

DeepSeek's groundbreaking open-source release: FlashMLA, a CUDA kernel accelerating LLMs. This optimized multi-latent attention (MLA) decoding kernel, specifically designed for Hopper GPUs, significantly boosts the speed and efficiency of AI model hosting. Key improvements include BF16 support and a paged KV cache (64-block size), resulting in impressive performance benchmarks.
? Day 1 of #OpenSourceWeek: FlashMLA
DeepSeek proudly unveils FlashMLA, a high-efficiency MLA decoding kernel for Hopper GPUs. Optimized for variable-length sequences and now in production.
✅ BF16 support
✅ Paged KV cache (block size 64)
⚡ 3000 GB/s memory-bound & 580 TFLOPS…— DeepSeek (@deepseek_ai) February 24, 2025
Key Features:
These optimizations achieve up to 3000 GB/s memory bandwidth and 580 TFLOPS in computation-bound scenarios on H800 SXM5 GPUs using CUDA 12.6. This dramatically improves AI inference performance. Previously used in DeepSeek Models, FlashMLA now accelerates DeepSeek AI's R1 V3.
Table of Contents:
What is FlashMLA?
FlashMLA is a highly optimized MLA decoding kernel built for NVIDIA Hopper GPUs. Its design prioritizes speed and efficiency, reflecting DeepSeek's commitment to scalable AI model acceleration.
Hardware and Software Requirements:
Performance Benchmarks:
FlashMLA demonstrates exceptional performance:
This superior performance makes FlashMLA ideal for demanding AI workloads.
Understanding Multi-head Latent Attention (MLA)
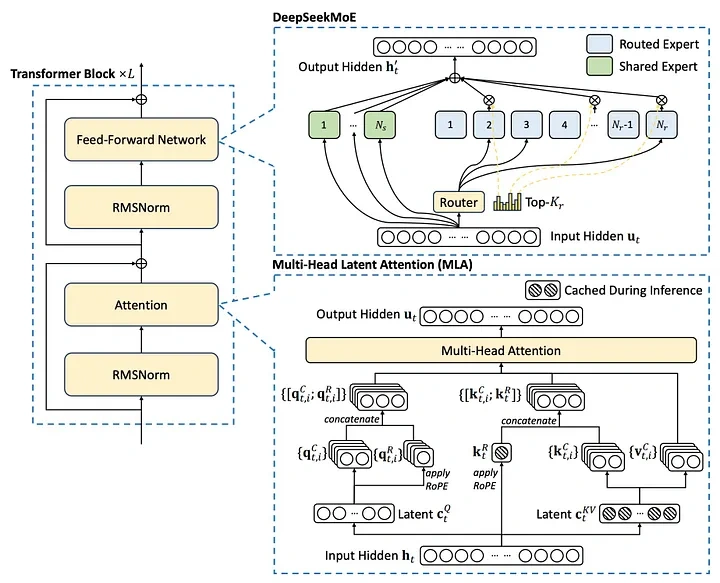
MLA, introduced with DeepSeek-V2, addresses the memory limitations of standard multi-head attention (MHA) by using a low-rank factorized projection matrix. Unlike methods like Group-Query Attention, MLA improves performance while reducing memory overhead.
Standard Multi-Head Attention Limitations:
MHA's KV cache scales linearly with sequence length, creating a memory bottleneck for long sequences. The cache size is calculated as: seq_len * n_h * d_h (where n_h is the number of attention heads and d_h is the head dimension).
MLA's Memory Optimization:
MLA compresses keys and values into a smaller latent vector (c_t), reducing the KV cache size to seq_len * d_c (where d_c is the latent vector dimension). This significantly reduces memory usage (up to 93.3% reduction in DeepSeek-V2).
Key-Value Caching and Autoregressive Decoding
KV caching accelerates autoregressive decoding by reusing previously computed key-value pairs. However, this increases memory usage.
Addressing Memory Challenges:
Techniques like Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) mitigate the memory issues associated with KV caching.
FlashMLA's Role in DeepSeek Models:
FlashMLA powers DeepSeek's R1 and V3 models, enabling efficient large-scale AI applications.
NVIDIA Hopper Architecture

NVIDIA Hopper is a high-performance GPU architecture designed for AI and HPC workloads. Its innovations, such as the Transformer Engine and second-generation MIG, enable exceptional speed and scalability.
Performance Analysis and Implications
FlashMLA achieves 580 TFLOPS for BF16 matrix multiplication, more than double the H800 GPU's theoretical peak. This demonstrates highly efficient utilization of GPU resources.
Conclusion
FlashMLA represents a major advancement in AI inference efficiency, particularly for Hopper GPUs. Its MLA optimization, combined with BF16 support and paged KV caching, delivers remarkable performance improvements. This makes large-scale AI models more accessible and cost-effective, setting a new benchmark for model efficiency.
The above is the detailed content of DeepSeek Launches FlashMLA. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



