

Prior to each feature release, I do User Acceptance Testing ("UAT") to surface bugs and ensure the business logic is correctly translated to code.
I only clear a feature for release after UAT is 100% successful.
My reasoning is simple: you only get one chance to make a good first impression to your end user, and a poor release makes it doubly hard to do so.

Although this is an MVP feature that isn't meant for production release, I thought it'd be good to do some UAT to keep my skills fresh.
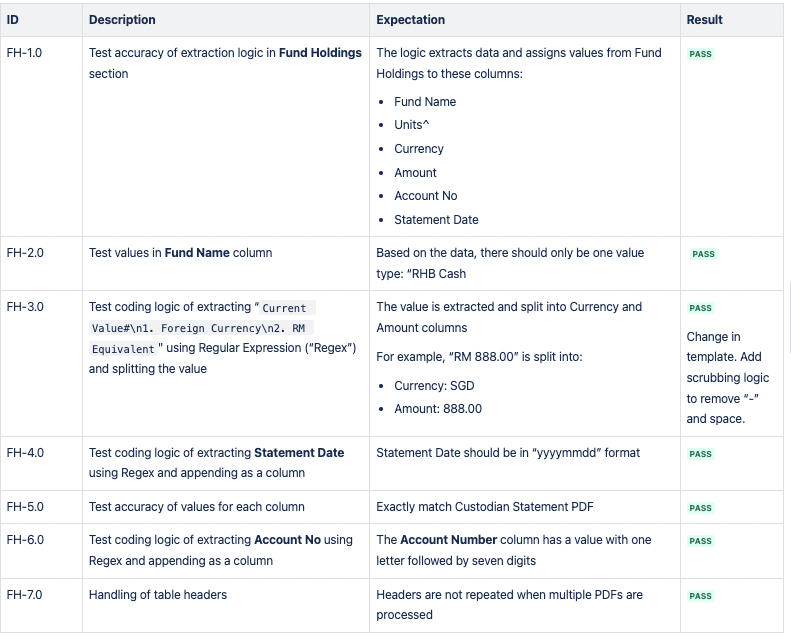
Of the 19 UAT scenarios I came up with, one failed because of a change in the Custodian Statement PDF template.
I anticipated this risk during Discovery, but truth be told, I did not expect the issue to crop up so soon.
I will go into the bug fix details later in the article.
My UAT process involves using the business logic or feature requirements as a reference to create test scenarios and expected outcomes.
Test scenarios don't need to be complicated. They can be as simple as : "The feature generates a CSV file within 30 seconds".
For the UAT, I processed 71 pages of documents from 10 Custodian Statement PDFs. This should be a sufficiently large enough sample set.
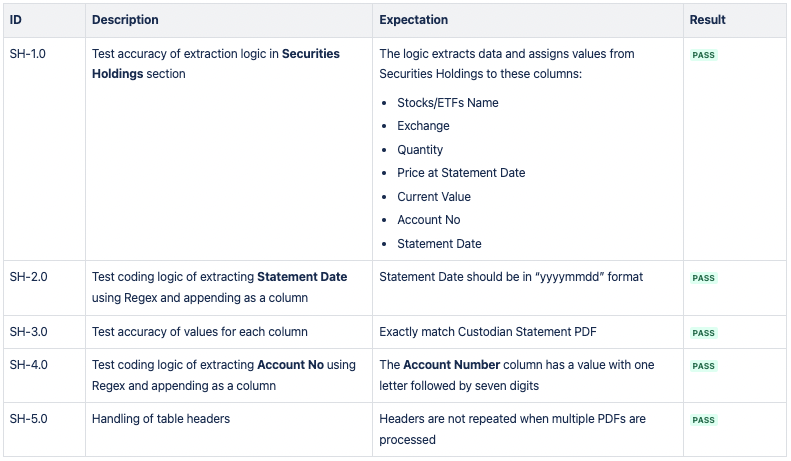
The expected output is three CSV files containing specific datapoints from the Fund Holdings, Securities Holdings and Cash Holdings sections of the Custodian Statement PDF.
I came up with the following test cases:
CSV 1: Fund Holdings
CSV 2: Securities Holdings
CSV 3: Cash Holdings

The one failed test was because the Custodian Statement PDF's template changed slightly in November. More specifically, the values in the "Current Value# 1. Foreign Currency 2. RM Equivalent" column of a Fund Holdings table now has an extra "-n" prefix.
For example, instead of reading "USD 10,000" in previous PDFs, the value now reads "- USD10,000".
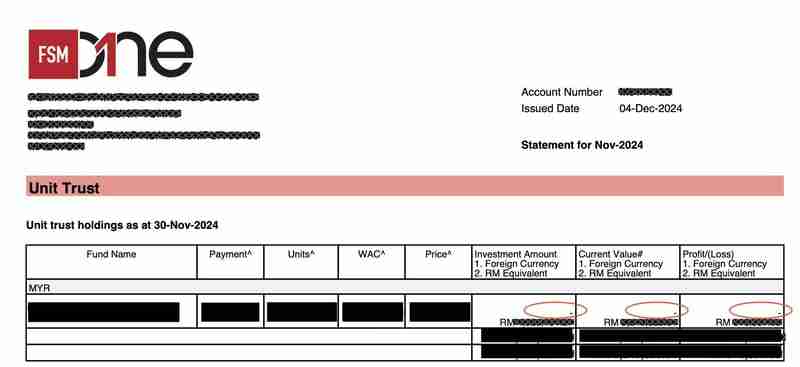
This small change resulted in the following issue:

I consulted ChatGPT on a fix, and it recommended the following scrubbing logic be added to remove the incorrect "-/n" prefix.
# Scrub error prefix
df['Currency'] = df['Currency'].str.replace('[-\n]', '', regex=True)
The scrubbing did the trick and the Fund Holdings CSV output now comes out as expected.
I'm now comfortable that the code to extract PDF data is functional. That said, I don't think a CSV file is the best place to store all this data.
While CSV is user friendly (to me), storing data in a database makes it much easier to retrieve and manipulate data as per the end user's requirements.
I have very limited experience in databases. So what I'll do next is Discovery on a database application that I can onboard quickly.
--Ends
The above is the detailed content of # | Automate PDF data extraction: User Acceptance Testing. For more information, please follow other related articles on the PHP Chinese website!
 Bitcoin exchange
Bitcoin exchange
 c language const usage
c language const usage
 The most promising coin in 2024
The most promising coin in 2024
 High-level language programming
High-level language programming
 java basic data types
java basic data types
 what is adobe flash player
what is adobe flash player
 The latest prices of the top ten virtual currencies
The latest prices of the top ten virtual currencies
 How to recover files emptied from Recycle Bin
How to recover files emptied from Recycle Bin
 What's going on when the ip address is unavailable?
What's going on when the ip address is unavailable?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



