

When to Use GRUs Over LSTMs?

Recurrent Neural Networks: LSTM vs. GRU – A Practical Guide
I vividly recall encountering recurrent neural networks (RNNs) during my coursework. While sequence data initially captivated me, the myriad architectures quickly became confusing. The common advisor response, "It depends," only amplified my uncertainty. Extensive experimentation and numerous projects later, my understanding of when to use LSTMs versus GRUs has significantly improved. This guide aims to clarify the decision-making process for your next project. We'll delve into the details of LSTMs and GRUs to help you make an informed choice.
Table of Contents
- LSTM Architecture: Precise Memory Control
- GRU Architecture: Streamlined Design
- Performance Comparison: Strengths and Weaknesses
- Application-Specific Considerations
- A Practical Decision Framework
- Hybrid Approaches and Modern Alternatives
- Conclusion
LSTM Architecture: Precise Memory Control
Long Short-Term Memory (LSTM) networks, introduced in 1997, address the vanishing gradient problem inherent in traditional RNNs. Their core is a memory cell capable of retaining information over extended periods, managed by three gates:
- Forget Gate: Determines which information to discard from the cell state.
- Input Gate: Selects which values to update in the cell state.
- Output Gate: Controls which parts of the cell state are outputted.
This granular control over information flow enables LSTMs to capture long-range dependencies within sequences.

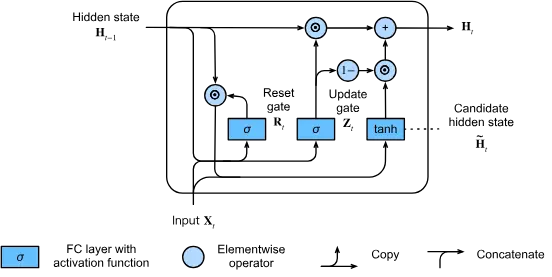
GRU Architecture: Streamlined Design
Gated Recurrent Units (GRUs), presented in 2014, simplify the LSTM architecture while retaining much of its effectiveness. GRUs utilize only two gates:
- Reset Gate: Defines how to integrate new input with existing memory.
- Update Gate: Governs which information to retain from previous steps and what to update.
This streamlined design results in improved computational efficiency while still effectively mitigating the vanishing gradient problem.
Performance Comparison: Strengths and Weaknesses
Computational Efficiency
GRUs excel in:
- Resource-constrained projects.
- Real-time applications demanding rapid inference.
- Mobile or edge computing deployments.
- Processing larger batches and longer sequences on limited hardware.
GRUs typically train 20-30% faster than comparable LSTMs due to their simpler structure and fewer parameters. In a recent text classification project, a GRU model trained in 2.4 hours compared to an LSTM's 3.2 hours—a substantial difference during iterative development.

Handling Long Sequences
LSTMs are superior for:
- Extremely long sequences with intricate dependencies.
- Tasks requiring precise memory management.
- Situations where selective information forgetting is crucial.
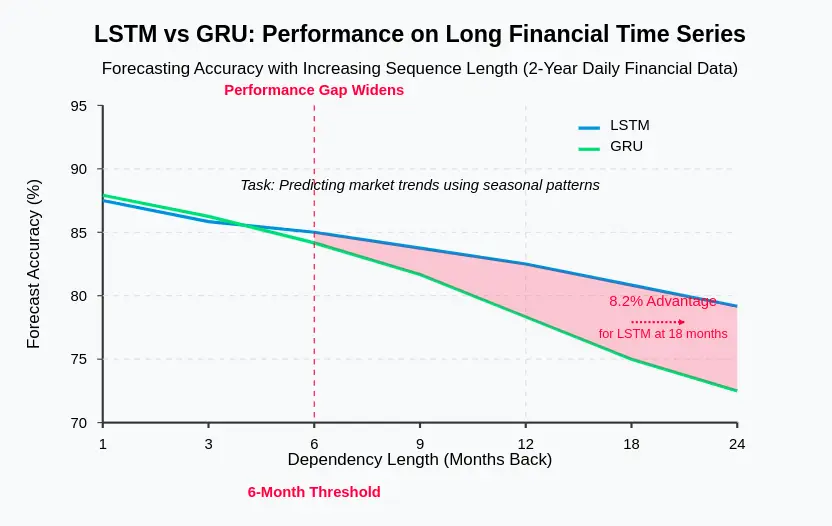
In financial time series forecasting using years of daily data, LSTMs consistently outperformed GRUs in predicting trends reliant on seasonal patterns from several months prior. The dedicated memory cell in LSTMs provides the necessary capacity for long-term information retention.
Training Stability
GRUs often demonstrate:
- Faster convergence.
- Reduced overfitting on smaller datasets.
- Improved efficiency in hyperparameter tuning.
GRUs frequently converge faster, sometimes reaching satisfactory performance with 25% fewer epochs than LSTMs. This accelerates experimentation and increases productivity.
Model Size and Deployment
GRUs are advantageous for:
- Memory-limited environments.
- Client-deployed models.
- Applications with stringent latency constraints.
A production LSTM language model for a customer service application required 42MB of storage, while the GRU equivalent needed only 31MB—a 26% reduction simplifying deployment to edge devices.
Application-Specific Considerations
Natural Language Processing (NLP)
For most NLP tasks with moderate sequence lengths (20-100 tokens), GRUs often perform comparably or better than LSTMs while training faster. However, for tasks involving very long documents or intricate language understanding, LSTMs may offer an advantage.
Time Series Forecasting
For forecasting with multiple seasonal patterns or very long-term dependencies, LSTMs generally excel. Their explicit memory cell effectively captures complex temporal patterns.

Speech Recognition
In speech recognition with moderate sequence lengths, GRUs often outperform LSTMs in terms of computational efficiency while maintaining comparable accuracy.
Practical Decision Framework
When choosing between LSTMs and GRUs, consider these factors:
- Resource Constraints: Are computational resources, memory, or deployment limitations a concern? (Yes → GRUs; No → Either)
- Sequence Length: How long are your input sequences? (Short-medium → GRUs; Very long → LSTMs)
- Problem Complexity: Does the task involve highly complex temporal dependencies? (Simple-moderate → GRUs; Complex → LSTMs)
- Dataset Size: How much training data is available? (Limited → GRUs; Abundant → Either)
- Experimentation Time: How much time is allocated for model development? (Limited → GRUs; Ample → Test both)


Hybrid Approaches and Modern Alternatives
Consider hybrid approaches: using GRUs for encoding and LSTMs for decoding, stacking different layer types, or ensemble methods. Transformer-based architectures have largely superseded LSTMs and GRUs for many NLP tasks, but recurrent models remain valuable for time series analysis and scenarios where attention mechanisms are computationally expensive.
Conclusion
Understanding the strengths and weaknesses of LSTMs and GRUs is key to selecting the appropriate architecture. Generally, GRUs are a good starting point due to their simplicity and efficiency. Only switch to LSTMs if evidence suggests a performance improvement for your specific application. Remember that effective feature engineering, data preprocessing, and regularization often have a greater impact on model performance than the choice between LSTMs and GRUs. Document your decision-making process and experimental results for future reference.
The above is the detailed content of When to Use GRUs Over LSTMs?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: A Leap Forward in Multimodal and Mobile AI Meta recently unveiled Llama 3.2, a significant advancement in AI featuring powerful vision capabilities and lightweight text models optimized for mobile devices. Building on the success o
 10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
Hey there, Coding ninja! What coding-related tasks do you have planned for the day? Before you dive further into this blog, I want you to think about all your coding-related woes—better list those down. Done? – Let’
 AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
This week's AI landscape: A whirlwind of advancements, ethical considerations, and regulatory debates. Major players like OpenAI, Google, Meta, and Microsoft have unleashed a torrent of updates, from groundbreaking new models to crucial shifts in le
 Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Shopify CEO Tobi Lütke's recent memo boldly declares AI proficiency a fundamental expectation for every employee, marking a significant cultural shift within the company. This isn't a fleeting trend; it's a new operational paradigm integrated into p
 GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
Introduction OpenAI has released its new model based on the much-anticipated “strawberry” architecture. This innovative model, known as o1, enhances reasoning capabilities, allowing it to think through problems mor
 A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Introduction Imagine walking through an art gallery, surrounded by vivid paintings and sculptures. Now, what if you could ask each piece a question and get a meaningful answer? You might ask, “What story are you telling?
 3 Methods to Run Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3 Methods to Run Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
Meta's Llama 3.2: A Multimodal AI Powerhouse Meta's latest multimodal model, Llama 3.2, represents a significant advancement in AI, boasting enhanced language comprehension, improved accuracy, and superior text generation capabilities. Its ability t
 Newest Annual Compilation Of The Best Prompt Engineering Techniques
Apr 10, 2025 am 11:22 AM
Newest Annual Compilation Of The Best Prompt Engineering Techniques
Apr 10, 2025 am 11:22 AM
For those of you who might be new to my column, I broadly explore the latest advances in AI across the board, including topics such as embodied AI, AI reasoning, high-tech breakthroughs in AI, prompt engineering, training of AI, fielding of AI, AI re
