
 Technology peripherals
AI
Developing an AI-Powered Smart Guide for Business Planning & Entrepreneurship
Technology peripherals
AI
Developing an AI-Powered Smart Guide for Business Planning & Entrepreneurship
Developing an AI-Powered Smart Guide for Business Planning & Entrepreneurship

If you are not a Medium member, you can read the full story at this link.
After the launch of ChatGPT and the following surge of Large Language Models (LLMs), their inherent limitations of hallucination, knowledge cutoff date, and the inability to provide organization- or person-specific information soon became evident and were seen as major drawbacks. To address these issues, Retrieval Augment Generation (RAG) methods soon gained traction which integrate external data to LLMs and guide their behavior to answer questions from a given knowledge base.
Interestingly, the first paper on RAG was published in 2020 by researchers from Facebook AI Research (now Meta AI), but it was not until the advent of ChatGPT that its potential was fully realized. Since then, there has been no stopping. More advanced and complex RAG frameworks were introduced which not only improved the accuracy of this technology but also enabled it to deal with multimodal data, expanding its potential for a wide range of applications. I wrote on this topic in detail in the following articles, specifically discussing contextual multimodal RAG, multimodal AI search for business applications, and information extraction and matchmaking platforms.
Integrating Multimodal Data into a Large Language Model
Multimodal AI Search for Business Applications
AI-Powered Information Extraction and Matchmaking
With the expanding landscape of RAG technology and the emerging data access requirements, it was realized that the functionality of a retriever-only RAG, which answers questions from a static knowledge base, can be extended by integrating other diverse knowledge sources and tools such as:
- Multiple databases (e.g., knowledge bases comprising vector databases and knowledge graphs)
- Real-time web search to access recent information
- External APIs to collect specific data such as stock market trends or data from company-specific tools like Slack channels or email accounts
- Tools for tasks like data analysis, report writing, literature review, and people search, etc.
- Comparing and consolidating information from multiple sources.
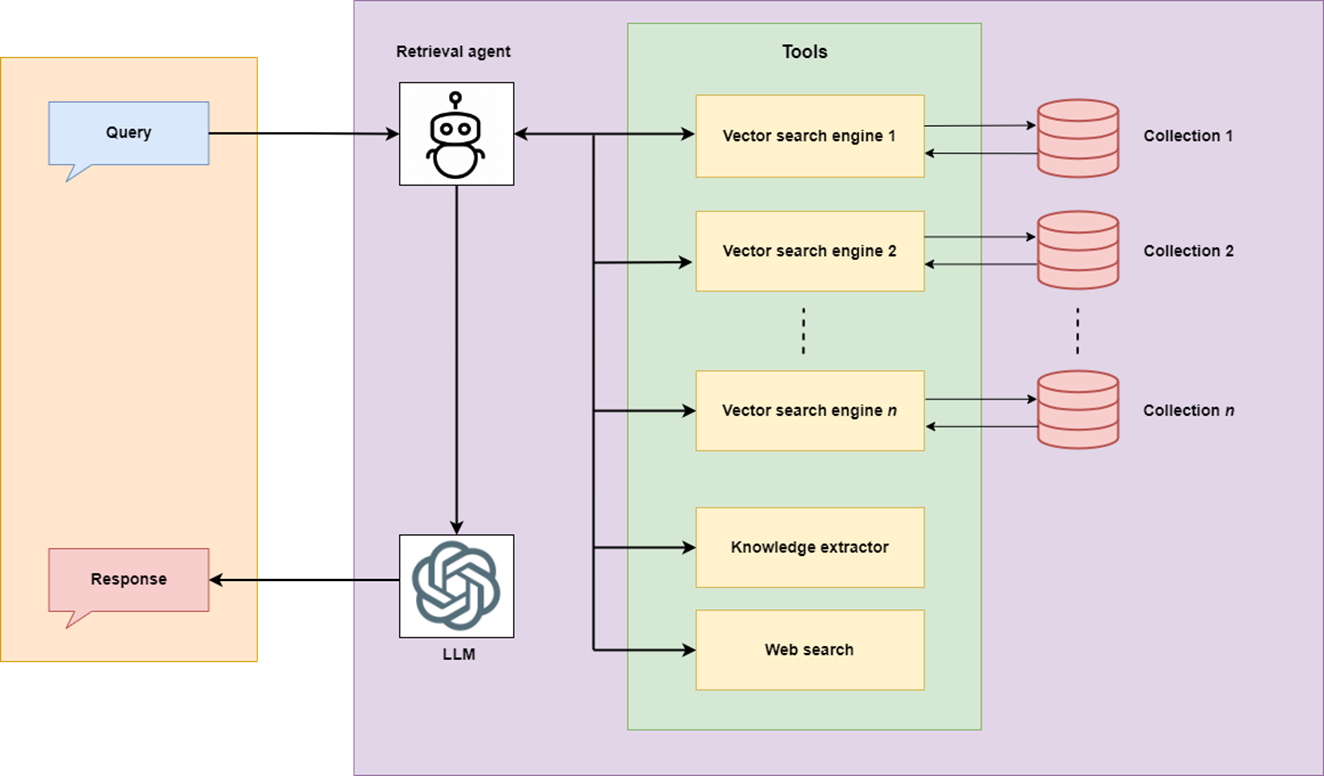
To achieve this, a RAG should be able to select the best knowledge source and/or tool based on the query. The emergence of AI agents introduced the idea of "agentic RAG" which could select the best course of action based on the query.
In this article, we will develop a specific agentic RAG application, called Smart Business Guide (SBG) – the first version of the tool that is part of our ongoing project called UPBEAT, funded by Interreg Central Baltic. The project is focused on upskilling immigrants in Finland and Estonia for Entrepreneurship and business planning using AI. SBG is one of the tools intended to be used in this project’s upskilling process. This tool focuses on providing precise and quick information from authentic sources to people intending to start a business, or those already doing business.
The SBG’s agentic RAG comprises:
- Business and entrepreneurship guides as a knowledge base containing information about business planning, entrepreneurship, company registration, taxation, business ideas, rules and regulations, business opportunities, licenses and permits, business guidelines, and others.
- Web search to fetch recent information with sources.
- Knowledge extraction tools to fetch information from trusted sources. This information includes contacts of relevant authorities, recent taxation rules, recent business registration rules, and recent licensing regulations.
What is special about this agentic RAG?
- Option to select different open-source models (Llama, Mistral, Gemma) ** as well as proprietary models _(gpt-4o, gpt-4o-min_i) in the entire agentic workflow. The open-source models do not run locally and hence do not require a powerful, expensive computing machine. Instead, they run on Groq Cloud’s platform with a free API. And yes, this makes it a cost-fre**e agentic RAG. The GPT models can also be selected with an OpenAI’s API key.
- Options to enforce knowledge base search, web search, and hybrid search.
- Grading of retrieved documents for improving response quality, and intelligently invoking web search based on grading.
- Options to select response type: concise, moderate, or explanatory.
Specifically, the article is structured around the following topics:
- Parsing data to construct the knowledge base using LlamaParse
- Developing an agentic workflow using LangGraph.
- Developing an advanced agentic RAG (hereinafter called Smart Business Guide or SBG) using free, open-source models
The whole code of this application can be found on GitHub.
The application code is structured in two .py files: _agenticrag.py which implements the entire agentic workflow, and app.py which implements the Streamlit graphical user interface.
Let’s dive into it.
Constructing Knowledge Base with LlamaParsing and LangChain
The knowledge base of the SBG comprises authentic business and entrepreneurship guides published by Finnish agencies. Since these guides are voluminous and finding a required piece of information from them is not trivial, the purpose is to develop an agentic RAG that could not only provide precise information from these guides but can also augment them with a web search and other trusted sources in Finland for updated information.
LlamaParse is a genAI-native document parsing platform built with LLMs and for LLM use cases. I have explained the use of LlamaParse in the articles I cited above. This time, I parsed the documents directly at LlamaCloud. LlamaParse offers 1000 free credits per day. The use of these credits depends on the parsing mode. For text-only PDF, ‘Fast‘ mode (1 credit / 3 pages) works well which skips OCR, image extraction, and table/heading identification. There are other more advanced modes available with a higher number of credit points per page. I selected the ‘premium‘ mode which performs OCR, image extraction, and table/heading identification and is ideal for complex documents with images.
I defined the following parsing instructions.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
The parsed documents were downloaded in markdown format from LlamaCloud. The same parsing can be done through LlamaCloud API as follows.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Here is an example page from the guide Creativity and Business by Pikkala, A. et al., (2015) ("free to copy for non-commercial private or public use with attribution").

Here is the parsed output of this page. LlamaParse efficiently extracted information from all structures in the page. The notebook shown in the page is in image format.
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
The parsed markdown documents are then split into chunks using LangChain’s RecursiveCharacterTextSplitter with CHUNK_SIZE = 3000 and CHUNK_OVERLAP = 200.
def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docsSubsequently, a vectorstore is created in Chroma database using an embedding model such as open-source all-MiniLM-L6-v2 model or OpenAI’s text-embedding-3-large.
def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstoreCreating Agentic Workflow
An AI agent is the combination of the workflow and the decision-making logic to intelligently answer questions or perform other complex tasks that need to be broken down into simpler sub-tasks.
I used LangGraph to design a workflow for our AI agent for the sequence of actions or decisions in the form of a graph. Our agent has to decide whether to answer the question from the vector database (knowledge base), web search, hybrid search, or by using a tool.
In my following article, I explained the process of creating an agentic workflow using LangGraph.
How to Develop a Free AI Agent with Automatic Internet Search
We need to create graph nodes that represent a workflow to make decisions (e.g., web search or vector database search). The nodes are connected by edges which define the flow of decisions and actions (e.g., what is the next state after retrieval). The graph state keeps track of the information as it moves through the graph so that the agent uses the correct data for each step.
The entry point in the workflow is a router function which determines the initial node to execute in the workflow by analyzing the user’s query. The entire workflow contains the following nodes.
- retrieve: Fetches semantically similar chunks of information from the vectorstore.
- _grade_documents_: Grades the relevance of retrieved chunks based on the user’s query.
- _route_after_grading_: Based on the grading, determines whether to genreate a response with the retrieved documents or proceed to web search.
- websearch: Fetches information from web sources using Tavily search engine’s API.
- generate: Generates a response to the user’s query using the provided context (information retrieved from vector store and/or web search).
- _get_contact_tool_: Fetches contact information from predefined trusted URLs related to Finnish Immigration services.
- _get_tax_info_: Fetches tax-related information from predefined trusted URLs.
- _get_registration_info_: Fetches details on company registration processes in Finland from predefined trusted URLs.
- _get_licensing_info_: Fetches information about licenses and permits required for starting a business in Finland.
- _hybrid_search_: Combines document retrieval and internet search results to provide a broader context for answering the query.
- unrelated: Handles questions unrelated to the workflow’s focus
Here are the edges in the workflow.
- _retrieve → grade_documents_: Retrieved documents are sent for grading.
- _grade_documents → websearch_: web search is invoked if the retrieved documents are deemed irrelevant.
- _grade_documents → generate_: Proceeds to response generation if the retrieved documents are relevant.
- websearch → generate: Passes the results of the web search for response generation.
- _get_contact_tool, get_taxinfo, _get_registrationinfo, _get_licensinginfo → generate: The edges from these four tools to generate node pass the fetched information from specific trusted sources for response generation.
- _hybridsearch → generate: Passes the combined results (vectorstore websearch) for response generation.
- unrelated → generate: Provides a fallback response for unrelated questions.
A graph state structure acts as a container for maintaining the state of the workflow and includes the following elements:
- question: The user’s query or input that drives the workflow.
- generation: The final generated response to the user’s query, which is populated after processing.
- _web_search_needed_: A flag indicating whether a web search is required based on the relevance of retrieved documents.
- documents: A list of retrieved or processed documents that are relevant to the query.
- _answer_style_: Specifies the desired style of the answer, such as "Concise," "Moderate," or "Explanatory".
The graph state structure is defined as follows:
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Following router function analyzes the query and routes it to a relevant node for processing. A chain is created comprising a prompt to select a tool/node from a tool selection dictionary and the query. The chain invokes a router LLM to select the relevant tool.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)The questions not relevant to the workflow are routed to _handleunrelated node which provides a fallback response through generate node.
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
The entire workflow is depicted in the following figure.
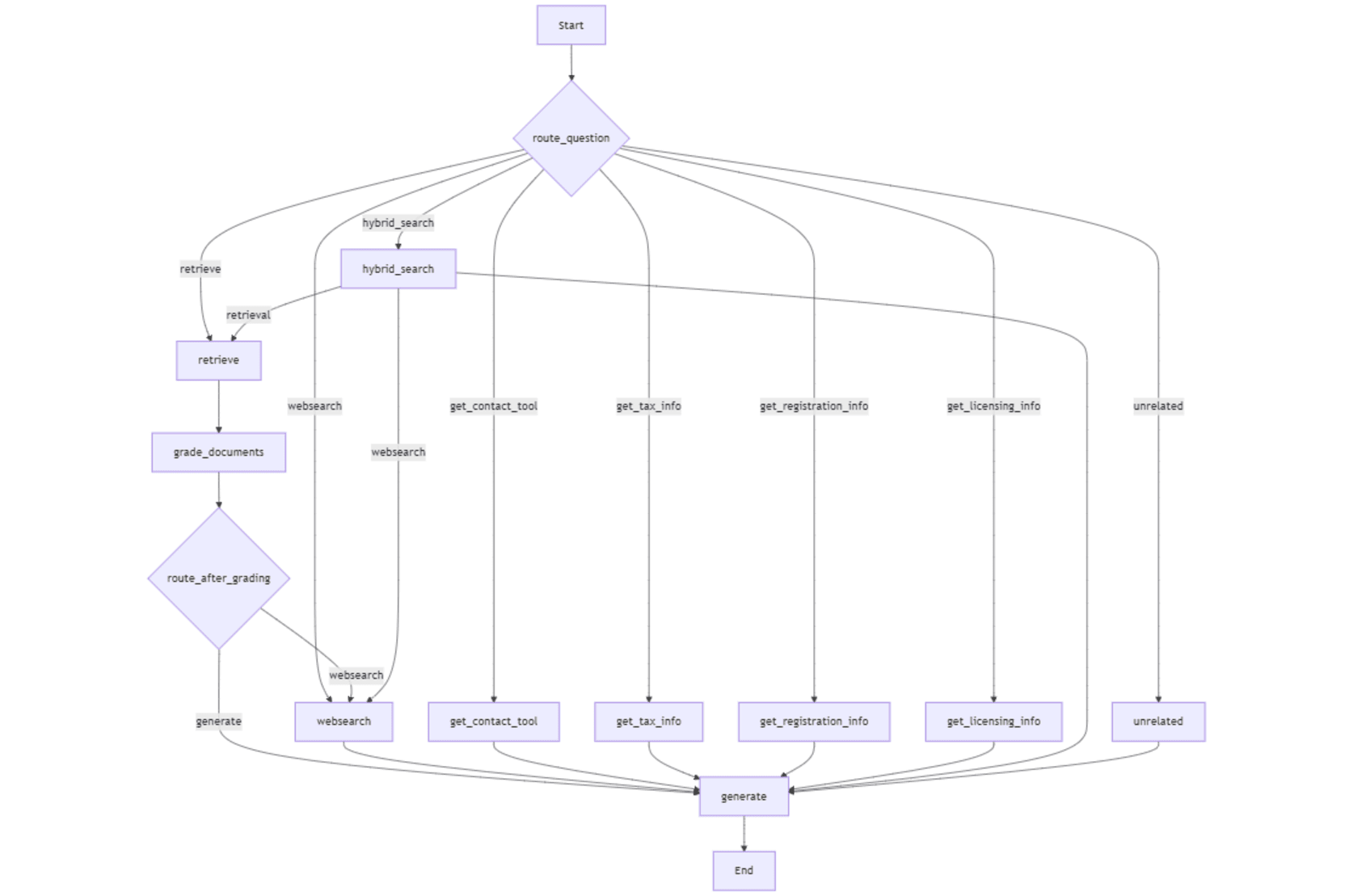
Retrieval and Grading
The retrieve node invokes the retriever with the question to fetch relevant chunks of information from the vector store. These chunks ("documents") are sent to the _gradedocuments node to grade their relevancy. Based on the graded chunks ("_filtereddocs"), the _route_aftergrading node decides whether to proceed to generation with the retrieved information or to invoke web search. The helper function _initialize_graderchain initializes the grader chain with a prompt guiding the grader LLM to assess the relevancy of each chunk. The _gradedocuments node analyzes each chunk to determine whether it is relevant to the question. For each chunk, it outputs "Yes" or "No" depending whether the chunk is relevant to the question.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Web and Hybrid Search
The _websearch node is reached either by _route_aftergrading node when no relevant chunks are found in the retrieved information, or directly by _routequestion node when either _internet_searchenabled state flag is "True" (selected by the radio button in the user interface), or the router function decides to route the query to _websearch to fetch recent and more relevant information.
Tavily search engine’s free API can be obtained by creating an account at their website. The free plan offers 1000 credit points per month. Tavily search results are appended to the state variable "document" which is then passed to generate node with the state variable "question".
Hybrid search combines the results of both retriever and Tavily search and populates "document" state variable, which is passed to generate node with "question" state variable.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Invoking Tools
The tools used in this agentic workflow are the scrapping functions to fetch information from predefined trusted URLs. The difference between Tavily and these tools is that Tavily performs a broader internet search to bring results from diverse sources. Whereas, these tools use Python’s Beautiful Soup web scrapping library to extract information from trusted sources (predefined URLs). In this way, we make sure that the information regarding certain queries is extracted from known, trusted sources. In addition, this information retrieval is completely free.
Here is how _get_taxinfo node works with some helper functions. The other tools (nodes) of this type also work in the same way.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Generating Response
The node, generate, creates the final response by invoking a chain with a predefined prompt (LangChain’s PromptTemplate class) described below. The _ragprompt receives the state variables _ "question", "context", and "answer_styl_e" and guides the entire behavior of the response generation including instructions about response style, conversational tone, formatting guidelines, citation rules, hybrid context handling, and context-only focus.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)The generate node first retrieves the state variables "question", "documents", and "_answerstyle" and formats the "documents" into a single string which serves as the context. Subsequently, it invokes the generation chain with _ragprompt and a response generation LLM _ to generate the final answer which is populated in "generatio_n" state variable. This state variable is used by _app.p_y to display the generated response in the Streamlit user interface.
With Groq’s free API, there is a possibility of hitting a model’s rate or context window limit. In that case, I extended generate node to dynamically switch the models in a circular fashion from the list of model names, and revert to the current model after generating the response.
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
Helper Functions
There are other helping functions in _agenticrag.py for initializing application, LLMs, embedding models, and session variables. The function _initializeapp is called from app.py during app initialization and __ is triggered every time a model or state variable is changed via the Streamlit app. It reinitializes components and saves the updated states. This function also keeps track of various session variables and prevents redundant initialization.
def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docsThe following helper functions initializes an answering LLM, embedding model, router LLM, and grading LLM. The list of model names, _modellist, is used to keep track of models during the dynamic switching of models by generate node.
def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstoreEstablishing the Workflow
Now the graph state, nodes, conditional entry points using _routequestion, and edges are defined to establish the flow between nodes. Finally, the workflow is compiled into an executable app for use within the Streamlit interface. The condition entry point in the workflow uses _routequestion function to select the first node in the workflow based on the query. The conditional edge (_workflow.add_conditionaledges) describes whether to transition to websearch or to generate node based on the relevancy of the chunks determined by _gradedocuments node.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
The Streamlit Interface
The Streamlit application in app.py provides an interactive interface to ask questions and display responses using dynamic settings for model selection, answer styles, and query-specific tools. The _initializeapp function, imported from _agenticrag.py, initializes all the session variables including all LLMs, embedding model, and other options selected from the left sidebar.
The print statements in _agentic_rag.p_y are captured by redirecting sys.stdout to an io.stringIO buffer. The content of this buffer is then displayed in the debug placeholder using the _textarea component in Streamlit.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Here is the snapshot of the Streamlit interface:

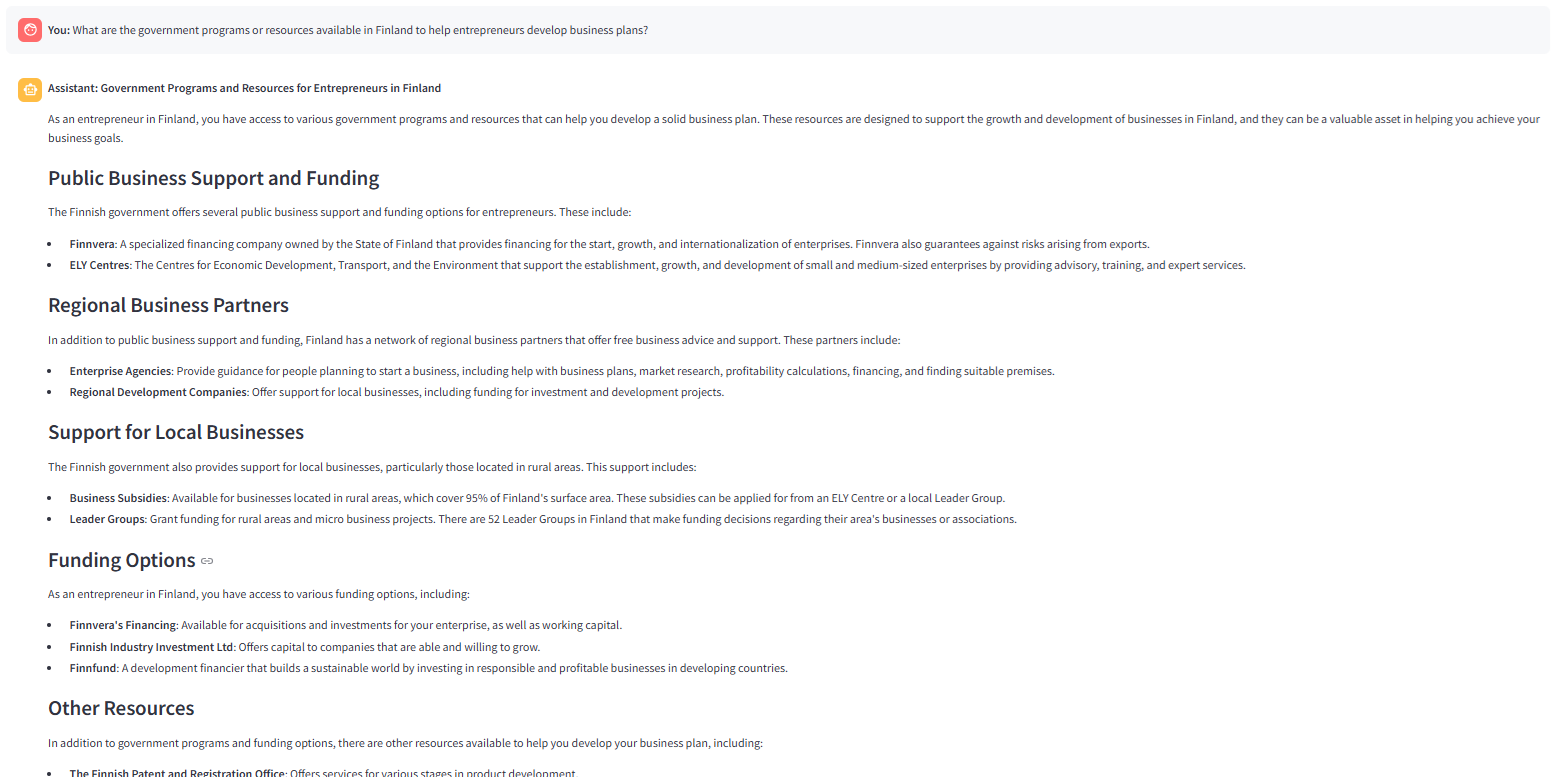
The following image shows the answer generated by llama-3.3–70b-versatile with ‘concise’ answer style selected. The query router (_routequestion) invokes the retriever (vector search) and the grader function finds all the retrieved chunks relevant. Hence, a decision to generate the answer through generate node is taken by _route_aftergrading node.

The following image shows the answer to the same question using ‘explanatory‘ answer style. As instructed in _ragprompt, the LLM elaborates the answer with more explanations.
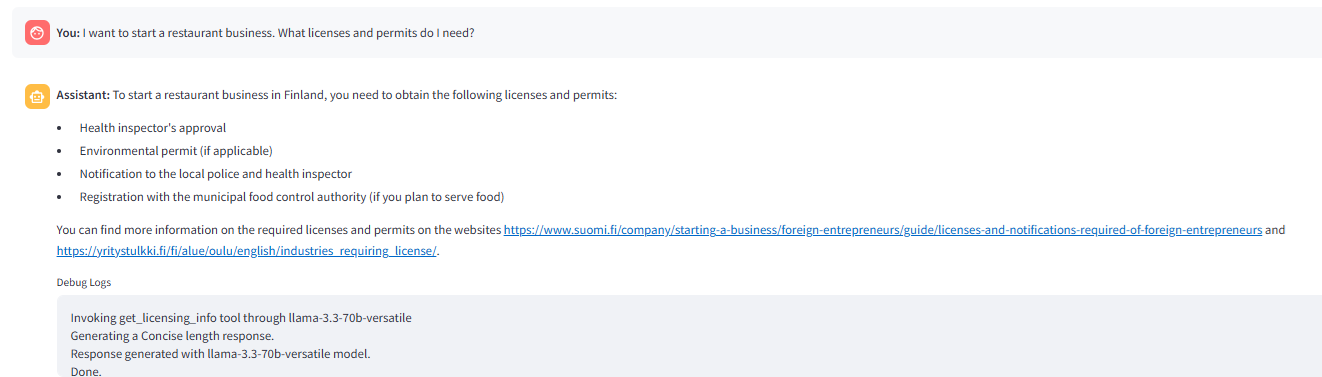
The following image shows the router triggering _get_licenseinfo tool in response to the question.
The following image shows a web search invoked by _route_aftergrading node when no relevant chunk is found in vector search.
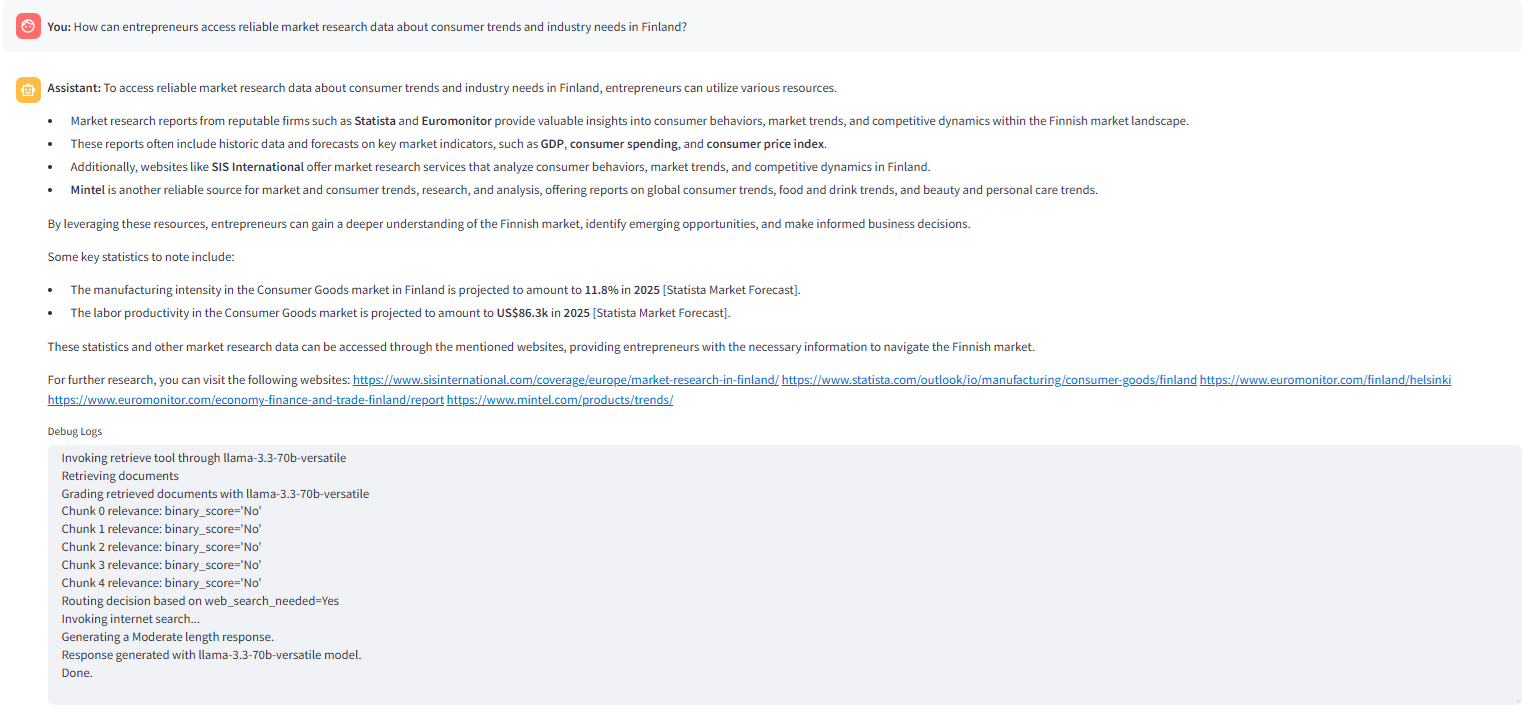
The following image shows the response generated with the hybrid search option selected in the Streamlit application. The _routequstion node finds the _internet_searchenabled state flag ‘True‘ and routes the question to _hybridsearch node.
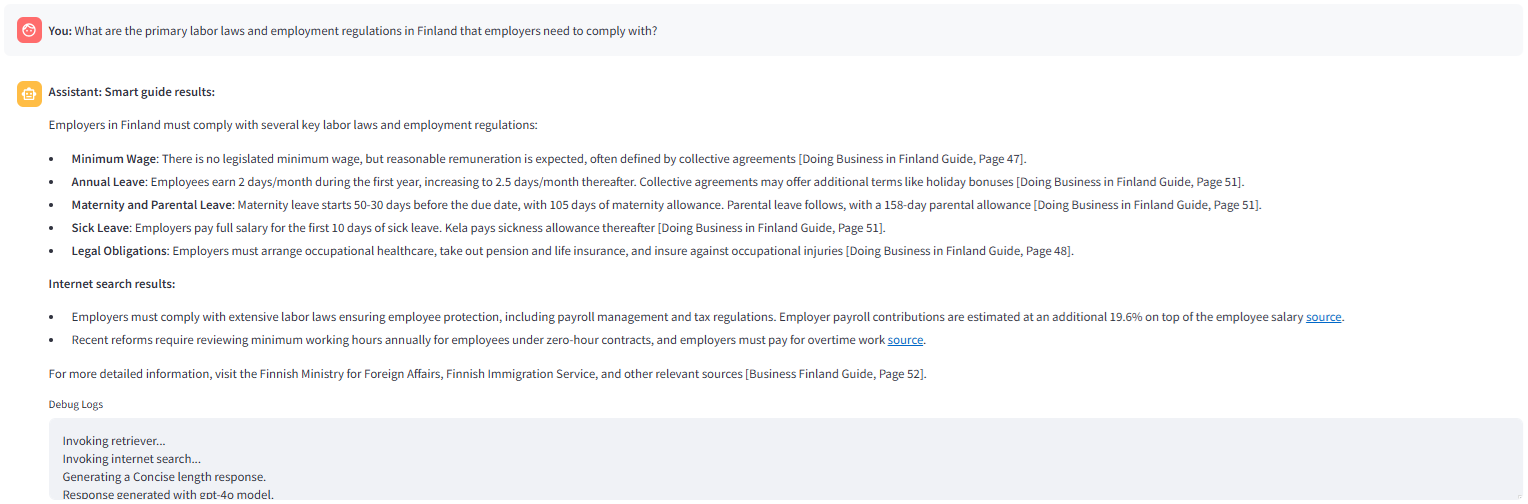
Directions for Extension
This application can be enhanced in several directions, e.g.,
- Voice-enabled search and question-answer in multiple languages (e.g., Russian, Estonian, Arabic, etc.)
- Selecting different parts of a response and asking for more information or explanation.
- Adding memory of the last n number of messages.
- Including other modalities (such as images) in question answers.
- Adding more agents for brainstorming, writing, and idea generation.
That’s all folks! If you liked the article, please clap the article (multiple times ? ), write a comment, and follow me on Medium and LinkedIn.
The above is the detailed content of Developing an AI-Powered Smart Guide for Business Planning & Entrepreneurship. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1243
24
14
1423
52
1317
25
1268
29
1243
24

 Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: A Leap Forward in Multimodal and Mobile AI Meta recently unveiled Llama 3.2, a significant advancement in AI featuring powerful vision capabilities and lightweight text models optimized for mobile devices. Building on the success o
 10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
Hey there, Coding ninja! What coding-related tasks do you have planned for the day? Before you dive further into this blog, I want you to think about all your coding-related woes—better list those down. Done? – Let’
 AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
This week's AI landscape: A whirlwind of advancements, ethical considerations, and regulatory debates. Major players like OpenAI, Google, Meta, and Microsoft have unleashed a torrent of updates, from groundbreaking new models to crucial shifts in le
 Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Shopify CEO Tobi Lütke's recent memo boldly declares AI proficiency a fundamental expectation for every employee, marking a significant cultural shift within the company. This isn't a fleeting trend; it's a new operational paradigm integrated into p
 GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
Introduction OpenAI has released its new model based on the much-anticipated “strawberry” architecture. This innovative model, known as o1, enhances reasoning capabilities, allowing it to think through problems mor
 A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Introduction Imagine walking through an art gallery, surrounded by vivid paintings and sculptures. Now, what if you could ask each piece a question and get a meaningful answer? You might ask, “What story are you telling?
 3 Methods to Run Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3 Methods to Run Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
Meta's Llama 3.2: A Multimodal AI Powerhouse Meta's latest multimodal model, Llama 3.2, represents a significant advancement in AI, boasting enhanced language comprehension, improved accuracy, and superior text generation capabilities. Its ability t
 Newest Annual Compilation Of The Best Prompt Engineering Techniques
Apr 10, 2025 am 11:22 AM
Newest Annual Compilation Of The Best Prompt Engineering Techniques
Apr 10, 2025 am 11:22 AM
For those of you who might be new to my column, I broadly explore the latest advances in AI across the board, including topics such as embodied AI, AI reasoning, high-tech breakthroughs in AI, prompt engineering, training of AI, fielding of AI, AI re
