

Handling missing data is a crucial step in data analysis and machine learning. Missing values, stemming from various sources like data entry errors or inherent data limitations, can severely impact analysis accuracy and model reliability. Pandas, a powerful Python library, provides the fillna() method—a versatile tool for effective missing data imputation. This method allows replacing missing values with various strategies, ensuring data completeness for analysis.

Table of Contents
fillna()fillna() Syntaxfillna()What is Data Imputation?
Data imputation is the technique of filling in missing data points within a dataset. Missing data poses significant challenges for many analytical methods and machine learning algorithms that require complete datasets. Imputation addresses this by estimating and replacing missing values with plausible substitutes based on the available data.
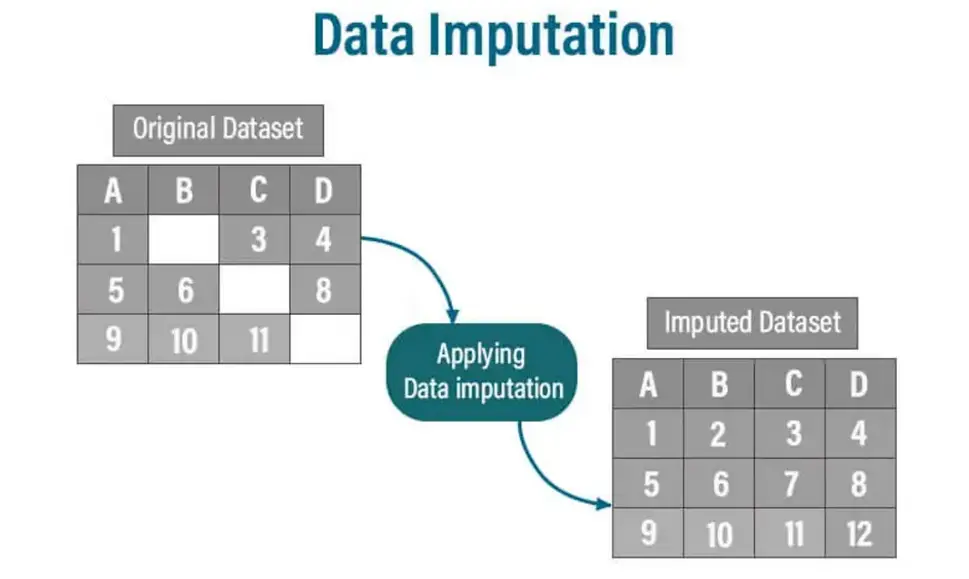
Why is Data Imputation Important?
Several key reasons highlight the importance of data imputation:
Understanding Pandas fillna()
The Pandas fillna() method is designed to replace NaN (Not a Number) values in DataFrames or Series. It offers various imputation strategies.
fillna() Syntax

Key parameters include value (the replacement value), method (e.g., 'ffill' for forward fill, 'bfill' for backward fill), axis, inplace, limit, and downcast.
Using fillna() for Different Imputation Techniques
Several imputation techniques can be implemented using fillna():
(Code examples for each technique would be included here, mirroring the structure and content of the original text's code examples.)
Conclusion
Effective missing data handling is vital for reliable data analysis and machine learning. Pandas' fillna() method offers a powerful and flexible solution, providing a range of imputation strategies to suit different data types and contexts. Choosing the right method depends on the dataset's characteristics and the analysis goals.
Frequently Asked Questions
(The FAQs section would be retained, mirroring the original text's content.)
The above is the detailed content of Pandas fillna() for Data Imputation. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



