

In this guide, I'll show you how to use Hugging Face models as an API, with Meta LLaMA-3.2-3B-Instruct as an example. This model is designed for chat-based autocompletion and can handle conversational AI tasks effectively. Let's set up the API and get started!
To access Hugging Face’s model APIs, you need an API token.
Create a Read token by selecting New Token. This allows you to call the API for inference without permissions to modify or manage resources.
Save your token securely, as you’ll need it for API authentication.


Hugging Face provides a serverless Inference API to access pre-trained models. This service is available with rate limits for free users, and enhanced quotas for Pro accounts.
On the Meta LLaMA-3.2-3B-Instruct model page, click on the Inference API tab. This tab provides code examples and additional API usage information.
You can find sample code to get started. Here’s how to set up a basic Python script to call the model’s API.

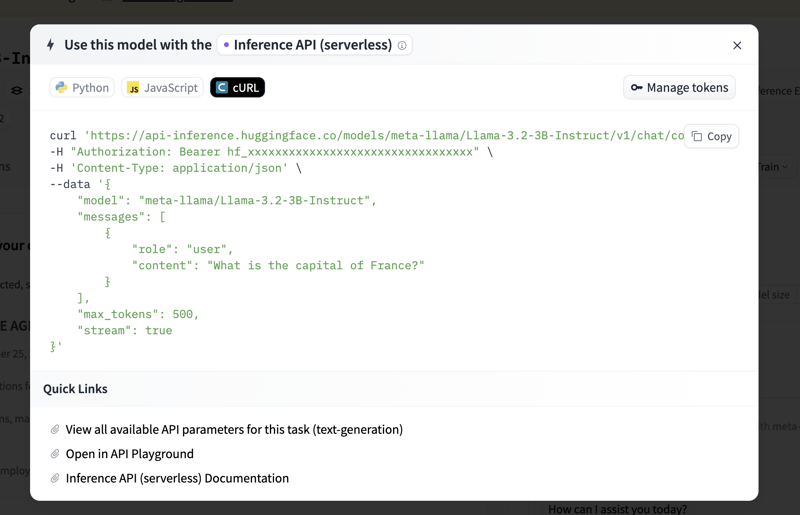
For free accounts, the API rate limit applies, and exceeding this may result in throttled requests. If you plan to use the API extensively or require faster responses, consider a Pro account. More details are available on Hugging Face’s pricing page.
By following these steps, you can use Meta LLaMA-3.2-3B-Instruct or any other Hugging Face model via API for tasks like chat autocompletion, conversational AI, and more. This setup is highly flexible and allows you to integrate AI capabilities directly into your applications, whether for experimental or production purposes.
Now you’re ready to explore and build with Hugging Face’s powerful models!
The above is the detailed content of How to Use Hugging Face AI Models as an API. For more information, please follow other related articles on the PHP Chinese website!
 How to light up Douyin close friends moment
How to light up Douyin close friends moment
 microsoft project
microsoft project
 What is phased array radar
What is phased array radar
 How to use fusioncharts.js
How to use fusioncharts.js
 Yiou trading software download
Yiou trading software download
 The latest ranking of the top ten exchanges in the currency circle
The latest ranking of the top ten exchanges in the currency circle
 What to do if win8wifi connection is not available
What to do if win8wifi connection is not available
 How to recover files emptied from Recycle Bin
How to recover files emptied from Recycle Bin








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



