

Our current websites usually rely on dozens of different resources, such as a monolithic collection of images, CSS, fonts, JavaScript, JSON data, etc. However, the world's first website was written only in HTML.
JavaScript, as an excellent client-side scripting language, has played an important role in the evolution of websites. With the help of XMLHttpRequest or XHR objects, JavaScript can achieve communication between clients and servers without reloading the page.
However, this dynamic process is challenged by Fetch API. What is Fetch API? How to use Fetch API in How to Make HTTP Requests in Node.js with Node-Fetch API?? Why is Fetch API a better choice?
Start getting answers from this article now!
In How to Make HTTP Requests in Node.js with Node-Fetch API?, HTTP requests are a fundamental part of building web applications or interacting with web services. They allow a client (like a browser or another application) to send data to a server, or request data from a server. These requests use the Hypertext Transfer Protocol (HTTP), which is the foundation of data communication on the web.
How to Make HTTP Requests in Node.js with Node-Fetch API? has become one of the go-to technologies for web scraping and automation tasks due to its unique characteristics, robust ecosystem, and asynchronous, non-blocking architecture.
Why How to Make HTTP Requests in Node.js with Node-Fetch API? is ideal for web scraping and automation? Let's figure them out!
Node-fetch is a lightweight module that brings the Fetch API to the How to Make HTTP Requests in Node.js with Node-Fetch API? environment. It simplifies the process of making HTTP requests and handling responses.
The Fetch API is built around Promises and is well suited for asynchronous operations such as scraping data from a website, interacting with a RESTful API, or automating tasks.
The Fetch API is a modern, Promise-based interface designed to handle network requests in a more efficient and flexible manner compared to the traditional XMLHttpRequest object.
It is natively supported in contemporary browsers, meaning there is no need for additional libraries or plugins. In this guide, we will explore how to utilize the Fetch API to perform GET and POST requests, as well as how to manage responses and errors effectively.
? Note: If How to Make HTTP Requests in Node.js with Node-Fetch API? is not installed on your computer, you need to install it first. You can download the How to Make HTTP Requests in Node.js with Node-Fetch API? installation package suitable for your operating system here. The recommended How to Make HTTP Requests in Node.js with Node-Fetch API? version is 18 and above.
If you haven't created a project yet, you can create a new project with the following command:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Open the package.json file, add the type field, and set it to module:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
This is a library for using the Fetch API in How to Make HTTP Requests in Node.js with Node-Fetch API?. You can install the node-fetch library with the following command:
npm install node-fetch
After the download is complete, we can start using the Fetch API to send network requests. Create a new file index.js in the root directory of the project and add the following code:
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));
Execute the following command to run the code:
node index.js
We will see the following How to Make HTTP Requests in How to Make HTTP Requests in Node.js with Node-Fetch API? with Node-Fetch API?:

How to use Fetch API to send the POST request? Please refer to the following method. Create a new file post.js in the root directory of the project and add the following code:
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));
Let's analyze this code:
Execute the following command to run the code:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
The How to Make HTTP Requests in How to Make HTTP Requests in Node.js with Node-Fetch API? with Node-Fetch API? you can see:

We need to create a new file response.js in the root directory of the project and add the following code:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
In the above code, we first fill in an incorrect URL address to trigger an HTTP error. Then we check the status code of the resulting response in the then method, and throw an error if the status code is not 200. Finally, we catch the error in the catch method and print it out.
Execute the following command to run the code:
npm install node-fetch
After the code is executed, you will see the following How to Make HTTP Requests in How to Make HTTP Requests in Node.js with Node-Fetch API? with Node-Fetch API?:

CAPTCHAs (Completely Automated Public Turing tests to tell Computers and Humans Apart) are designed to prevent automated systems, like web scrapers, from accessing websites. They typically require users to prove they are human by solving puzzles, identifying objects in images, or entering distorted characters.
Many modern websites use JavaScript frameworks like React, Angular, or Vue.js to load content dynamically. This means that the content you see in the browser is often rendered after the page loads, making it difficult to scrape with traditional methods that rely on static HTML.
Websites often implement measures to detect and block scraping activities, one of the most common methods being IP blocking. This occurs when too many requests are sent from the same IP address in a short period, causing the website to flag and block that IP.
Scrapeless is one of the best comprehensive scraping tools due to its ability to bypass website blocks in real time, including IP blocking, CAPTCHA challenges, and JavaScript rendering. It supports advanced features like IP rotation, TLS fingerprint management, and CAPTCHA solving, making it ideal for large-scale web scraping.
Its easy integration with How to Make HTTP Requests in Node.js with Node-Fetch API? and high success rate for avoiding detection make Scrapeless a reliable and efficient choice for bypassing modern anti-bot defenses, ensuring smooth and uninterrupted scraping operations.
Just follow some easy steps, you can integrate Scrapeless into your How to Make HTTP Requests in Node.js with Node-Fetch API? project.
It's time to keep scrolling! The following will be more wonderful!
Before you get started, you need to register a Scrapeless account.
We need to go to the Scrapeless Dashboard, click the "Scraping API" menu on the left, and then select a service you want to use.
Here we can use the "Amazon" service

Entering the Amazon API page, we can see that Scrapeless has provided us with default parameters and code examples in three languages:
Here we choose How to Make HTTP Requests in Node.js with Node-Fetch API? and copy the code example to our project:
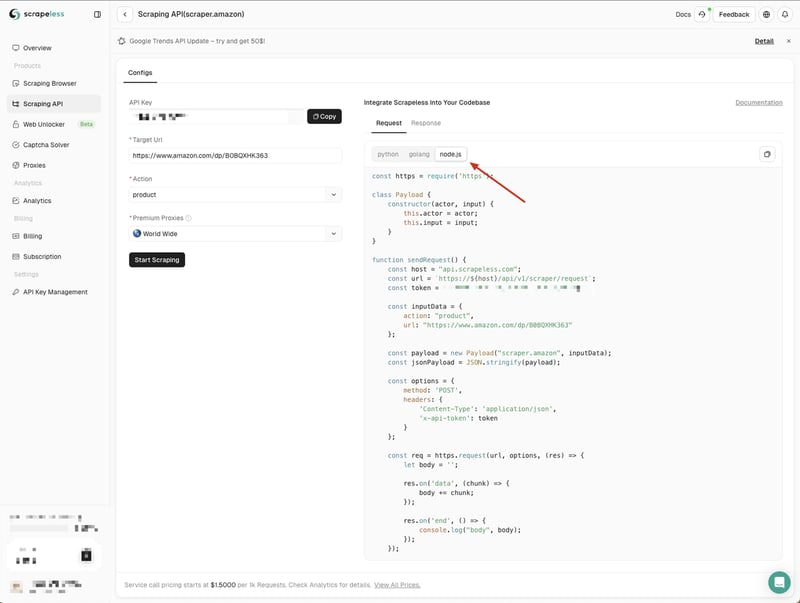
The How to Make HTTP Requests in Node.js with Node-Fetch API? code examples of Scrapeless use the http module by default. We can use the node-fetch module to replace the http module, so that we can use the Fetch API to send network requests.
First, create a scraping-api-amazon.js file in our project, and then replace the code examples provided by Scrapeless with the following code examples:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Run the code by executing the following command:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
We will see the results returned by the Scrapeless API. Here we simply print them out. You can process the returned results according to your needs.

Scrapeless provides a Web unlocker service that can help you bypass common anti-scraping measures, such as CAPTCHA bypass, IP blocking, etc. The Web unlocker service can help you solve some common crawling problems and make your crawling tasks smoother.
To verify the effectiveness of the Web unlocker service, we can first use the curl command to access a website that requires a CAPTCHA, and then use the Scrapeless Web unlocker service to access the same website to see if the CAPTCHA can be successfully bypassed.
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
By looking at the returned results, we can see that this website is connected to Cloudflare verification mechanism, and we need to enter the verification code to continue accessing the website.


Here we create a new web-unlocker.js file. We still need to use the node-fetch module to send network requests, so we need to replace the http module in the code example provided by Scrapeless with the node-fetch module:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Execute the following command to run the script:
npm install node-fetch


Look! Scrapeless Web unlocker successfully bypassed the verification code, and we can see that the returned results contain the web page content we need.
To make your choice easier, Axios and Fetch API have the following differences:
The most notable feature of Node. js v21 is the stabilization of the Fetch API.
For new projects, it's recommended to use the Fetch API due to its modern features and simplicity. However, if you need to support very old browsers or are maintaining legacy code, Ajax might still be necessary.
The addition of Fetch API in How to Make HTTP Requests in Node.js with Node-Fetch API? is a long-awaited feature. Using Fetch API in How to Make HTTP Requests in Node.js with Node-Fetch API? can ensure that your scraping work is done easily. However, it is inevitable to encounter serious network blockades when using Node Fetch API.
The above is the detailed content of How to Make HTTP Requests in Node.js with Node-Fetch API?. For more information, please follow other related articles on the PHP Chinese website!
 How to light up Douyin close friends moment
How to light up Douyin close friends moment
 microsoft project
microsoft project
 What is phased array radar
What is phased array radar
 How to use fusioncharts.js
How to use fusioncharts.js
 Yiou trading software download
Yiou trading software download
 The latest ranking of the top ten exchanges in the currency circle
The latest ranking of the top ten exchanges in the currency circle
 What to do if win8wifi connection is not available
What to do if win8wifi connection is not available
 How to recover files emptied from Recycle Bin
How to recover files emptied from Recycle Bin








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



