

This article explores six key strategies for customizing Large Language Models (LLMs), ranging from simple techniques to more resource-intensive methods. Choosing the right approach depends on your specific needs, resources, and technical expertise.
Why Customize LLMs?
Pre-trained LLMs, while powerful, often fall short of specific business or domain requirements. Customizing an LLM allows you to tailor its capabilities to your exact needs without the prohibitive cost of training a model from scratch. This is especially crucial for smaller teams lacking extensive resources.
Choosing the Right LLM:
Before customization, selecting the appropriate base model is critical. Factors to consider include:
Six LLM Customization Strategies (Ranked by Resource Intensity):
The following strategies are presented in ascending order of resource consumption:
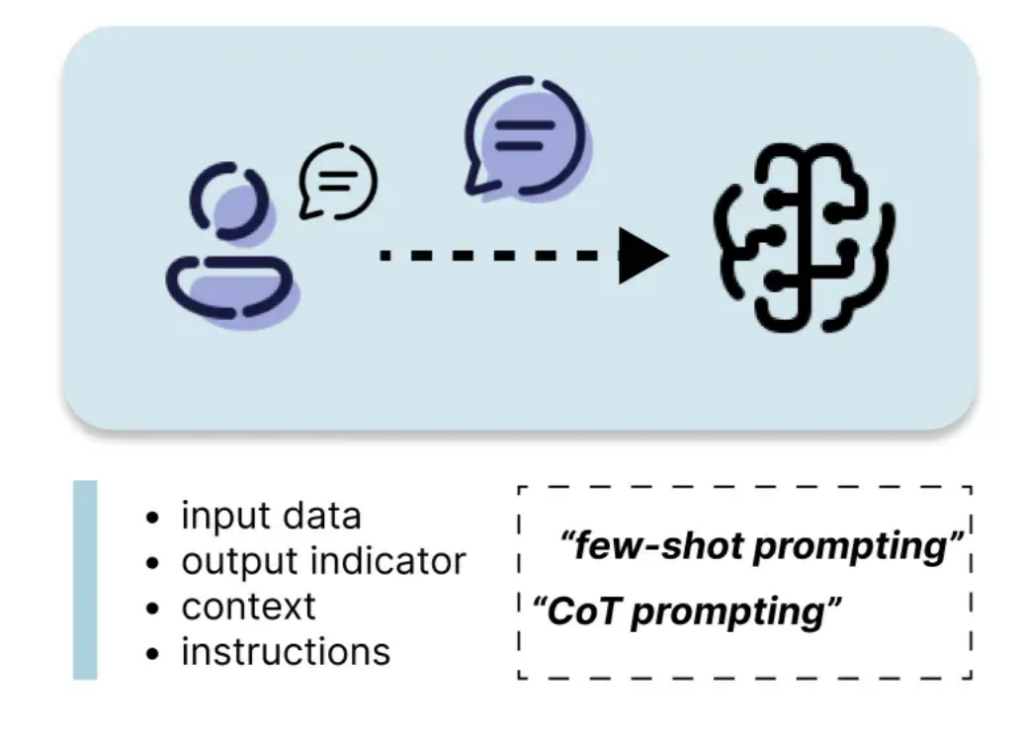
Prompt engineering involves carefully crafting the input text (prompt) to guide the LLM's response. This includes instructions, context, input data, and output indicators. Techniques like zero-shot, one-shot, and few-shot prompting, as well as more advanced methods like Chain of Thought (CoT), Tree of Thoughts, Automatic Reasoning and Tool Use (ART), and ReAct, can significantly improve performance. Prompt engineering is efficient and readily implemented.
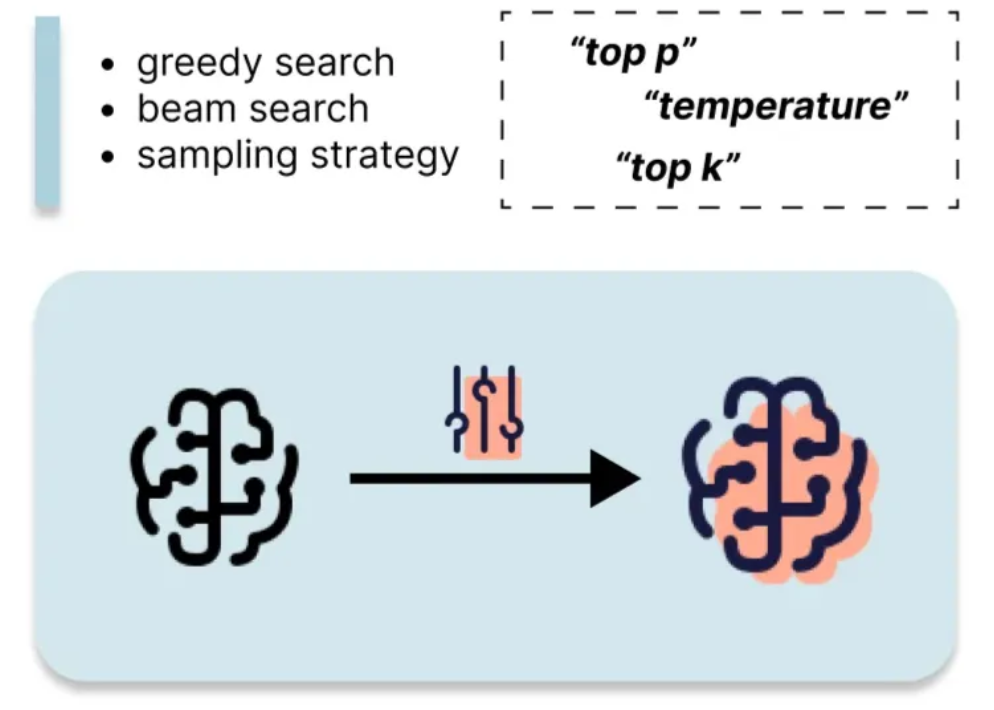
Controlling decoding strategies (greedy search, beam search, sampling) and sampling parameters (temperature, top-k, top-p) at inference time allows you to adjust the randomness and diversity of the LLM's output. This is a low-cost method for influencing model behavior.

RAG enhances LLM responses by incorporating external knowledge. It involves retrieving relevant information from a knowledge base and feeding it to the LLM along with the user's query. This reduces hallucinations and improves accuracy, particularly for domain-specific tasks. RAG is relatively resource-efficient as it doesn't require retraining the LLM.
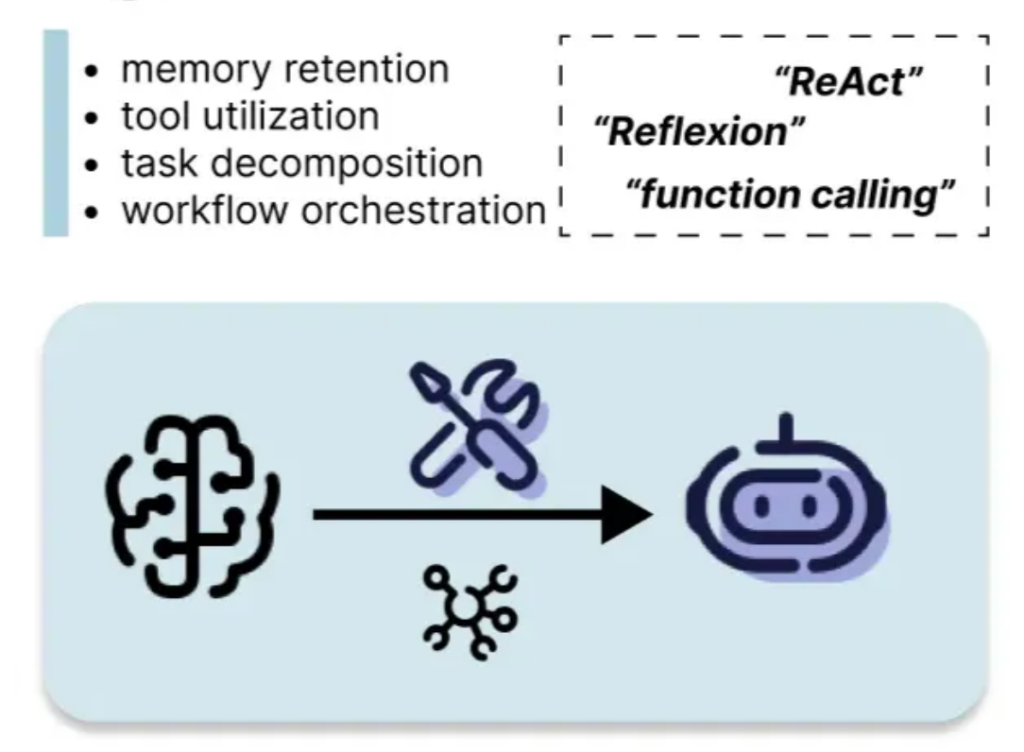
Agent-based systems enable LLMs to interact with the environment, use tools, and maintain memory. Frameworks like ReAct (Synergizing Reasoning and Acting) combine reasoning with actions and observations, improving performance on complex tasks. Agents offer significant advantages in managing complex workflows and tool utilization. 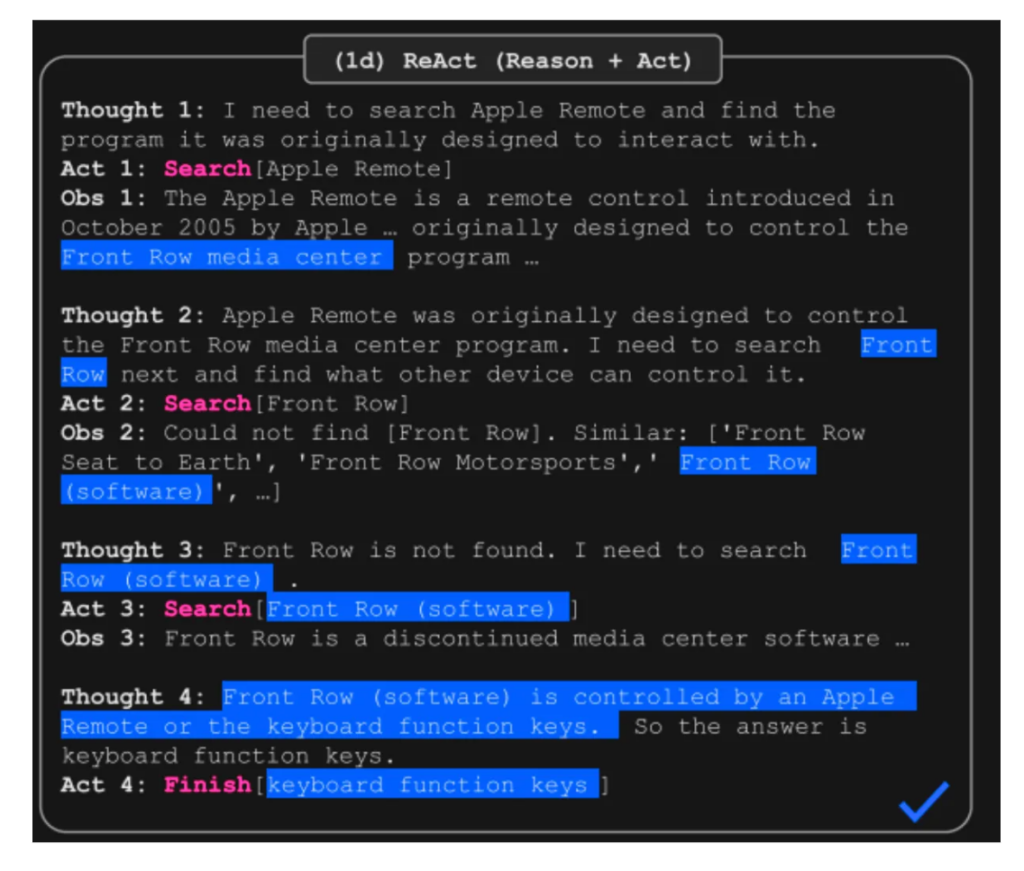
Fine-tuning involves updating the LLM's parameters using a custom dataset. Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA significantly reduce the computational cost compared to full fine-tuning. This approach requires more resources than the previous methods but provides more substantial performance gains.
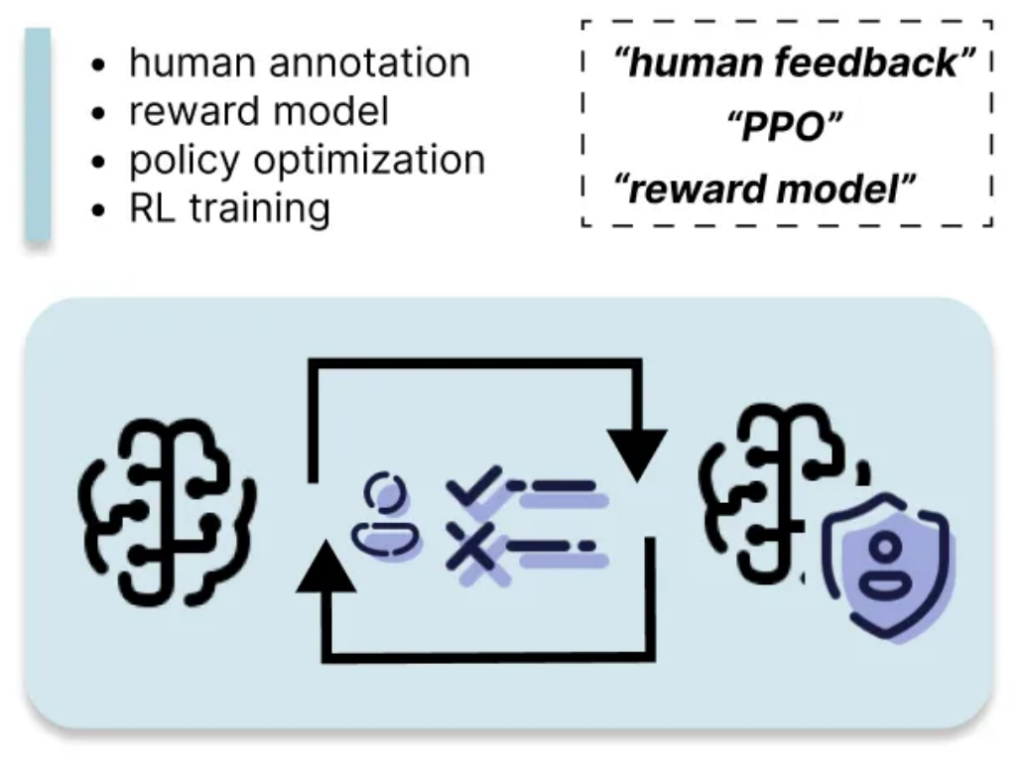
RLHF aligns the LLM's output with human preferences by training a reward model based on human feedback. This is the most resource-intensive method, requiring significant human annotation and computational power, but it can lead to substantial improvements in response quality and alignment with desired behavior.
This overview provides a comprehensive understanding of the various LLM customization techniques, enabling you to choose the most appropriate strategy based on your specific requirements and resources. Remember to consider the trade-offs between resource consumption and performance gains when making your selection.
The above is the detailed content of 6 Common LLM Customization Strategies Briefly Explained. For more information, please follow other related articles on the PHP Chinese website!
 How to share a printer between two computers
How to share a printer between two computers
 How to use the groupby function
How to use the groupby function
 Is the higher the computer CPU frequency, the better?
Is the higher the computer CPU frequency, the better?
 What is the interrupt priority?
What is the interrupt priority?
 How to solve access denied
How to solve access denied
 The difference between wlan and wifi
The difference between wlan and wifi
 How to solve invalid synrax
How to solve invalid synrax
 What's going on when phpmyadmin can't access it?
What's going on when phpmyadmin can't access it?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



