

Harness the Power of Web Scraping with Python and Beautiful Soup: A MIDI Music Example
The internet is a treasure trove of information, but accessing it programmatically can be challenging without dedicated APIs. Python's Beautiful Soup library offers a powerful solution, enabling you to scrape and parse data directly from web pages.
Let's explore this by scraping MIDI data to train a Magenta neural network for generating classic Nintendo-style music. We'll source MIDI files from the Video Game Music Archive (VGM).
Setting Up Your Environment
Ensure you have Python 3 and pip installed. It's crucial to create and activate a virtual environment before installing dependencies:
pip install requests==2.22.0 beautifulsoup4==4.8.1
We use Beautiful Soup 4 (Beautiful Soup 3 is no longer maintained).
Scraping and Parsing with Requests and Beautiful Soup
First, let's fetch the HTML and create a BeautifulSoup object:
import requests from bs4 import BeautifulSoup vgm_url = 'https://www.vgmusic.com/music/console/nintendo/nes/' html_text = requests.get(vgm_url).text soup = BeautifulSoup(html_text, 'html.parser')
The soup object allows navigation of the HTML. soup.title gives the page title; print(soup.get_text()) displays all text.
Mastering Beautiful Soup's Power
The find() and find_all() methods are essential. soup.find() targets single elements (e.g., soup.find(id='banner_ad').text gets banner ad text). soup.find_all() iterates through multiple elements. For instance, this prints all hyperlink URLs:
for link in soup.find_all('a'):
print(link.get('href'))find_all() accepts arguments like regular expressions or tag attributes for precise filtering. Refer to the Beautiful Soup documentation for advanced features.
Navigating and Parsing HTML
Before writing parsing code, examine the browser-rendered HTML. Each webpage is unique; data extraction often requires creativity and experimentation.

Our goal is to download unique MIDI files, excluding duplicates and remixes. Browser developer tools (right-click, "Inspect") help identify HTML elements for programmatic access.
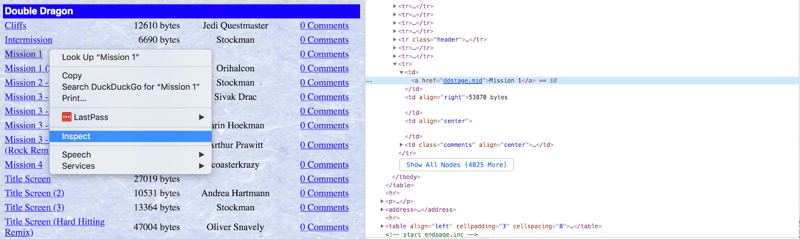
Let's use find_all() with regular expressions to filter links containing MIDI files (excluding those with parentheses in their names):
Create nes_midi_scraper.py:
import re
import requests
from bs4 import BeautifulSoup
vgm_url = 'https://www.vgmusic.com/music/console/nintendo/nes/'
html_text = requests.get(vgm_url).text
soup = BeautifulSoup(html_text, 'html.parser')
if __name__ == '__main__':
attrs = {'href': re.compile(r'\.mid$')}
tracks = soup.find_all('a', attrs=attrs, string=re.compile(r'^((?!\().)*$'))
count = 0
for track in tracks:
print(track)
count += 1
print(len(tracks))This filters MIDI files, prints their link tags, and displays the total count. Run with python nes_midi_scraper.py.
Downloading the MIDI Files
Now, let's download the filtered MIDI files. Add the download_track function to nes_midi_scraper.py:
pip install requests==2.22.0 beautifulsoup4==4.8.1
This function downloads each track and saves it with a unique filename. Run the script from your desired save directory. You should download approximately 2230 MIDI files (depending on the website's current content).

Exploring the Web's Potential
Web scraping opens doors to vast datasets. Remember that webpage changes can break your code; keep your scripts updated. Use libraries like Mido (for MIDI data processing) and Magenta (for neural network training) to build upon this foundation.
The above is the detailed content of Web Scraping and Parsing HTML in Python with Beautiful Soup. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



