

MarkItDown is a Python package developed by Microsoft, designed to convert a variety of file formats into Markdown.
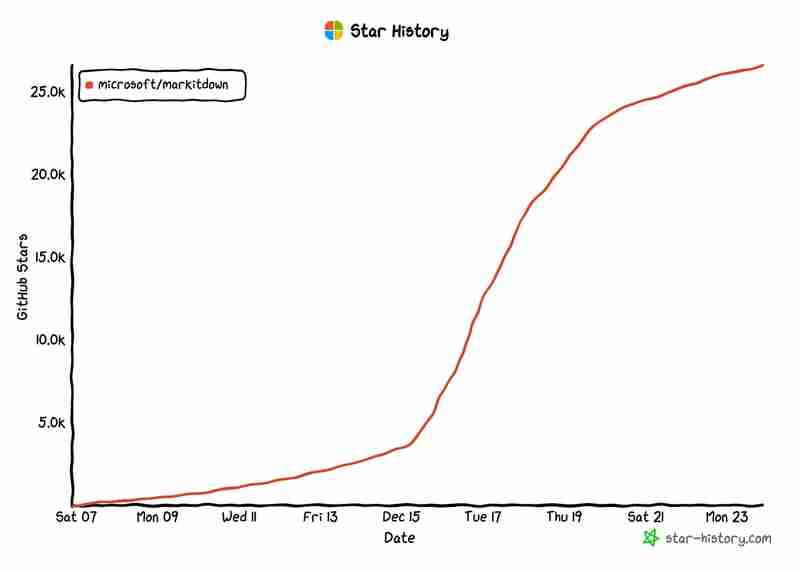
Since its debut, the library has skyrocketed in popularity, gaining over 25k GitHub stars within just two weeks! ?
MarkItDown offers robust support for a wide array of file types, such as:
Its ability to handle not just standard formats like Word but also multi-modal data makes it stand out. For example, it uses OCR and speech recognition to extract content from images and audio files.
The ability to convert anything into Markdown makes MarkItDown a powerful tool for LLM training. By processing domain-specific documents, it provides rich context for generating more accurate and relevant responses in LLM-powered applications.
Using MarkItDown is incredibly straightforward - only 4 lines of code are needed:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("test.xlsx")
print(result.text_content)
Here's some use cases of MarkItDown.
Converting a Word document generates clean and accurate Markdown:

Even multi-tab Excel spreadsheets are handled with ease:

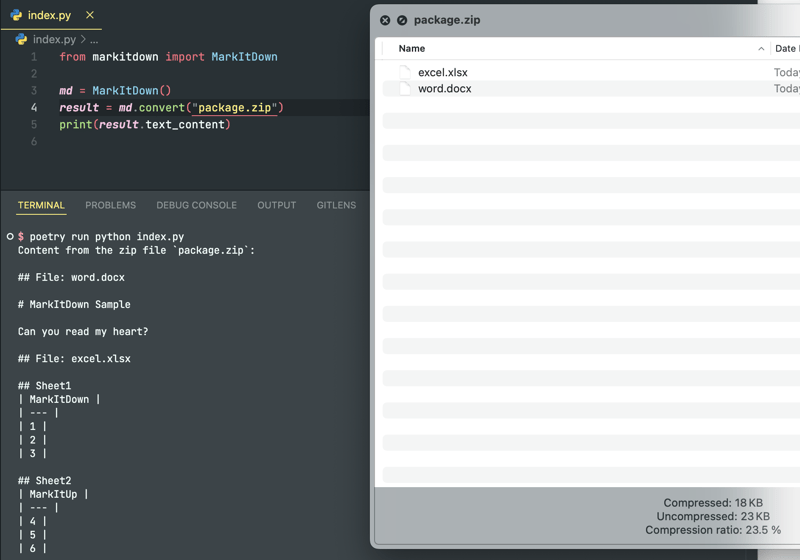
ZIP archives? No problem! The library parses all files inside them recursively:
Initially, image extraction might yield no results:

This is because MarkItDown relies on an LLM to generate image descriptions. By integrating an LLM client, you can enable this feature:
from openai import OpenAI client = OpenAI(api_key="i-am-not-an-api-key") md = MarkItDown(llm_client=client, llm_model="gpt-4o")
With the configuration in place, image files can be successfully processed:

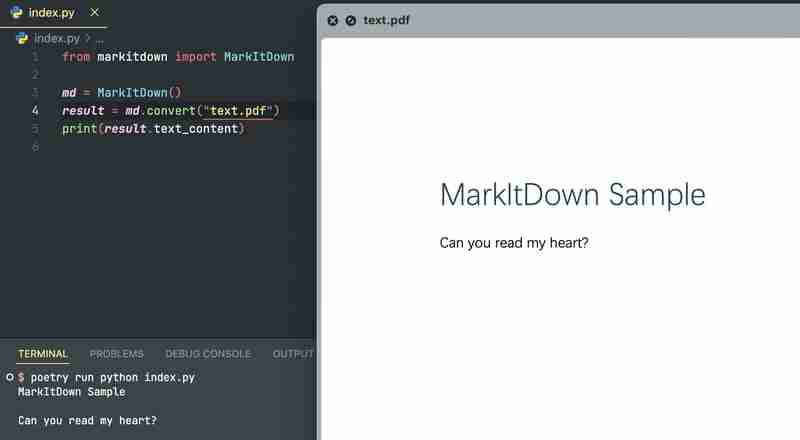
Note: LLM won't deal with image-based PDFs. PDFs need OCR preprocessing to extract content.

However, PDFs lose their formatting upon extraction, therefore headings and plain text are not distinguished:
MarkItDown isn’t without its limitations:
Nonetheless, as an open-source project, it’s highly customizable. Developers can easily extend its functionality due to its clean codebase.
MarkItDown’s architecture is straightforward and modular.
It has a DocumentConverter class, which defines a generic convert() method:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("test.xlsx")
print(result.text_content)
Individual converters inherit from this base class and are registered dynamically:
from openai import OpenAI client = OpenAI(api_key="i-am-not-an-api-key") md = MarkItDown(llm_client=client, llm_model="gpt-4o")
This modular approach makes it easy to add support for new file types.
Office files are transformed into HTML using libraries like mammoth, pandas, or pptx, and then converted to Markdown with BeautifulSoup.

Audio is transcribed with the speech_recognition library, which utilizes Google’s API.
(Microsoft, why not Azure here? ?)
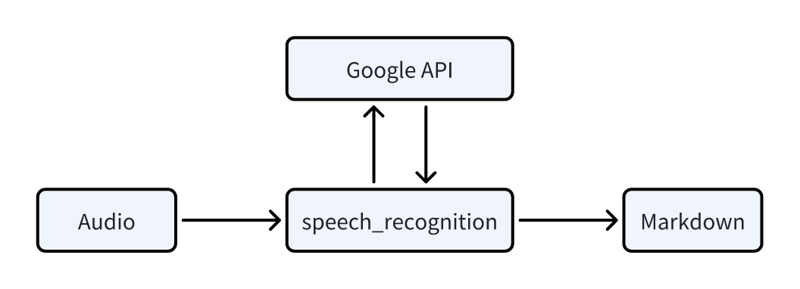
Image processing involves generating a caption via an LLM prompt:
"Write a detailed description for this image."

PDFs are handled by the pdfminer library but lack built-in OCR. You must preprocess PDFs for text extraction.

MarkItDown can run locally, but hosting it as an API unlocks additional flexibility, making it easy to integrate into workflows like Zapier and n8n.
Here’s a simple example of MarkItDown API using FastAPI:
class DocumentConverter:
"""Base class for all document converters."""
def convert(
self, local_path: str, **kwargs: Any
) -> Union[None, DocumentConverterResult]:
raise NotImplementedError()
To call the API:
self.register_page_converter(PlainTextConverter()) self.register_page_converter(HtmlConverter()) self.register_page_converter(DocxConverter()) self.register_page_converter(XlsxConverter()) self.register_page_converter(Mp3Converter()) self.register_page_converter(ImageConverter()) # ...
Hosting Python APIs can be tricky. Traditional services like AWS EC2 or DigitalOcean require renting an entire server, which is always costly.
But now, you can use Leapcell.
It's a platform which can host Python codebase in the serverless way - it charges only per API call, with a generous free-tier usage.
Just connect your GitHub repository, define build and start commands, and you’re all set:

Now you have a MarkItDown API that’s hosted in the cloud, ready for integration into your workflow, and most importantly, only charges when it's really called.
Start building your own MarkItDown API on Leapcell today! ?

The above is the detailed content of Deep Dive into Microsoft MarkItDown. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



