

How is an SQL Query Statement executed

Hello everyone! This is my first article.
In this article, I will introduce how an sql query statement is executed
Below is the MySQL architecture diagram:
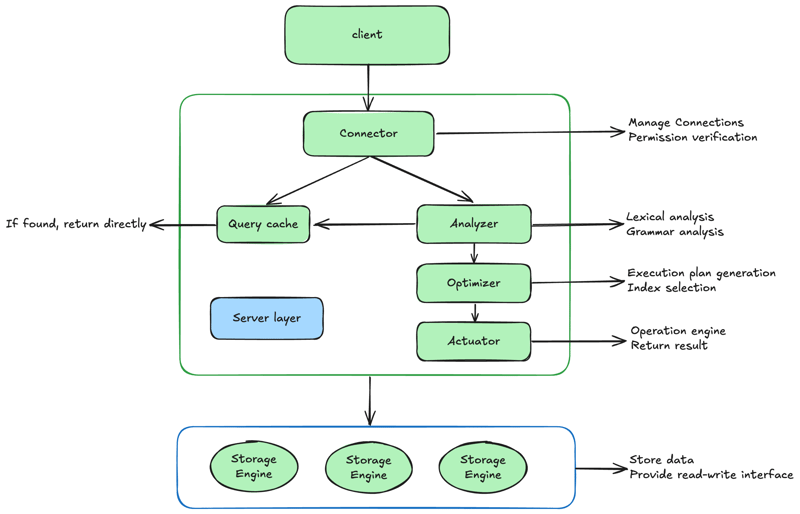
In general, MySQl can be divided into two parts: the server and the storage engine layer.
The server layer includes the connector, query cache, parser, optimizer, executor, etc., and contains most of the MySQL's core service functions, as well as all build-in functions (such as date, time, math and encryption functions). All cross-storage engine features, such as stored procedures, triggers and views are implemented at this layer.
The storage engine layer is responsible for data storage and retrieval. Its architecture is plugin-based, supporting multiple storage engines such as InnoDB, MyISAM, Memory. Staring from MySQL 5.5.5,InnoDB became the default storage engine for MySQL.
You can specify the memory engine wneh create a table by using the create table statement with engine=memory.
Different storage engines share the same Server layer
Connector
The first step is to connect the database, which requires the connector. The connector is responsible for establishing a connection with the client, obtaining permissings and maintaing and managing the connection. The connection command is:
mysql -h$ip -P$port -u$user -p
This command is used to establish a connection with the server. After completing the classtic TCP handshake, the connector will use the provider username and password to authenticate your identity.
- If the username or password is incorrect, you will receive an Access denied for user error, and the client program will terminate.
- If authentication is successful, the connector will retrieve the permissions of the current account from the permissions table. All permission checks during this connection rely on this initial retrieval.
This means that once a connection is successfully established, any changes made by the administrator to the user's permissions will not affect the existing connection's permissions. Only new connections will use the updated permission settings.
After the connection is established, if there is no subsequent action, the connection enters an idle state, which can be viewed using the show processlist command:

If the client remains inactive for too long, the connector will automatically disconnect. The duration is controlled by the wait_timeout parameter, which defaults to 8 hours.
If the connection is terminated and the client sends a request, it will receive an error message: Lost connection to MySQL server during query. To continue, you need to reconnect and then execute the request.
In databases, a persistent connection refers to one where the client maintains the same connection for continuous requests after successfully connecting. A short connection refers to disconnecting after a few queries and reconnecting for subsequent queries.
Since the connection process is complex, it's recommended to minimize the creation of connections during development, i.e., use persistent connections whenever possible.
However, when using persistent connections, MySQL's memory usage may increase significantly because temporary memory used during execution is managed within the connection object. These resources are released only when the connection is terminated. If persistent connections accumulate, it may lead to excessive memory usage, causing the system to forcefully terminate MySQL (OOM), resulting in an unexpected restart.
Solutions:
- Periodically disconnect persistent connections. After using a connection for a while or executing a query that consumes excessive memory, disconnect and reconnect for subsequent queries.
- If you are using MySQL 5.7 or later, you can use mysql_reset_connection after executing a resource-intensive operation to reinitialize connection resources. This process does not require reconnection or re-authentication but resets the connection to its just-created state.
Query Cache
Note: Starting from MySQL 8.0, the query cache feature has been completely removed because its disadvantages outweigh its advantages.
When MySQL receives a query request, it first checks the query cache to see if this query has been executed before. Queries that have been executed before and their results are cached in memory as key-value pairs. The key is the query statement, and the value is the result. If the key is found in the query cache, the value is returned directly to the client.
If the query is not found in the query cache, the process continues.
Why does the query cache do more harm than good?
Query cache invalidation occurs very frequently. Any update to a table will clear all query caches related to that table, resulting in a very low cache hit rate, unless the table is a static configuration table.
MySQL provides an "on-demand" method for using the query cache. By setting the parameter query_cache_type to DEMAND, SQL statements will not use the query cache by default. To use the query cache, you can explicitly specify SQL_CACHE:
mysql -h$ip -P$port -u$user -p
Parser
If the query cache is not hit, the statement execution process begins. MySQL first needs to understand what to do, so it parses the SQL statement.
The parser first performs lexical analysis. The input SQL statement, consisting of strings and spaces, is analyzed by MySQL to identify what each part represents. For example, select is identified as a query statement, T as a table name, and ID as a column.
After lexical analysis, syntax analysis is performed. Based on the results of lexical analysis, the syntax analyzer determines whether the SQL statement conforms to MySQL's syntax rules.
If there is a syntax error, an error message like You have an error in your SQL syntax will be displayed. For instance, in the following query, the select keyword is misspelled:
select SQL_CACHE * from T where ID=10;
Optimizer
After parsing, MySQL knows what you want to do. Next, the optimizer determines how to do it.
The optimizer decides which index to use when a table has multiple indexes or the order of table joins when a query involves multiple tables. For example, in the following query:
mysql> elect * from t where ID=1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1
The query can start by retrieving values from t1 or t2. Both approaches yield the same logical result, but their performance may differ. The optimizer's role is to choose the most efficient plan.
After the optimization phase, the process proceeds to the executor.
Executor
The executor starts executing the query.
Before execution, it first checks whether the current connection has permission to query the table. If not, an error indicating insufficient permissions is returned. (Permission checks are also performed when returning results from the query cache.)
If permission is granted, the table is opened, and execution continues. During this process, the executor interacts with the storage engine based on the table's engine definition.
For example, suppose table T has no index on the ID column. The executor's execution process would be as follows:
- Call the InnoDB engine interface to fetch the first row of the table and check whether the ID value is 10. If not, skip it; if yes, add it to the result set.
- Call the engine interface to fetch the "next row," repeating the same logic until all rows are checked.
- The executor returns the accumulated result set to the client.
At this point, the query is complete.
For indexed tables, the process involves using the engine's pre-defined methods to fetch the "first matching row" and "next matching rows" iteratively.
In the slow query log, the rows_examined field indicates the number of rows scanned during query execution. This value accumulates every time the executor calls the engine to retrieve a data row.
In some cases, a single call to the executor may involve scanning multiple rows internally within the engine. Therefore, the number of rows scanned by the engine does not necessarily equal rows_examined.
End
Thank you for reading!I hope the article can be helpful to you.
The above is the detailed content of How is an SQL Query Statement executed. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1243
24
14
1423
52
1317
25
1268
29
1243
24

 When might a full table scan be faster than using an index in MySQL?
Apr 09, 2025 am 12:05 AM
When might a full table scan be faster than using an index in MySQL?
Apr 09, 2025 am 12:05 AM
Full table scanning may be faster in MySQL than using indexes. Specific cases include: 1) the data volume is small; 2) when the query returns a large amount of data; 3) when the index column is not highly selective; 4) when the complex query. By analyzing query plans, optimizing indexes, avoiding over-index and regularly maintaining tables, you can make the best choices in practical applications.
 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL is suitable for beginners because it is simple to install, powerful and easy to manage data. 1. Simple installation and configuration, suitable for a variety of operating systems. 2. Support basic operations such as creating databases and tables, inserting, querying, updating and deleting data. 3. Provide advanced functions such as JOIN operations and subqueries. 4. Performance can be improved through indexing, query optimization and table partitioning. 5. Support backup, recovery and security measures to ensure data security and consistency.
 MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
The main role of MySQL in web applications is to store and manage data. 1.MySQL efficiently processes user information, product catalogs, transaction records and other data. 2. Through SQL query, developers can extract information from the database to generate dynamic content. 3.MySQL works based on the client-server model to ensure acceptable query speed.
 Explain the role of InnoDB redo logs and undo logs.
Apr 15, 2025 am 12:16 AM
Explain the role of InnoDB redo logs and undo logs.
Apr 15, 2025 am 12:16 AM
InnoDB uses redologs and undologs to ensure data consistency and reliability. 1.redologs record data page modification to ensure crash recovery and transaction persistence. 2.undologs records the original data value and supports transaction rollback and MVCC.
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
