

Recurrent Neural Network Tutorial (RNN)

Recurrent Neural Networks (RNNs): A Comprehensive Guide
Recurrent neural networks (RNNs) are a powerful type of artificial neural network (ANN) used in applications like Apple's Siri and Google's voice search. Their unique ability to retain past inputs through internal memory makes them ideal for tasks such as stock price prediction, text generation, transcription, and machine translation. Unlike traditional neural networks where inputs and outputs are independent, RNN outputs depend on previous elements in a sequence. Furthermore, RNNs share parameters across network layers, optimizing weight and bias adjustments during gradient descent.
The diagram above illustrates a basic RNN. In a stock price forecasting scenario using data like [45, 56, 45, 49, 50,...], each input (X0 to Xt) incorporates past values. For instance, X0 would be 45, X1 would be 56, and these values contribute to predicting the next sequence element.
How RNNs Function
In RNNs, information cycles through a loop, making the output a function of both the current and previous inputs.
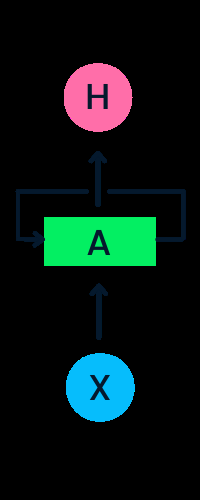
The input layer (X) processes the initial input, passing it to the middle layer (A), which comprises multiple hidden layers with activation functions, weights, and biases. These parameters are shared across the hidden layer, creating a single looped layer instead of multiple distinct layers. RNNs employ backpropagation through time (BPTT) instead of traditional backpropagation to compute gradients. BPTT sums errors at each time step due to the shared parameters.
Types of RNNs
RNNs offer flexibility in input and output lengths, unlike feedforward networks with single inputs and outputs. This adaptability allows RNNs to handle diverse tasks, including music generation, sentiment analysis, and machine translation. Four main types exist:
- One-to-one: A simple neural network suitable for single input/output problems.
- One-to-many: Processes a single input to generate multiple outputs (e.g., image captioning).
- Many-to-one: Takes multiple inputs to predict a single output (e.g., sentiment classification).
- Many-to-many: Handles multiple inputs and outputs (e.g., machine translation).
Recommended Machine Learning Courses
Learn more about RNNs for language modeling
Explore Introduction to Deep Learning in Python
CNNs vs. RNNs
Convolutional neural networks (CNNs) are feedforward networks processing spatial data (like images), commonly used in computer vision. Simple neural networks struggle with image pixel dependencies, while CNNs, with their convolutional, ReLU, pooling, and fully connected layers, excel in this area.
Key Differences:
- CNNs handle sparse data (images), while RNNs manage time series and sequential data.
- CNNs use standard backpropagation, RNNs use BPTT.
- CNNs have finite inputs/outputs; RNNs are flexible.
- CNNs are feedforward; RNNs use loops for sequential data.
- CNNs are used for image/video processing; RNNs for speech/text analysis.
RNN Limitations
Simple RNNs face two primary challenges related to gradients:
- Vanishing Gradient: Gradients become too small, hindering parameter updates and learning.
- Exploding Gradient: Gradients become excessively large, causing model instability and longer training times.
Solutions include reducing hidden layers or using advanced architectures like LSTM and GRU.
Advanced RNN Architectures
Simple RNNs suffer from short-term memory limitations. LSTM and GRU address this by enabling the retention of information over extended periods.
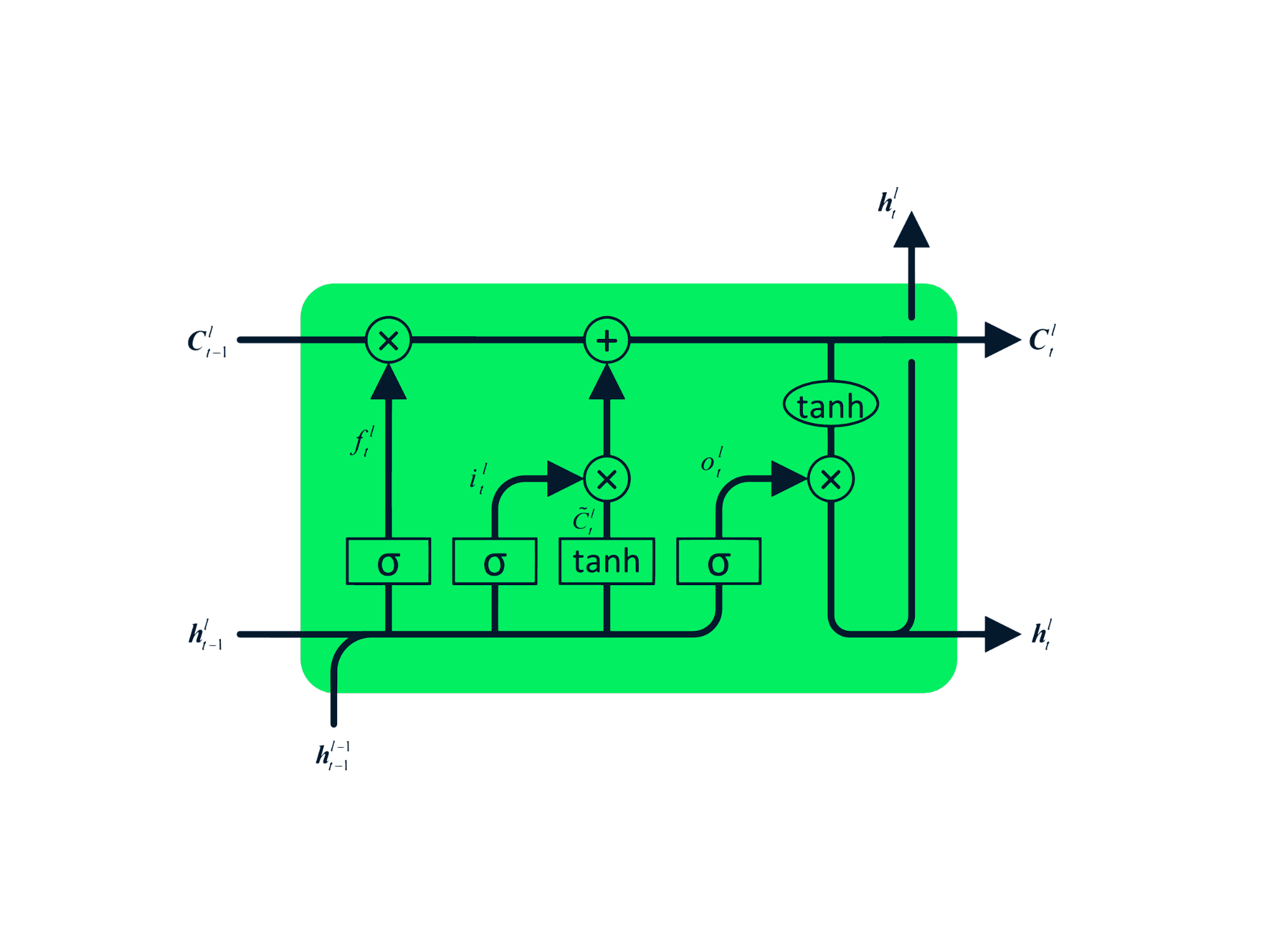
- Long Short-Term Memory (LSTM): An advanced RNN designed to mitigate vanishing/exploding gradients. Its four interacting layers facilitate long-term memory retention, making it suitable for machine translation, speech synthesis, and more.
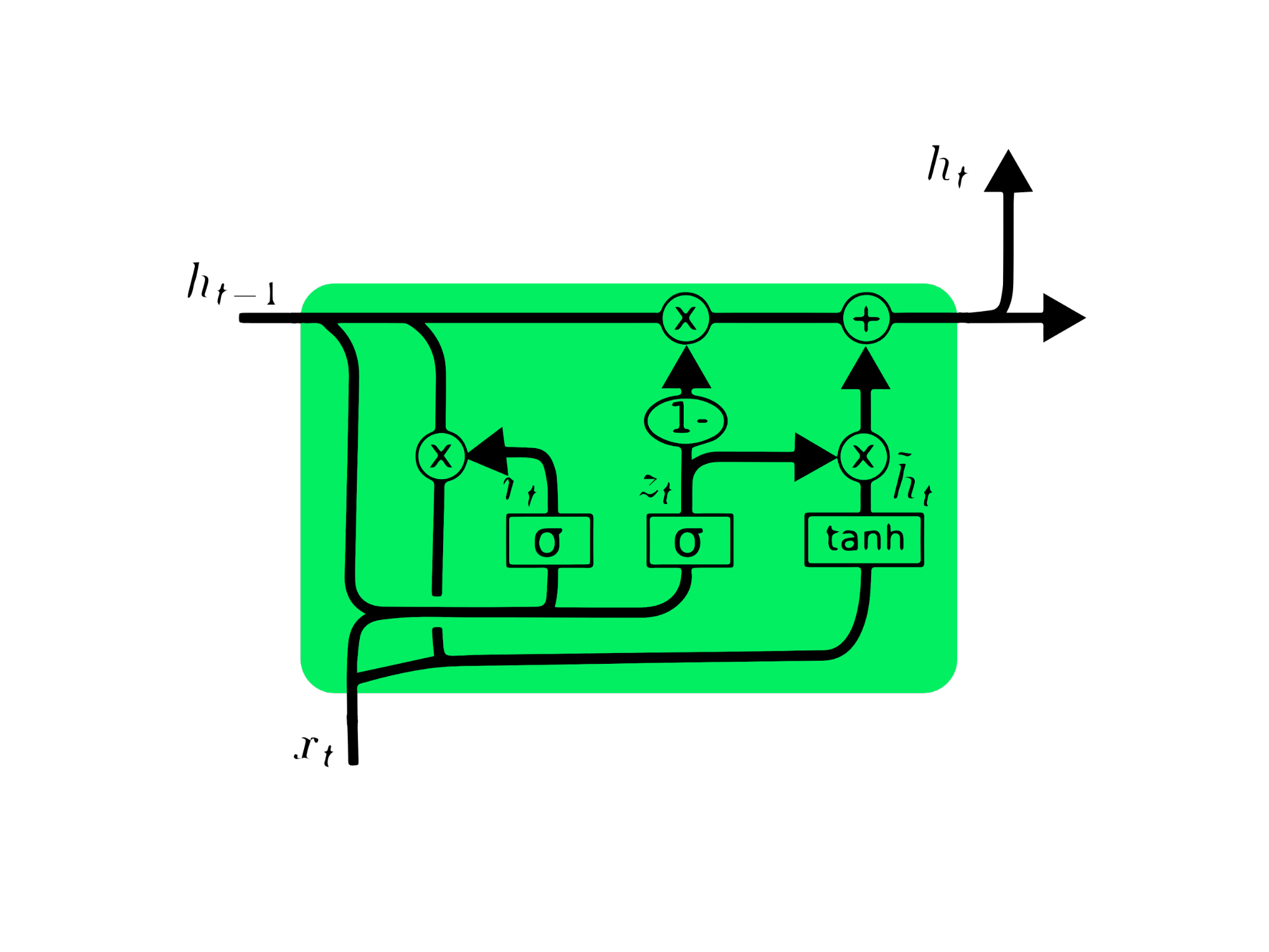
- Gated Recurrent Unit (GRU): A simpler variation of LSTM, using update and reset gates to manage information flow. Its streamlined architecture often leads to faster training compared to LSTM.
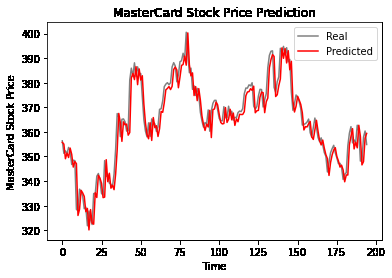
MasterCard Stock Price Prediction Using LSTM & GRU
This section details a project using LSTM and GRU to predict MasterCard stock prices. The code utilizes libraries like Pandas, NumPy, Matplotlib, scikit-learn, and TensorFlow.
(The detailed code example from the original input is omitted here for brevity. The core steps are summarized below.)
- Data Analysis: Import and clean the MasterCard stock dataset.
-
Data Preprocessing: Split the data into training and testing sets, scale using
MinMaxScaler, and reshape for model input. - LSTM Model: Build and train an LSTM model.
- LSTM Results: Evaluate the LSTM model's performance using RMSE.
- GRU Model: Build and train a GRU model with similar architecture.
- GRU Results: Evaluate the GRU model's performance using RMSE.
- Conclusion: Compare the performance of LSTM and GRU models.

Conclusion
Hybrid CNN-RNN networks are increasingly used for tasks requiring both spatial and temporal understanding. This tutorial provided a foundational understanding of RNNs, their limitations, and solutions offered by advanced architectures like LSTM and GRU. The project demonstrated the application of LSTM and GRU for stock price prediction, highlighting GRU's superior performance in this specific case. The complete project is available on the DataCamp workspace.
Remember to replace https://www.php.cn/link/cc6a6632b380f3f6a1c54b1222cd96c2 and https://www.php.cn/link/8708107b2ff5de15d0244471ae041fdb with actual links to the relevant courses. The image URLs are assumed to be correct and accessible.
The above is the detailed content of Recurrent Neural Network Tutorial (RNN). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: A Leap Forward in Multimodal and Mobile AI Meta recently unveiled Llama 3.2, a significant advancement in AI featuring powerful vision capabilities and lightweight text models optimized for mobile devices. Building on the success o
 Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
The article compares top AI chatbots like ChatGPT, Gemini, and Claude, focusing on their unique features, customization options, and performance in natural language processing and reliability.
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
The article discusses top AI writing assistants like Grammarly, Jasper, Copy.ai, Writesonic, and Rytr, focusing on their unique features for content creation. It argues that Jasper excels in SEO optimization, while AI tools help maintain tone consist
 Top 7 Agentic RAG System to Build AI Agents
Mar 31, 2025 pm 04:25 PM
Top 7 Agentic RAG System to Build AI Agents
Mar 31, 2025 pm 04:25 PM
2024 witnessed a shift from simply using LLMs for content generation to understanding their inner workings. This exploration led to the discovery of AI Agents – autonomous systems handling tasks and decisions with minimal human intervention. Buildin
 Choosing the Best AI Voice Generator: Top Options Reviewed
Apr 02, 2025 pm 06:12 PM
Choosing the Best AI Voice Generator: Top Options Reviewed
Apr 02, 2025 pm 06:12 PM
The article reviews top AI voice generators like Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson, and Descript, focusing on their features, voice quality, and suitability for different needs.
 AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
This week's AI landscape: A whirlwind of advancements, ethical considerations, and regulatory debates. Major players like OpenAI, Google, Meta, and Microsoft have unleashed a torrent of updates, from groundbreaking new models to crucial shifts in le
