

This tutorial demonstrates fine-tuning the Llama 3.1-8b-It model for mental health sentiment analysis. We'll customize the model to predict patient mental health status from text data, merge the adapter with the base model, and deploy the complete model on the Hugging Face Hub. Crucially, remember that ethical considerations are paramount when using AI in healthcare; this example is for illustrative purposes only.
We'll cover accessing Llama 3.1 models via Kaggle, using the Transformers library for inference, and the fine-tuning process itself. A prior understanding of LLM fine-tuning (see our "An Introductory Guide to Fine-Tuning LLMs") is beneficial.

Image by Author
Understanding Llama 3.1
Llama 3.1, Meta AI's multilingual large language model (LLM), excels in language understanding and generation. Available in 8B, 70B, and 405B parameter versions, it's built on an auto-regressive architecture with optimized transformers. Trained on diverse public data, it supports eight languages and boasts a 128k context length. Its commercial license is readily accessible, and it outperforms several competitors in various benchmarks.
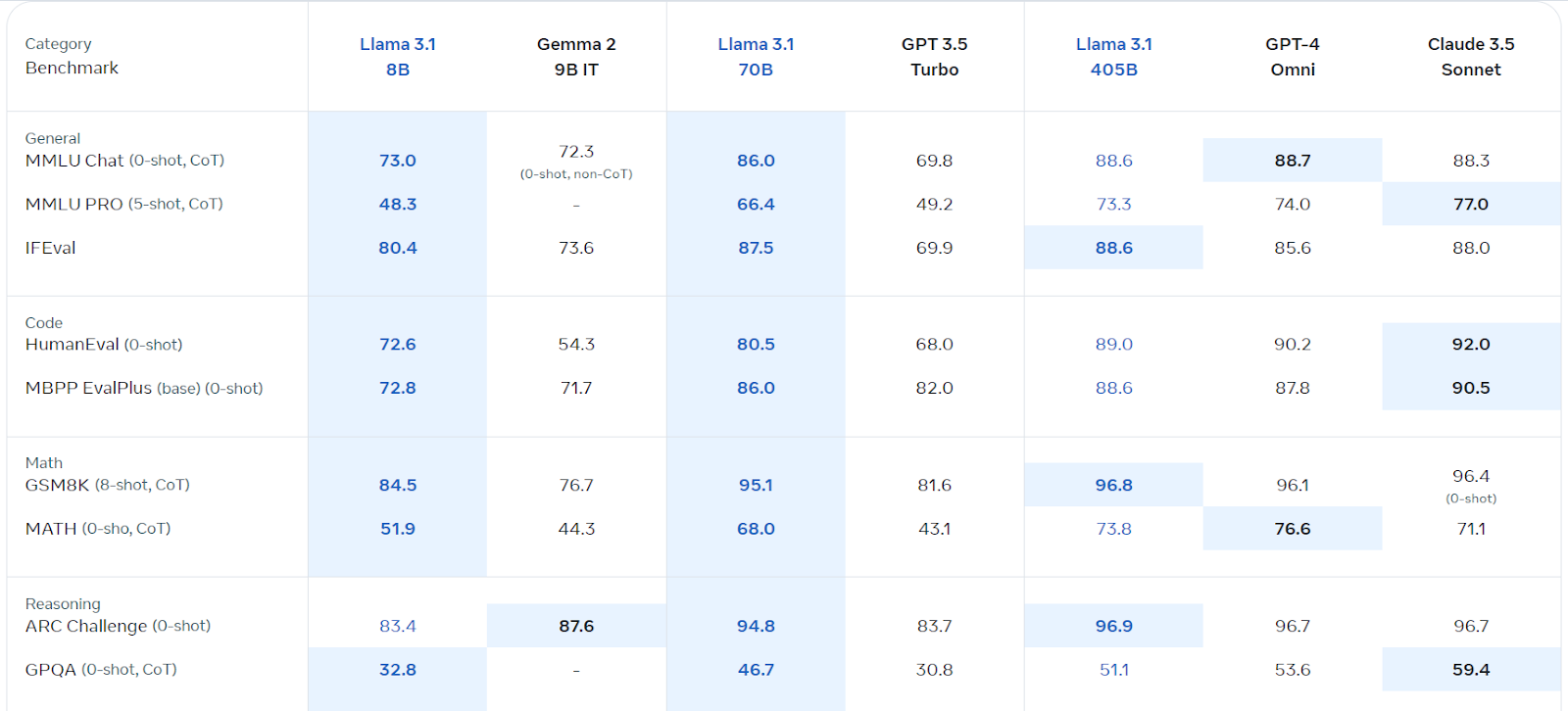
Source: Llama 3.1 (meta.com)
Accessing and Using Llama 3.1 on Kaggle
We'll leverage Kaggle's free GPUs/TPUs. Follow these steps:
%pip install -U transformers accelerate).from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model, return_dict=True, low_cpu_mem_usage=True, torch_dtype=torch.float16, device_map="auto", trust_remote_code=True)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.float16, device_map="auto")messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])
Fine-tuning Llama 3.1 for Mental Health Classification
Setup: Start a new Kaggle notebook with Llama 3.1, install required packages (bitsandbytes, transformers, accelerate, peft, trl), and add the "Sentiment Analysis for Mental Health" dataset. Configure Weights & Biases (using your API key).
Data Processing: Load the dataset, clean it (removing ambiguous categories: "Suicidal," "Stress," "Personality Disorder"), shuffle, and split into training, evaluation, and testing sets (using 3000 samples for efficiency). Create prompts incorporating statements and labels.
Model Loading: Load the Llama-3.1-8b-instruct model using 4-bit quantization for memory efficiency. Load the tokenizer and set the pad token ID.
Pre-Fine-tuning Evaluation: Create functions to predict labels and evaluate model performance (accuracy, classification report, confusion matrix). Assess the model's baseline performance before fine-tuning.
Fine-tuning: Configure LoRA using appropriate parameters. Set up training arguments (adjust as needed for your environment). Train the model using SFTTrainer. Monitor progress using Weights & Biases.
Post-Fine-tuning Evaluation: Re-evaluate the model's performance after fine-tuning.
Merging and Saving: In a new Kaggle notebook, merge the fine-tuned adapter with the base model using PeftModel.from_pretrained() and model.merge_and_unload(). Test the merged model. Save and push the final model and tokenizer to the Hugging Face Hub.
Remember to replace placeholders like /kaggle/input/... with your actual file paths. The complete code and detailed explanations are available in the original, longer response. This condensed version provides a high-level overview and key code snippets. Always prioritize ethical considerations when working with sensitive data.
The above is the detailed content of Fine-Tuning Llama 3.1 for Text Classification. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



