

Building a Chess Agent using DQN

I recently tried to implement a DQN based Chess Agent.
Now, anyone who knows how DQNs and Chess works would tell you that's a dumb idea.
And...it was, but as a beginner I enjoyed it nevertheless. In this article I'll share the insights I learned while working on this.
Understanding the Environment.
Before I started implementing the Agent itself, I had to familiarize myself with the environment I'll be using and make a custom wrapper on top of it so that it can interact with the Agent during training.
-
I used the chess environment from the kaggle_environments library.
from kaggle_environments import make env = make("chess", debug=True)Copy after loginCopy after login
-
I also used Chessnut, which is a lightweight python library that helps parse and validate chess games.
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
Copy after loginCopy after login
In this environment, the state of the board is stored in the FEN format.

It provides a compact way to represent all the pieces on the board and the currently active player. However, since I planned on feeding the input to a neural network, I had to modify the representation of the state.
Converting FEN to Matrix format
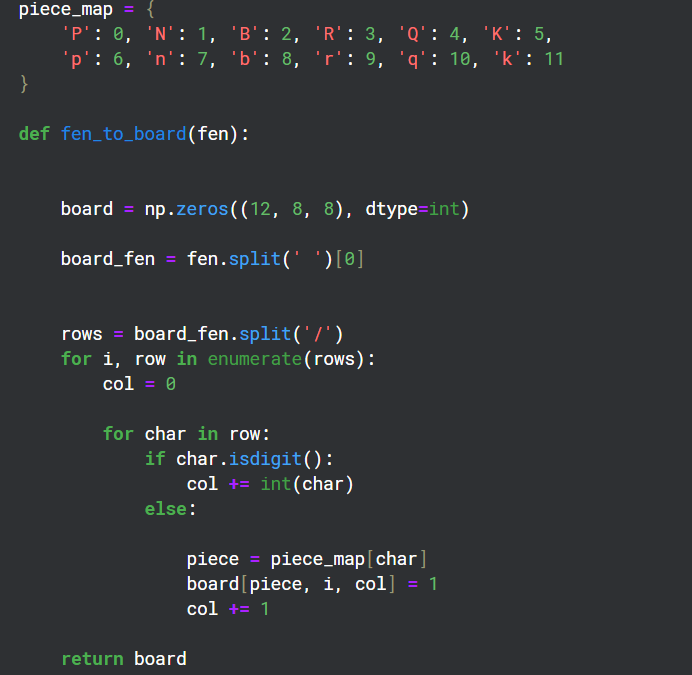
Since there are 12 different types of pieces on a board, I created 12 channels of 8x8 grids to represent the state of each of those types on the board.
Creating a Wrapper for the Environment
class EnvCust:
def __init__(self):
self.env = make("chess", debug=True)
self.game=Game(env.state[0]['observation']['board'])
print(self.env.state[0]['observation']['board'])
self.action_space=game.get_moves();
self.obs_space=(self.env.state[0]['observation']['board'])
def get_action(self):
return Game(self.env.state[0]['observation']['board']).get_moves();
def get_obs_space(self):
return fen_to_board(self.env.state[0]['observation']['board'])
def step(self,action):
reward=0
g=Game(self.env.state[0]['observation']['board']);
if(g.board.get_piece(Game.xy2i(action[2:4]))=='q'):
reward=7
elif g.board.get_piece(Game.xy2i(action[2:4]))=='n' or g.board.get_piece(Game.xy2i(action[2:4]))=='b' or g.board.get_piece(Game.xy2i(action[2:4]))=='r':
reward=4
elif g.board.get_piece(Game.xy2i(action[2:4]))=='P':
reward=2
g=Game(self.env.state[0]['observation']['board']);
g.apply_move(action)
done=False
if(g.status==2):
done=True
reward=10
elif g.status == 1:
done = True
reward = -5
self.env.step([action,'None'])
self.action_space=list(self.get_action())
if(self.action_space==[]):
done=True
else:
self.env.step(['None',random.choice(self.action_space)])
g=Game(self.env.state[0]['observation']['board']);
if g.status==2:
reward=-10
done=True
self.action_space=list(self.get_action())
return self.env.state[0]['observation']['board'],reward,done
The point of this wrapper was to provide a reward policy for the agent and a step function which is used to interact with the environment during training.
Chessnut was useful in getting information like the legal moves possible at current state of the board and also to recognize Checkmates during the game.
I tried to create a reward policy to give positive points for checkmates and taking out enemy pieces while negative points for losing the game.
Creating a Replay Buffer
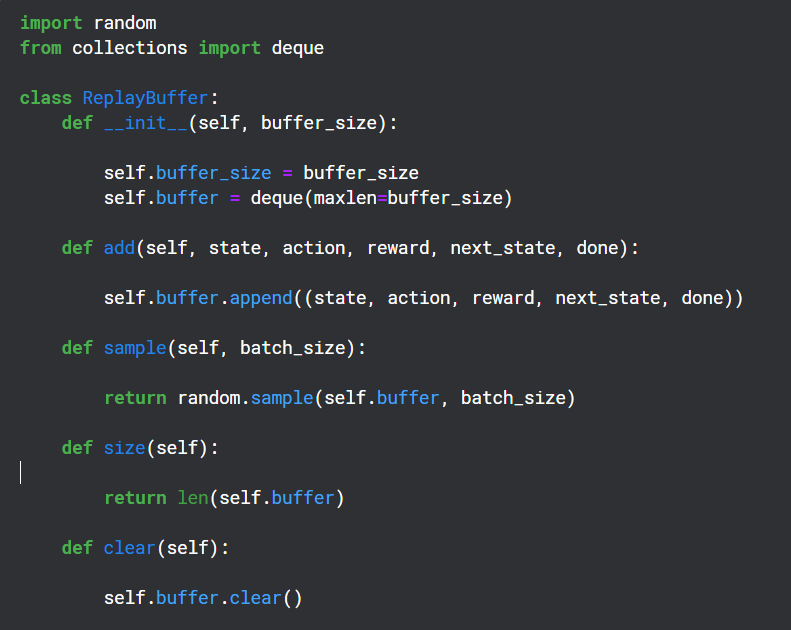
Replay Buffer is used during the training period to save the (state,action,reward,next state) output by the Q-Network and later used randomly for backpropagation of the Target Network
Auxiliary Functions


Chessnut returns legal action in UCI format which looks like 'a2a3', however to interact with the Neural Network I converted each action into a distinct index using a basic pattern. There are total 64 Squares, so I decided to have 64*64 unique indexes for each move.
I know that not all of the 64*64 moves would be legal, but I could handle legality using Chessnut and the pattern was simple enough.
Neural Network Structure
from kaggle_environments import make
env = make("chess", debug=True)
This Neural Network uses the Convolutional Layers to take in the 12 channel input and also uses the valid action indexes to filter out the reward output prediction.
Implementing the Agent
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
This was obviously a very basic model which had no chance of actually performing well (And it didn't), but it did help me understand how DQNs work a little better.

The above is the detailed content of Building a Chess Agent using DQN. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to solve the permissions problem encountered when viewing Python version in Linux terminal?
Apr 01, 2025 pm 05:09 PM
How to solve the permissions problem encountered when viewing Python version in Linux terminal?
Apr 01, 2025 pm 05:09 PM
Solution to permission issues when viewing Python version in Linux terminal When you try to view Python version in Linux terminal, enter python...
 How to avoid being detected by the browser when using Fiddler Everywhere for man-in-the-middle reading?
Apr 02, 2025 am 07:15 AM
How to avoid being detected by the browser when using Fiddler Everywhere for man-in-the-middle reading?
Apr 02, 2025 am 07:15 AM
How to avoid being detected when using FiddlerEverywhere for man-in-the-middle readings When you use FiddlerEverywhere...
 How to efficiently copy the entire column of one DataFrame into another DataFrame with different structures in Python?
Apr 01, 2025 pm 11:15 PM
How to efficiently copy the entire column of one DataFrame into another DataFrame with different structures in Python?
Apr 01, 2025 pm 11:15 PM
When using Python's pandas library, how to copy whole columns between two DataFrames with different structures is a common problem. Suppose we have two Dats...
 How to teach computer novice programming basics in project and problem-driven methods within 10 hours?
Apr 02, 2025 am 07:18 AM
How to teach computer novice programming basics in project and problem-driven methods within 10 hours?
Apr 02, 2025 am 07:18 AM
How to teach computer novice programming basics within 10 hours? If you only have 10 hours to teach computer novice some programming knowledge, what would you choose to teach...
 How does Uvicorn continuously listen for HTTP requests without serving_forever()?
Apr 01, 2025 pm 10:51 PM
How does Uvicorn continuously listen for HTTP requests without serving_forever()?
Apr 01, 2025 pm 10:51 PM
How does Uvicorn continuously listen for HTTP requests? Uvicorn is a lightweight web server based on ASGI. One of its core functions is to listen for HTTP requests and proceed...
 How to handle comma-separated list query parameters in FastAPI?
Apr 02, 2025 am 06:51 AM
How to handle comma-separated list query parameters in FastAPI?
Apr 02, 2025 am 06:51 AM
Fastapi ...
 How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
Using python in Linux terminal...
 How to get news data bypassing Investing.com's anti-crawler mechanism?
Apr 02, 2025 am 07:03 AM
How to get news data bypassing Investing.com's anti-crawler mechanism?
Apr 02, 2025 am 07:03 AM
Understanding the anti-crawling strategy of Investing.com Many people often try to crawl news data from Investing.com (https://cn.investing.com/news/latest-news)...
