
 Web Front-end
JS Tutorial
Javascript image processing—image morphology (expansion and erosion)_javascript skills
Web Front-end
JS Tutorial
Javascript image processing—image morphology (expansion and erosion)_javascript skills
Javascript image processing—image morphology (expansion and erosion)_javascript skills

In the previous article , we explained the threshold function in image processing. In this article we will do the expansion and corrosion functions.
Expansion and CorrosionThe concept may be difficult to explain. Let’s take a look at the pictures. The first is the original picture:

After expansion it will look like this:

After corrosion, it will look like this:

It may seem a little puzzling. It is obvious that it is expansion, but why the words become thinner, and it is obvious that it is corrosion, why does the word become thicker?
Actually, the so-called expansion should refer to :
Brighter color blocks expand.
The so-called corrosion should refer to :
Brighter color blocks corrode.
In the picture above, since the white background is a lighter color block, when it expands, it flattens the words on the darker black block... On the contrary, when it corrodes, the words absorb water and expand...
expressed as a mathematical formula is :
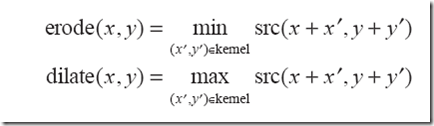
To put it bluntly, it is to find the darkest or brightest pixel in the kernel of a specified size, and replace the pixel on the kernel anchor point with this point.
Achieve
First we implement the expansion dilate function.
var dilate = function(__src, __size, __borderType, __dst ){
__src || error(arguments.callee, IS_UNDEFINED_OR_NULL/* {line} */);
if(__src.type && __src.type == "CV_RGBA"){
var width = __src .col,
height = __src.row,
size = __size || 3,
dst = __dst || new Mat(height, width, CV_RGBA),
dstData = dst.data;
var start = size >> 1;
var withBorderMat = copyMakeBorder(__src, start, start, 0, 0, __borderType),
mData = withBorderMat.data,
mWidth = withBorderMat.col;
var newOffset, total, nowX, offsetY, offsetI, nowOffset, i, j;
if(size & 1 === 0){
error(arguments .callee, UNSPPORT_SIZE/* {line} */);
return __src;
}
for(i = height; i--;){
offsetI = i * width;
for(j = width; j--;){
newOffset = 0;
total = 0;
for(y = size; y--;){
offsetY = ( y i) * mWidth * 4;
for(x = size; x--;){
nowX = (x j) * 4;
nowOffset = offsetY nowX;
(mData[nowOffset] mData [nowOffset 1] mData[nowOffset 2] > total) && (total = mData[nowOffset] mData[nowOffset 1] mData[nowOffset 2]) && (newOffset = nowOffset);
}
}
dstData[(j offsetI) * 4] = mData[newOffset];
dstData[(j offsetI) * 4 1] = mData[newOffset 1];
dstData[(j offsetI) * 4 2] = mData [newOffset 2];
dstData[(j offsetI) * 4 3] = mData[newOffset 3];
}
}
}else{
error(arguments.callee , UNSPPORT_DATA_TYPE/* {line} */);
}
return dst;
};
In this line of code, we first use the RGB value and the previous one Compare the maximum value total, and then if the new value is larger, assign the new value to total, and assign the new offset newOffset to the current offset nowOffset.
Then after the entire kernel-sized area is cycled, a maximum total and the corresponding offset newOffset can be found. You can assign the value:
dstData[(j offsetI) * 4] = mData[newOffset];
dstData[(j offsetI) * 4 1] = mData[newOffset 1];
dstData[(j offsetI) * 4 2 ] = mData[newOffset 2];
dstData[(j offsetI) * 4 3] = mData[newOffset 3];
Then the erosion function is the opposite, just find the smallest value.
var erode = function(__src, __size, __borderType, __dst){
__src || error(arguments.callee, IS_UNDEFINED_OR_NULL/* {line} */);
if(__src.type && __src.type == "CV_RGBA"){
var width = __src.col,
height = __src.row,
size = __size || 3,
dst = __dst || new Mat(height, width, CV_RGBA),
dstData = dst.data;
var start = size >> 1;
var withBorderMat = copyMakeBorder(__src, start, start, 0, 0, __borderType),
mData = withBorderMat.data,
mWidth = withBorderMat.col;
var newOffset, total, nowX, offsetY, offsetI, nowOffset, i, j;
if(size & 1 === 0){
error(arguments.callee, UNSPPORT_SIZE/* {line} */);
return __src;
}
for(i = height; i--;){
offsetI = i * width;
for(j = width; j--;){
newOffset = 0;
total = 765;
for(y = size; y--;){
offsetY = (y i) * mWidth * 4;
for(x = size; x--;){
nowX = (x j) * 4;
nowOffset = offsetY nowX;
(mData[nowOffset] mData[nowOffset 1] mData[nowOffset 2] < total) && (total = mData[nowOffset] mData[nowOffset 1] mData[nowOffset 2]) && (newOffset = nowOffset);
}
}
dstData[(j offsetI) * 4] = mData[newOffset];
dstData[(j offsetI) * 4 1] = mData[newOffset 1];
dstData[(j offsetI) * 4 2] = mData[newOffset 2];
dstData[(j offsetI) * 4 3] = mData[newOffset 3];
}
}
}else{
error(arguments.callee, UNSPPORT_DATA_TYPE/* {line} */);
}
return dst;
};
效果



Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1375
1375
 52
52

 How is Wasserstein distance used in image processing tasks?
Jan 23, 2024 am 10:39 AM
How is Wasserstein distance used in image processing tasks?
Jan 23, 2024 am 10:39 AM
Wasserstein distance, also known as EarthMover's Distance (EMD), is a metric used to measure the difference between two probability distributions. Compared with traditional KL divergence or JS divergence, Wasserstein distance takes into account the structural information between distributions and therefore exhibits better performance in many image processing tasks. By calculating the minimum transportation cost between two distributions, Wasserstein distance is able to measure the minimum amount of work required to transform one distribution into another. This metric is able to capture the geometric differences between distributions, thereby playing an important role in tasks such as image generation and style transfer. Therefore, the Wasserstein distance becomes the concept
 In-depth analysis of the working principles and characteristics of the Vision Transformer (VIT) model
Jan 23, 2024 am 08:30 AM
In-depth analysis of the working principles and characteristics of the Vision Transformer (VIT) model
Jan 23, 2024 am 08:30 AM
VisionTransformer (VIT) is a Transformer-based image classification model proposed by Google. Different from traditional CNN models, VIT represents images as sequences and learns the image structure by predicting the class label of the image. To achieve this, VIT divides the input image into multiple patches and concatenates the pixels in each patch through channels and then performs linear projection to achieve the desired input dimensions. Finally, each patch is flattened into a single vector, forming the input sequence. Through Transformer's self-attention mechanism, VIT is able to capture the relationship between different patches and perform effective feature extraction and classification prediction. This serialized image representation is
 How to use AI technology to restore old photos (with examples and code analysis)
Jan 24, 2024 pm 09:57 PM
How to use AI technology to restore old photos (with examples and code analysis)
Jan 24, 2024 pm 09:57 PM
Old photo restoration is a method of using artificial intelligence technology to repair, enhance and improve old photos. Using computer vision and machine learning algorithms, the technology can automatically identify and repair damage and flaws in old photos, making them look clearer, more natural and more realistic. The technical principles of old photo restoration mainly include the following aspects: 1. Image denoising and enhancement. When restoring old photos, they need to be denoised and enhanced first. Image processing algorithms and filters, such as mean filtering, Gaussian filtering, bilateral filtering, etc., can be used to solve noise and color spots problems, thereby improving the quality of photos. 2. Image restoration and repair In old photos, there may be some defects and damage, such as scratches, cracks, fading, etc. These problems can be solved by image restoration and repair algorithms
 Application of AI technology in image super-resolution reconstruction
Jan 23, 2024 am 08:06 AM
Application of AI technology in image super-resolution reconstruction
Jan 23, 2024 am 08:06 AM
Super-resolution image reconstruction is the process of generating high-resolution images from low-resolution images using deep learning techniques, such as convolutional neural networks (CNN) and generative adversarial networks (GAN). The goal of this method is to improve the quality and detail of images by converting low-resolution images into high-resolution images. This technology has wide applications in many fields, such as medical imaging, surveillance cameras, satellite images, etc. Through super-resolution image reconstruction, we can obtain clearer and more detailed images, which helps to more accurately analyze and identify targets and features in images. Reconstruction methods Super-resolution image reconstruction methods can generally be divided into two categories: interpolation-based methods and deep learning-based methods. 1) Interpolation-based method Super-resolution image reconstruction based on interpolation
 Java development: how to implement image recognition and processing
Sep 21, 2023 am 08:39 AM
Java development: how to implement image recognition and processing
Sep 21, 2023 am 08:39 AM
Java Development: A Practical Guide to Image Recognition and Processing Abstract: With the rapid development of computer vision and artificial intelligence, image recognition and processing play an important role in various fields. This article will introduce how to use Java language to implement image recognition and processing, and provide specific code examples. 1. Basic principles of image recognition Image recognition refers to the use of computer technology to analyze and understand images to identify objects, features or content in the image. Before performing image recognition, we need to understand some basic image processing techniques, as shown in the figure
 How to deal with image processing and graphical interface design issues in C# development
Oct 08, 2023 pm 07:06 PM
How to deal with image processing and graphical interface design issues in C# development
Oct 08, 2023 pm 07:06 PM
How to deal with image processing and graphical interface design issues in C# development requires specific code examples. Introduction: In modern software development, image processing and graphical interface design are common requirements. As a general-purpose high-level programming language, C# has powerful image processing and graphical interface design capabilities. This article will be based on C#, discuss how to deal with image processing and graphical interface design issues, and give detailed code examples. 1. Image processing issues: Image reading and display: In C#, image reading and display are basic operations. Can be used.N
 PHP study notes: face recognition and image processing
Oct 08, 2023 am 11:33 AM
PHP study notes: face recognition and image processing
Oct 08, 2023 am 11:33 AM
PHP study notes: Face recognition and image processing Preface: With the development of artificial intelligence technology, face recognition and image processing have become hot topics. In practical applications, face recognition and image processing are mostly used in security monitoring, face unlocking, card comparison, etc. As a commonly used server-side scripting language, PHP can also be used to implement functions related to face recognition and image processing. This article will take you through face recognition and image processing in PHP, with specific code examples. 1. Face recognition in PHP Face recognition is a
 Scale Invariant Features (SIFT) algorithm
Jan 22, 2024 pm 05:09 PM
Scale Invariant Features (SIFT) algorithm
Jan 22, 2024 pm 05:09 PM
The Scale Invariant Feature Transform (SIFT) algorithm is a feature extraction algorithm used in the fields of image processing and computer vision. This algorithm was proposed in 1999 to improve object recognition and matching performance in computer vision systems. The SIFT algorithm is robust and accurate and is widely used in image recognition, three-dimensional reconstruction, target detection, video tracking and other fields. It achieves scale invariance by detecting key points in multiple scale spaces and extracting local feature descriptors around the key points. The main steps of the SIFT algorithm include scale space construction, key point detection, key point positioning, direction assignment and feature descriptor generation. Through these steps, the SIFT algorithm can extract robust and unique features, thereby achieving efficient image processing.
