

Beam search: a deep dive into this powerful decoding algorithm
Beam search is a crucial decoding algorithm in natural language processing (NLP) and machine learning, particularly for sequence generation tasks like text generation, machine translation, and summarization. It effectively balances exploration of the search space with the generation of high-quality output. This article provides a comprehensive overview of beam search, including its mechanism, implementation, applications, and limitations.
Key Learning Objectives:
(This article is part of the Data Science Blogathon.)
Table of Contents:
Understanding Beam Search
Beam search is a heuristic search algorithm used to decode sequences from models such as transformers and LSTMs. It maintains a fixed number of the most probable sequences (the "beam width") at each step of the generation process. Unlike greedy search, which only considers the single most likely next token, beam search explores multiple possibilities concurrently, leading to more fluent and globally optimal outputs. In machine translation, for example, it allows the model to explore various valid translations simultaneously.
The Beam Search Mechanism
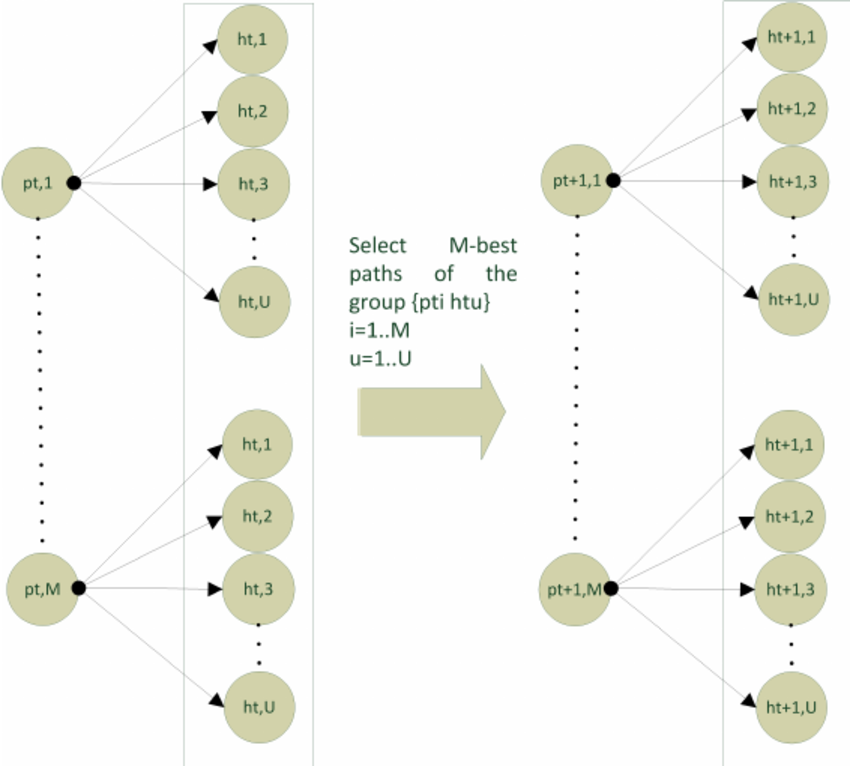
Beam search operates by traversing a graph where nodes represent tokens and edges represent transition probabilities. At each step:
The Concept of Beam Width
The beam width (k) is a critical parameter. A wider beam explores more sequences, potentially improving output quality, but significantly increases computational cost. A narrower beam is faster but risks missing superior sequences.
The Importance of Beam Search in Decoding
Beam search is crucial for decoding because:
Practical Python Implementation
The following provides a simplified implementation demonstrating the core principles. A more robust implementation would require error handling and potentially more sophisticated probability calculations.
(Note: The code sections and outputs below are reproduced from the original article and assume the necessary libraries are installed. Refer to the original article for complete installation instructions and detailed explanations.)
(Step 1: Install and Import Dependencies)
<code># Install transformers and graphviz !sudo apt-get install graphviz graphviz-dev !pip install transformers pygraphviz from transformers import GPT2LMHeadModel, GPT2Tokenizer import torch import matplotlib.pyplot as plt import networkx as nx import numpy as np from matplotlib.colors import LinearSegmentedColormap from tqdm import tqdm import matplotlib.colors as mcolors</code>
(Step 2: Model and Tokenizer Setup)
<code># Load model and tokenizer
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = GPT2LMHeadModel.from_pretrained('gpt2').to(device)
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model.eval()</code>(Step 3-8: Remaining code sections for encoding input, helper functions, recursive beam search, best sequence retrieval, and graph plotting are reproduced from the original article.)
(Output examples are also reproduced from the original article.)
Challenges and Limitations of Beam Search
Despite its strengths, beam search has limitations:
Conclusion
Beam search is a fundamental algorithm in modern NLP, providing a balance between efficiency and output quality. Its flexibility and ability to generate coherent sequences make it a valuable tool for various NLP applications. While challenges exist, its adaptability and effectiveness solidify its position as a cornerstone of sequence generation.
Frequently Asked Questions
(The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.)
The above is the detailed content of What is Beam Search in NLP Decoding?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



