The data caching system was first introduced in jQuery 1.2. At that time, its event system copied the DE master's addEvent.js, but addEvent had a flaw in its implementation. It placed all event callbacks on EventTarget, which would cause Circular reference, if EventTarget is a window object, will cause global pollution. With the data caching system, in addition to avoiding these two risks, we can also effectively save intermediate variables generated by different methods, and these variables will be useful to methods of another module, decoupling the dependencies between methods. For jQuery, its event cloning and even its later queue implementation are inseparable from the caching system.
jQuery1.2 adds two new static methods in the core module, data and removeData. Needless to say, data is the same as other jQuery methods, combining reading and writing. jQuery's caching system puts all data on $.cache, and then assigns a UUID to each element node, document object and window object that needs to use the cache system. The property name of UUID is a random custom property, "jQuery" (new Date()).getTime(), and the value is an integer, increasing from zero. But UUID must always be attached to an object. If that object is a window, wouldn't it be global pollution? Therefore, when jQuery internally determines that it is a window object, it maps it to an empty object called windowData, and then adds the UUID to it. With UUID, when we access the cache system for the first time, we will open an empty object (cache body) in the $.cache object to place things related to the target object. This is a bit like opening a bank account, the value of UUID is the passbook. removeData will delete the data that no longer needs to be saved. If in the end, the data is deleted and it does not have any key-value pairs and becomes an empty object, jQuery will delete this object from $.cache and move it from the target object. Except UUID.
//jQuery1.2.3
var expando = "jQuery" (new Date()).getTime(), uuid = 0, windowData = {};
jQuery.extend({
cache: {},
data: function( elem, name, data ) {
elem = elem == window ? windowData : elem;//Special processing for window object
var id = elem[ expando ];
if ( !id ) //If not UUID creates a new one
id = elem[ expando ] = uuid;
//If there is no account opened in $.cache, open an account first
if ( name && !jQuery.cache[ id ] )
jQuery.cache[ id ] = {};
// When the third parameter is not undefined, it is a write operation
if ( data != undefined )
jQuery.cache[ id ][ name ] = data;
//If there is only one parameter, the cache object is returned, and if there are two parameters, the target data is returned
return name? jQuery.cache[ id ][ name ] : id;
},
removeData: function( elem, name ) {
elem = elem == window ? windowData : elem;
var id = elem[ expando ];
if ( name ) { //Remove target data
if ( jQuery.cache[ id ] ) {
delete jQuery.cache[ id ][ name ];
name = "";
for ( name in jQuery.cache[ id ] )
break;
//Traverse the cache body. If it is not empty, the name will be rewritten. If it is not rewritten, then !name is true,
//Thus Causes this method to be called again, but this time only one parameter is passed to remove the cache body,
if ( !name )
jQuery.removeData( elem );
}
} else {
//Remove UUID, but using delete on an element under IE will throw an error
try {
delete elem[ expando ];
} catch(e){
if ( elem.removeAttribute )
elem.removeAttribute( expando );
}//Cancel account
delete jQuery.cache[ id ];
}
}
})
jQuery added two prototype methods data and removeData with the same name in 1.2.3 to facilitate chain operations and centralized operations. And add the triggering logic of the custom events of getData and setData in data.
In 1.3, the data caching system was finally independent into a module data.js (division during internal development), and two sets of methods were added, queue and dequeue on the namespace, and queue and dequeue on the prototype. The purpose of queue is obvious, which is to cache a set of data to serve the animation module. Dequeue is to delete one item from a set of data.
//jQuery1.3
jQuery.extend({
queue: function( elem, type, data) {
if ( elem ){
type = (type || "fx") "queue";
var q = jQuery.data( elem, type );
if ( !q || jQuery.isArray(data) )//Make sure that an array is stored
q = jQuery.data( elem, type, jQuery.makeArray(data) );
else if( data )//Then add something to this data
q.push( data );
}
Return q;
},
dequeue: function( elem, type ){
var queue = jQuery.queue( elem, type ),
fn = queue.shift();//Then Delete one. In the early days, it was a callback for placing animations. If you delete it, it will be called.
// But it does not determine whether it is a function, and it is probably not written into the document. It is for internal use
if( ! type || type === "fx" )
fn = queue[0];
if( fn !== undefined )
fn.call(elem);
}
)
Example of calling the fx module animate method:
//each processes multiple animations in parallel, and queue processes multiple animations one after another
this[ optall.queue === false ? "each" : "queue " ](function(){ /*omitted*/})
Adding custom attributes on elements will also cause a problem. If we copy this element, this attribute will also be copied, resulting in both elements having the same UUID value and data being manipulated incorrectly. jQuery's early implementation of copying nodes is very simple. If the element's cloneNode method does not copy the event, use cloneNode. Otherwise, use the element's outerHTML or the parent node's innerHTML, and use the clean method to parse a new element. However, outerHTML and innerHTML will have explicit attributes written in them, so they need to be cleared using regular expressions.
//jQuery1.3.2 core.js clone method
var ret = this.map(function(){
if ( !jQuery.support.noCloneEvent && !jQuery.isXMLDoc(this) ) {
var html = this.outerHTML;
if ( !html ) {
var div = this.ownerDocument.createElement("div");
div.appendChild( this.cloneNode(true) );
html = div.innerHTML;
}
Return jQuery.clean([html.replace(/ jQueryd ="(?:d |null)"/g, "").replace(/^s*/, "")])[0];
} else
return this.cloneNode(true);
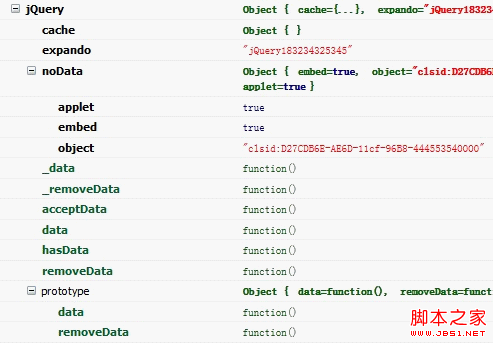
}); Tags imported into external resources may throw errors. Since the element nodes of the old IE are just COM wrappers, once a resource is introduced, it will become an instance of that resource, and they will have strict access control and cannot add members at will like ordinary JS objects. So jQuery changed it once and for all, no data will be cached for these three tags. jQuery created a hash called noData, which is used to detect the label of the element node.
"object": true,
"applet": true },
//Code Defense
if ( elem.nodeName && jQuery.noData[elem.nodeName.toLowerCase()] ) {
return ;
}
jQuery 1.4 also improves $.data, allowing the second parameter to be an object to facilitate the storage of multiple data. The custom attribute expando corresponding to UUID is also placed under the namespace. The queue and dequeue methods have been stripped out into a new module.
jQuery1.43 brings three improvements.
The first is to add the changeData custom method. However, this method has no sales, it is just the narcissism of the product manager.
The logic for detecting whether the element node supports adding custom attributes is separated into a method called acceptData. Because the jQuery team discovered that when the object tag loads the flash resource, it can still add custom attributes, so it decided to leave this situation open. When IE loads flash, it needs to specify an attribute called classId for the object. The value is clsid:D27CDB6E-AE6D-11cf-96B8-444553540000. Therefore, the detection logic becomes very complicated. Since data and removeData are both used, they are independent. Effectively save bits.
HTML5 responds to people's behavior of casually adding custom attributes by adding a new caching mechanism called "data-*". When the attributes set by the user start with "data-", they will be saved to the dataset object of the element node. This leads to people either using HTML5 to cache data, or using jQuery's caching system to save data, so the data method becomes a bit useless. So jQuery enhanced the data on the prototype. When the user accesses this element node for the first time, it will traverse all its custom attributes starting with "data-" (in order to take care of the old IE, the dataset cannot be traversed directly), and put them in jQuery's cache body. Then when the user retrieves data, it will first access the "data-" custom attribute from the cache system without using setAttribute. However, HTML5's caching system is very weak and can only save strings (this is of course due to circular reference considerations), so jQuery will restore them to various data types, such as "null", "false", "true" Becomes null, false, true. A string that conforms to the numeric format will be converted into a number. If it ends with "{" starting with "}", it will try to be converted into an object.
//jQuery1.43 $.fn.data
rbrace = /^(?:{.*}|[.*])$/;
if ( data === undefined && this.length ) {
data = jQuery.data( this[0] , key );
if ( data === undefined && this[0].nodeType === 1 ) {
data = this[0].getAttribute( "data-" key );
if ( typeof data === "string" ) {
try {
data = data === "true" ? true :
data === "false" ? false :
data === "null" ? null :
!jQuery.isNaN( data ) ? parseFloat( data ) :
rbrace.test( data ) ? jQuery.parseJSON( data ) :
data;
} catch( e) {}
} else {
data = undefined;
}
}
}
jQuery 1.5 also brings three improvements. At that time, jQuery had already defeated Prototype.js in 1.42. It was at its peak, and the number of users increased dramatically due to the Matthew effect. Its focus is changed to improving performance and entering the bug fixing stage (the more users, the more free testers, and the greater the test coverage).
Improve expando. It was originally based on time cutoff, but now it is version number plus random number. Therefore, users may introduce multiple versions of jQuery on one page.
The logic of whether there is this data is extracted into a hasData method, and the "data-*" attribute of HTML5 is also extracted into a private method dataAttr. They are all intended to make logic appear clearer. dataAttr uses JSON.parse, because this JSON may be introduced by JSON2.js, and JSON2.js has a very bad thing, that is, it adds a toJSON method for a series of native types, causing an error in the for in loop to determine whether it is an empty object. jQuery was forced to create an isEmptyDataObject method for processing.
jQuery’s data caching system was originally differentiated to serve the event system. Later, it became the infrastructure for many internal modules. In other words, it will internally store many variables for the framework users (system data), but once it is exposed to the document, users will also use data to store data used in their business (user data). In the past, there were only a small number of users, so the possibility of variable name conflicts was relatively small. In addition, jQuery carefully selected some uncommon names for these system data, such as __class__, __change__ or adding a suffix, etc., and no complaints were received. When jQuery became a world-class framework, it often happened that the user data name replaced the system data name, causing the event system or other modules to crash. jQuery began to transform the cache body. It turned out to be an object, and all data was thrown into it. Now it opens a sub-object in this cache with a random jQuery.expando value as the key name. If it is system data, it will be stored in it. However, for the sake of forward compatibility, the events system data is still placed directly in the cache. As for how to distinguish system data, it is very simple. Just add the fourth parameter directly to the data method. When the value is true, it is system data. The third parameter is also provided when removeData is used to delete system data. A new _data method has also been created, specifically for operating system data. The following is the structure diagram of the cache body:
var cache = {
jQuery14312343254:{/*Place system data*/}
events: {/"Place the event name and its corresponding callback list"/}
/*Place user data here*/
}
jQuery 1.7 has made improvements to the cache body. System variables have been placed in the data object. For this reason, corresponding improvements must be made when determining that the cache body is empty. Now we need to skip toJSON and data. The new structure is as follows:
var cache = {
data :{/*Place user data*/}
/*Place system data here*/
}
jQuery1.8 once added an array called deleteIds for reusing UUIDs. But it was short-lived. The UUID value no longer uses jQuery.uuid starting from 1.8, but is generated incrementally by jQuery.guid instead. A major improvement after jQuery 1.83, the implementation of operating data was extracted as a private method. The method on the namespace and prototype is just a proxy, and divided into two groups of methods, data for operating user data, removeData, and _data for operating system data. ,_removeData. Now the caching system alone is a huge family.

In the final analysis, data caching is to establish a one-to-one relationship between the target object and the cache body, and then operate the data on the cache body. The complexity is concentrated in the former. It has never been difficult to add, delete, modify or check a certain attribute in an ordinary JS object, and users can't do any tricks. From the perspective of software design principles, this is also the best result (in line with the KISS principle and the single responsibility principle).


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



