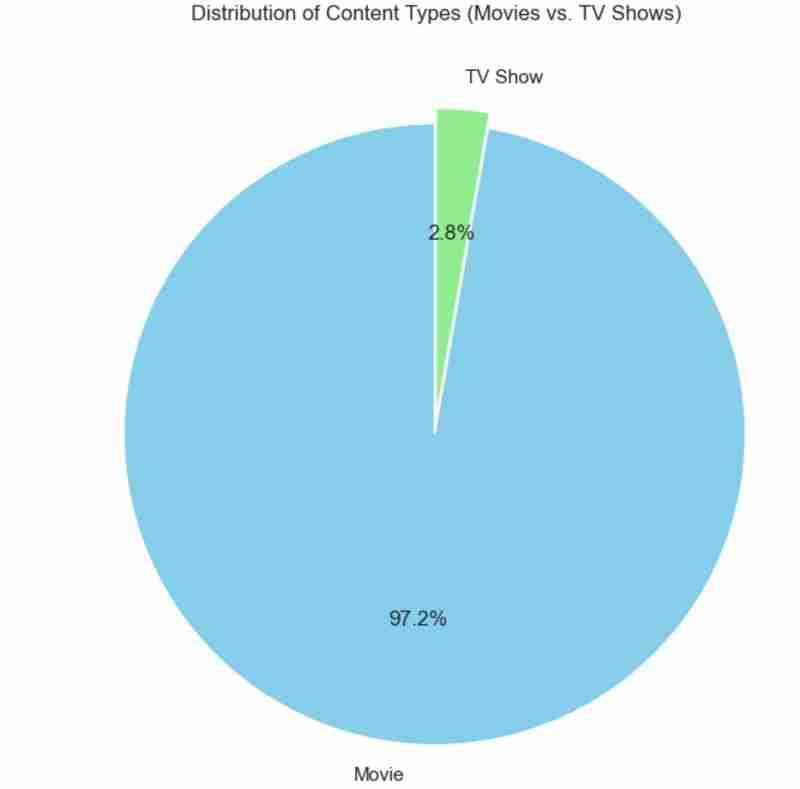
J'ai également utilisé un diagramme circulaire pour représenter la même chose que ci-dessus. Le code utilisé est le suivant et le résultat attendu ci-dessous.
## Pie chart display
plt.figure(figsize=(8, 8))
data['type'].value_counts().plot(
kind='pie',
autopct='%1.1f%%',
colors=['skyblue', 'lightgreen'],
startangle=90,
explode=(0.05, 0)
)
plt.title('Distribution of Content Types (Movies vs. TV Shows)')
plt.ylabel('')
plt.show()
5. Recommendation System
I then built a recommendation system that takes in genre or director's name as input and produces a list of movies as per the user's preference. If the input cannot be matched by the algorithm then the user is notified.

The code for the above is as follows:
def recommend_movies(genre=None, director=None):
recommendations = data
if genre:
recommendations = recommendations[recommendations['listed_in'].str.contains(genre, case=False, na=False)]
if director:
recommendations = recommendations[recommendations['director'].str.contains(director, case=False, na=False)]
if not recommendations.empty:
return recommendations[['title', 'director', 'listed_in', 'release_year', 'rating']].head(10)
else:
return "No movies found matching your preferences."
print("Welcome to the Movie Recommendation System!")
print("You can filter movies by Genre or Director (or both).")
user_genre = input("Enter your preferred genre (or press Enter to skip): ")
user_director = input("Enter your preferred director (or press Enter to skip): ")
recommendations = recommend_movies(genre=user_genre, director=user_director)
print("\nRecommended Movies:")
print(recommendations)
Conclusion
My goals were achieved, and I had a great time taking on this challenge since it helped me realize that, even though learning is a process, there are days when I succeed and fail. This was definitely a success. Here, we celebrate victories as well as defeats since, in the end, each teach us something. Do let me know if you attempt this.
Till next time!
Note!!
The code is in my GitHub:
https://github.com/MichelleNjeri-scientist/Movie-Dataset-Exploration-and-Visualization
The Kaggle dataset is:
https://www.kaggle.com/datasets/shivamb/netflix-shows
The above is the detailed content of Movie Dataset Exploration and Visualization. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



