

Unveiling the Magic Behind Large Language Models (LLMs): A Two-Part Exploration
Large Language Models (LLMs) often appear magical, but their inner workings are surprisingly systematic. This two-part series demystifies LLMs, explaining their construction, training, and refinement into the AI systems we use today. Inspired by Andrej Karpathy's insightful (and lengthy!) YouTube video, this condensed version provides the core concepts in a more accessible format. While Karpathy's video is highly recommended (800,000 views in just 10 days!), this 10-minute read distills the key takeaways from the first 1.5 hours.
Part 1: From Raw Data to Base Model
LLM development involves two crucial phases: pre-training and post-training.
1. Pre-training: Teaching the Language
Before generating text, an LLM must learn language structure. This computationally intensive pre-training process involves several steps:
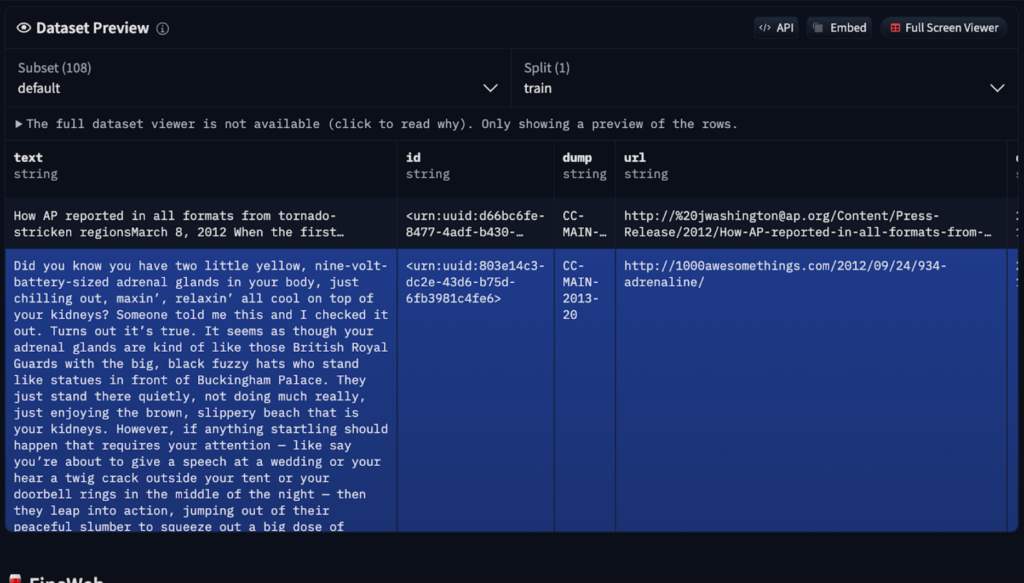
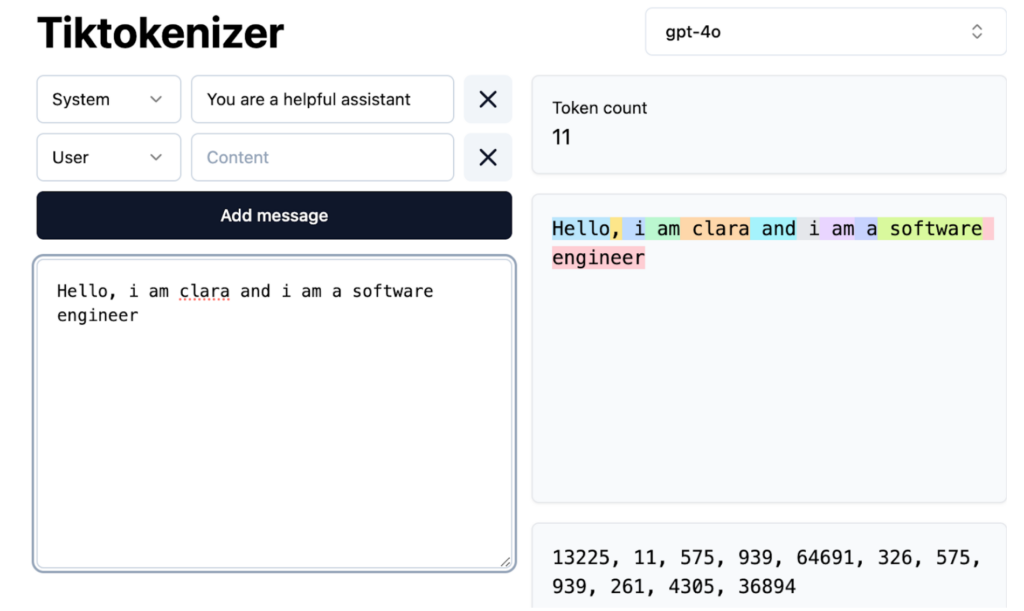
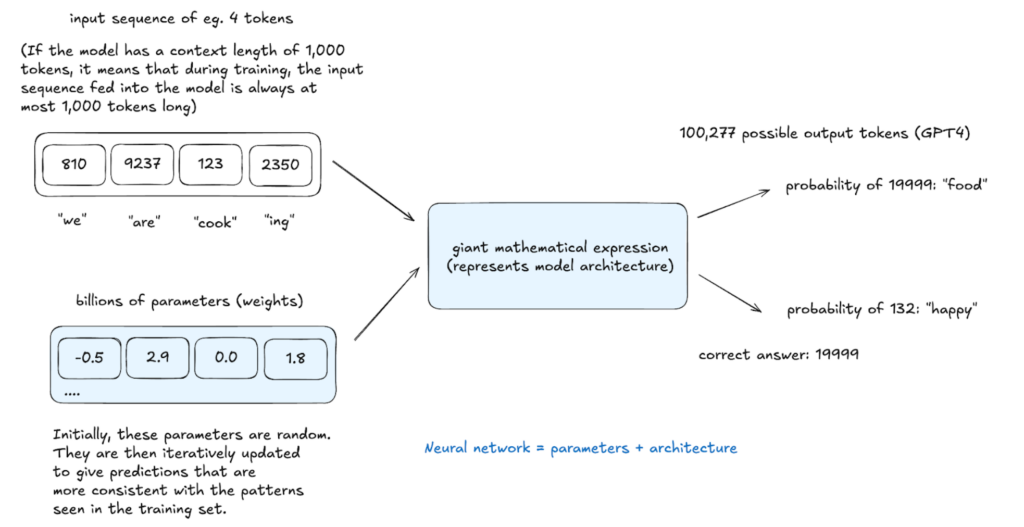
The resulting base model understands word relationships and statistical patterns but lacks real-world task optimization. It functions like an advanced autocomplete, predicting based on probability but with limited instruction-following capabilities. In-context learning, using examples within prompts, can be employed, but further training is necessary.
2. Post-training: Refining for Practical Use
Base models are refined through post-training using smaller, specialized datasets. This isn't explicit programming but rather implicit instruction through structured examples.
Post-training methods include:
Special tokens are introduced to delineate user input and AI responses.
Inference: Generating Text
Inference, performed at any stage, evaluates model learning. The model assigns probabilities to potential next tokens and samples from this distribution, creating text not explicitly in the training data but statistically consistent with it. This stochastic process allows for varied outputs from the same input.
Hallucinations: Addressing False Information
Hallucinations, where LLMs generate false information, arise from their probabilistic nature. They don't "know" facts but predict likely word sequences. Mitigation strategies include:
LLMs access knowledge through vague recollections (patterns from pre-training) and working memory (information in the context window). System prompts can establish a consistent model identity.
Conclusion (Part 1)
This part explored the foundational aspects of LLM development. Part 2 will delve into reinforcement learning and examine cutting-edge models. Your questions and suggestions are welcome!
The above is the detailed content of How LLMs Work: Pre-Training to Post-Training, Neural Networks, Hallucinations, and Inference. For more information, please follow other related articles on the PHP Chinese website!
 Recommended computer hardware testing software rankings
Recommended computer hardware testing software rankings
 Derivative symbol input method
Derivative symbol input method
 Free website domain name
Free website domain name
 Ranking of the top ten formal trading platforms
Ranking of the top ten formal trading platforms
 Linux batch modification file name suffix
Linux batch modification file name suffix
 cdr file opening method
cdr file opening method
 Introduction to the main work content of the backend
Introduction to the main work content of the backend
 route add command introduction
route add command introduction








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



