

Get started with Vector Search in Azure Cosmos DB

This tutorial demonstrates how to quickly implement vector search in Azure Cosmos DB for NoSQL using a simple movie dataset. The application is available in Python, TypeScript, .NET, and Java, providing step-by-step instructions for setup, data loading, and similarity search queries.
Vector databases excel at storing and managing vector embeddings—high-dimensional mathematical representations of data. Each dimension reflects a data feature, potentially numbering in the tens of thousands. A vector's location in this space signifies its characteristics. This technique vectorizes various data types, including words, phrases, documents, images, and audio, enabling applications like similarity search, multi-modal search, recommendation engines, and large language models (LLMs).
Prerequisites:
- An Azure subscription (or a free Azure account, or the free tier of Azure Cosmos DB for NoSQL).
- An Azure Cosmos DB for NoSQL account.
- An Azure OpenAI Service resource with the
text-embedding-ada-002embedding model deployed (accessible via the Azure AI Foundry portal). This model provides text embeddings. - The necessary programming language environment (Maven for Java).
Configuring the Vector Database in Azure Cosmos DB for NoSQL:
-
Enable the feature: This is a one-time step. Explicitly enable vector indexing and search within Azure Cosmos DB.

-
Create database and container: Create a database (e.g.,
movies_db) and a container (e.g.,movies) with a partition key of/id. -
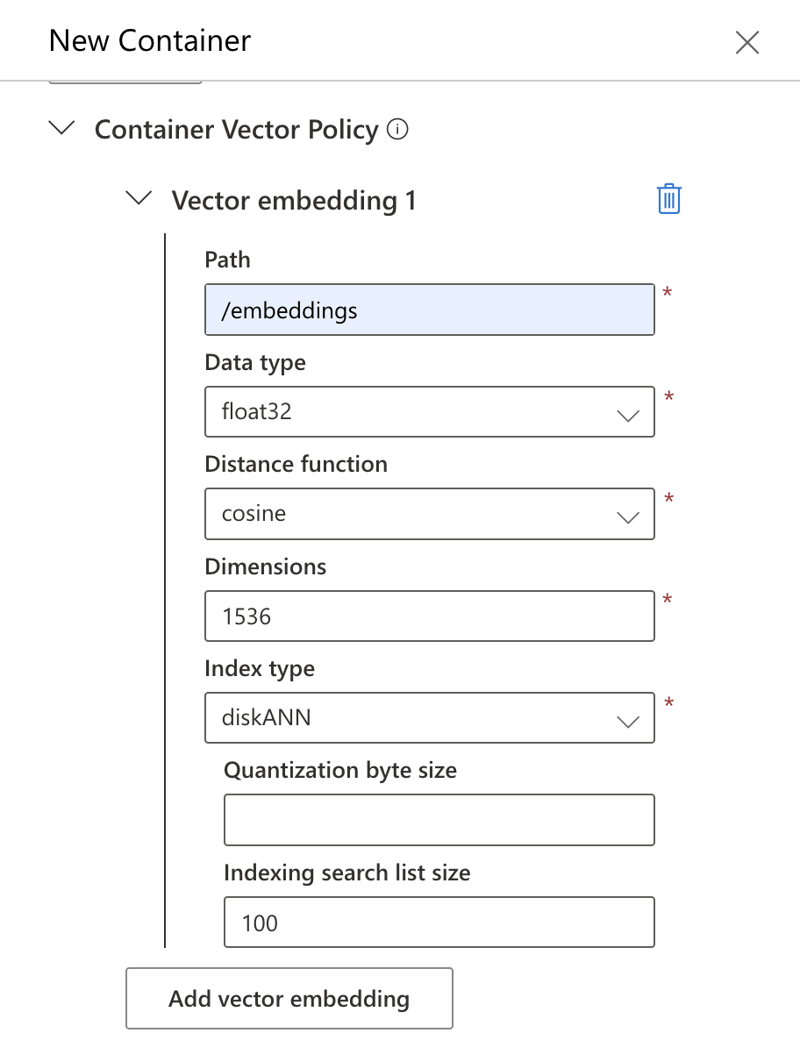
Create policies: Configure a vector embedding policy and an indexing policy for the container. For this example, use the settings shown below (manual configuration via the Azure portal is used here, though programmatic methods are also available).
Index Type Note: The example uses the
diskANNindex type with a dimension of 1536, matching thetext-embedding-ada-002model. While adaptable, changing the index type necessitates adjusting the embedding model to match the new dimension.

Loading Data into Azure Cosmos DB:
A sample movies.json file provides movie data. The process involves:
- Reading movie information from the JSON file.
- Generating vector embeddings for movie descriptions using the Azure OpenAI Service.
- Inserting the complete data (title, description, and embeddings) into the Azure Cosmos DB container.
Set the following environment variables before proceeding:
export COSMOS_DB_CONNECTION_STRING="" export DATABASE_NAME="" export CONTAINER_NAME="" export AZURE_OPENAI_ENDPOINT="" export AZURE_OPENAI_KEY="" export AZURE_OPENAI_VERSION="2024-10-21" export EMBEDDINGS_MODEL="text-embedding-ada-002"
Clone the repository:
git clone https://github.com/abhirockzz/cosmosdb-vector-search-python-typescript-java-dotnet cd cosmosdb-vector-search-python-typescript-java-dotnet
Language-specific instructions for data loading are provided below. Each method uses the environment variables defined above. Successful execution will output messages indicating data insertion into Cosmos DB.
Data Loading Instructions (Abbreviated):
- Python:
cd python; python3 -m venv .venv; source .venv/bin/activate; pip install -r requirements.txt; python load.py - TypeScript:
cd typescript; npm install; npm run build; npm run load - Java:
cd java; mvn clean install; java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar load - .NET:
cd dotnet; dotnet restore; dotnet run load
Verifying Data in Azure Cosmos DB:
Confirm data insertion using the Azure portal or a Visual Studio Code extension.

Vector/Similarity Search:
The search component uses the VectorDistance function to find similar movies based on a search criterion (e.g., "comedy"). The process is:
- Generate a vector embedding for the search criterion.
- Use
VectorDistanceto compare it with existing embeddings.
The query:
SELECT TOP @num_results c.id, c.description, VectorDistance(c.embeddings, @embedding) AS similarityScore FROM c ORDER BY VectorDistance(c.embeddings, @embedding)
Language-specific instructions (assuming environment variables are set and data is loaded):
Search Instructions (Abbreviated):
-
Python:
python search.py "inspiring" 3 -
TypeScript:
npm run search "inspiring" 3 -
Java:
java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar search "inspiring" 3 -
.NET:
dotnet run search "inspiring" 3
Closing Notes:
Experiment with different vector index types (flat, quantizedFlat), distance metrics (cosine, Euclidean, dot product), and embedding models (text-embedding-3-large, text-embedding-3-small). Azure Cosmos DB for MongoDB vCore also supports vector search.
The above is the detailed content of Get started with Vector Search in Azure Cosmos DB. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to solve the permissions problem encountered when viewing Python version in Linux terminal?
Apr 01, 2025 pm 05:09 PM
How to solve the permissions problem encountered when viewing Python version in Linux terminal?
Apr 01, 2025 pm 05:09 PM
Solution to permission issues when viewing Python version in Linux terminal When you try to view Python version in Linux terminal, enter python...
 How to avoid being detected by the browser when using Fiddler Everywhere for man-in-the-middle reading?
Apr 02, 2025 am 07:15 AM
How to avoid being detected by the browser when using Fiddler Everywhere for man-in-the-middle reading?
Apr 02, 2025 am 07:15 AM
How to avoid being detected when using FiddlerEverywhere for man-in-the-middle readings When you use FiddlerEverywhere...
 How to efficiently copy the entire column of one DataFrame into another DataFrame with different structures in Python?
Apr 01, 2025 pm 11:15 PM
How to efficiently copy the entire column of one DataFrame into another DataFrame with different structures in Python?
Apr 01, 2025 pm 11:15 PM
When using Python's pandas library, how to copy whole columns between two DataFrames with different structures is a common problem. Suppose we have two Dats...
 How to teach computer novice programming basics in project and problem-driven methods within 10 hours?
Apr 02, 2025 am 07:18 AM
How to teach computer novice programming basics in project and problem-driven methods within 10 hours?
Apr 02, 2025 am 07:18 AM
How to teach computer novice programming basics within 10 hours? If you only have 10 hours to teach computer novice some programming knowledge, what would you choose to teach...
 How does Uvicorn continuously listen for HTTP requests without serving_forever()?
Apr 01, 2025 pm 10:51 PM
How does Uvicorn continuously listen for HTTP requests without serving_forever()?
Apr 01, 2025 pm 10:51 PM
How does Uvicorn continuously listen for HTTP requests? Uvicorn is a lightweight web server based on ASGI. One of its core functions is to listen for HTTP requests and proceed...
 How to handle comma-separated list query parameters in FastAPI?
Apr 02, 2025 am 06:51 AM
How to handle comma-separated list query parameters in FastAPI?
Apr 02, 2025 am 06:51 AM
Fastapi ...
 How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
Using python in Linux terminal...
 How to get news data bypassing Investing.com's anti-crawler mechanism?
Apr 02, 2025 am 07:03 AM
How to get news data bypassing Investing.com's anti-crawler mechanism?
Apr 02, 2025 am 07:03 AM
Understanding the anti-crawling strategy of Investing.com Many people often try to crawl news data from Investing.com (https://cn.investing.com/news/latest-news)...
