

Memory-Efficient Model Weight Loading in PyTorch

This blog post explores efficient memory management techniques for loading large PyTorch models, especially beneficial when dealing with limited GPU or CPU resources. The author focuses on scenarios where models are saved using torch.save(model.state_dict(), "model.pth"). While the examples use a large language model (LLM), the techniques are applicable to any PyTorch model.
Key Strategies for Efficient Model Loading:
The article details several methods to optimize memory usage during model loading:
-
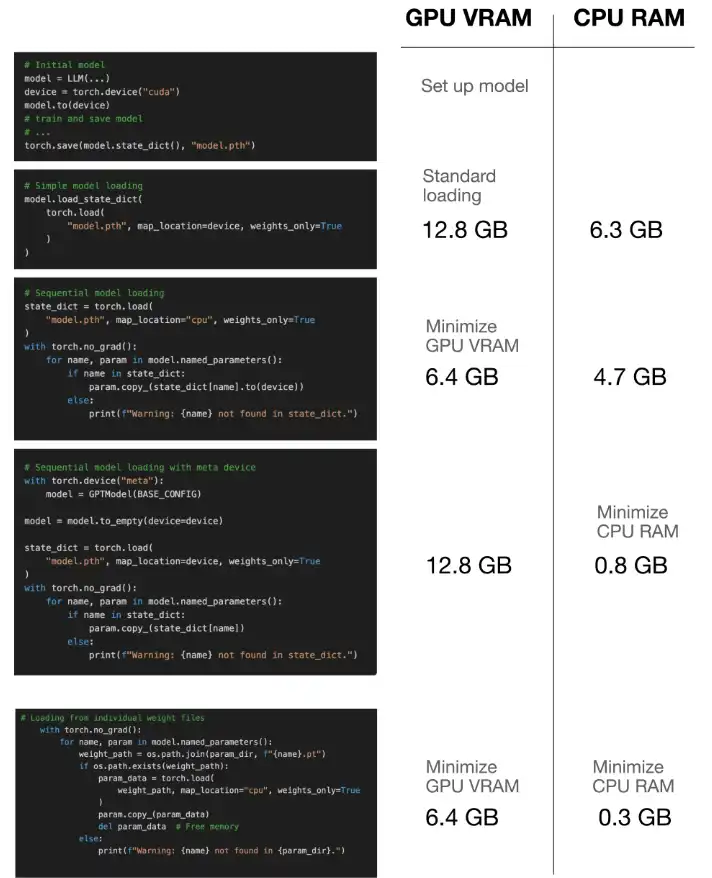
Sequential Weight Loading: This technique loads the model architecture onto the GPU and then iteratively copies individual weights from CPU memory to the GPU. This prevents the simultaneous presence of both the full model and weights in GPU memory, significantly reducing peak memory consumption.
-
Meta Device: PyTorch's "meta" device enables tensor creation without immediate memory allocation. The model is initialized on the meta device, then transferred to the GPU, and weights are loaded directly onto the GPU, minimizing CPU memory usage. This is particularly useful for systems with limited CPU RAM.
-
mmap=Trueintorch.load(): This option uses memory-mapped file I/O, allowing PyTorch to read model data directly from disk on demand, rather than loading everything into RAM. This is ideal for systems with limited CPU memory and fast disk I/O. -
Individual Weight Saving and Loading: As a last resort for extremely limited resources, the article suggests saving each model parameter (tensor) as a separate file. Loading then occurs one parameter at a time, minimizing the memory footprint at any given moment. This comes at the cost of increased I/O overhead.
Practical Implementation and Benchmarking:
The post provides Python code snippets demonstrating each technique, including utility functions for tracking GPU and CPU memory usage. These benchmarks illustrate the memory savings achieved by each method. The author compares the memory usage of each approach, highlighting the trade-offs between memory efficiency and potential performance impacts.
Conclusion:
The article concludes by emphasizing the importance of memory-efficient model loading, especially for large models. It recommends selecting the most appropriate technique based on the specific hardware limitations (CPU RAM, GPU VRAM) and I/O speeds. The mmap=True approach is generally preferred for limited CPU RAM, while individual weight loading is a last resort for extremely constrained environments. The sequential loading method offers a good balance for many scenarios.
The above is the detailed content of Memory-Efficient Model Weight Loading in PyTorch. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
The article discusses AI models surpassing ChatGPT, like LaMDA, LLaMA, and Grok, highlighting their advantages in accuracy, understanding, and industry impact.(159 characters)
 How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
Mistral OCR: Revolutionizing Retrieval-Augmented Generation with Multimodal Document Understanding Retrieval-Augmented Generation (RAG) systems have significantly advanced AI capabilities, enabling access to vast data stores for more informed respons
 Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
The article discusses top AI writing assistants like Grammarly, Jasper, Copy.ai, Writesonic, and Rytr, focusing on their unique features for content creation. It argues that Jasper excels in SEO optimization, while AI tools help maintain tone consist
