

ThinkPHP开始

ThinkPHP入门
1,ThinkPHP是什么?
ThinkPHP是一个免费开源的,快速、简单的面向对象的轻量级PHP开发框架,是为了敏捷WEB应用开发和简化企业应用开发而诞生的(1)从thinkphp.cn官网下载文件包
(2)解压之后目录文件介绍:
2,如何使用ThinkPHP?
创建控制器,动作
创建 GoodsAction.class.php文件
在此文件中,GoodsAction类 继承自 Action类
访问的时候,通过在url上添加参数 m=Goods&a=show
其中url上的m参数表示:
m----module 模块的意思
ThinkPHP在处理的时候,将一个控制器认为是一个模块
a----表示控制器(模块)的方法pathInfo模式
这种携带url参数的形式不是很美观,
ThinkPHP提供了一种新的访问方式
叫做pathInfo模式,
例如上面的请求可以写成:
而且ThinkPHP默认的url模式就是pathInfo模式
模型处理数据
(1)先找到当前的项目使用哪个数据库,通过配置文件完成配置文件在项目的Conf目录中的conf.php 完成一个数组即可(可以参考系统的默认配置)
(2)利用框架提供的M()函数获得模型,参数为当前的表名(注意首字母大写)
然后调用模型的select()方法 获得当前表的所有记录,相当于 getAll()
视图层显示数据
直接调用当前控制器的display()方法即可完成模板的显示
默认的display()是可以不带参数的,会自动在模板目录找当前需要的模板文件
命名的时候:Tpl/模块/动作.html
模板引擎循
利用ThinkPHP内置的模板引擎中的foreach完成循环
也是标签语法
数据标签是花括号{$data}; 数组是通过 . 来访问,也可以使用 [] 来访问

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Kimi: In just one sentence, in just ten seconds, a PPT will be ready. PPT is so annoying! To hold a meeting, you need to have a PPT; to write a weekly report, you need to have a PPT; to make an investment, you need to show a PPT; even when you accuse someone of cheating, you have to send a PPT. College is more like studying a PPT major. You watch PPT in class and do PPT after class. Perhaps, when Dennis Austin invented PPT 37 years ago, he did not expect that one day PPT would become so widespread. Talking about our hard experience of making PPT brings tears to our eyes. "It took three months to make a PPT of more than 20 pages, and I revised it dozens of times. I felt like vomiting when I saw the PPT." "At my peak, I did five PPTs a day, and even my breathing was PPT." If you have an impromptu meeting, you should do it
 All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
In the early morning of June 20th, Beijing time, CVPR2024, the top international computer vision conference held in Seattle, officially announced the best paper and other awards. This year, a total of 10 papers won awards, including 2 best papers and 2 best student papers. In addition, there were 2 best paper nominations and 4 best student paper nominations. The top conference in the field of computer vision (CV) is CVPR, which attracts a large number of research institutions and universities every year. According to statistics, a total of 11,532 papers were submitted this year, and 2,719 were accepted, with an acceptance rate of 23.6%. According to Georgia Institute of Technology’s statistical analysis of CVPR2024 data, from the perspective of research topics, the largest number of papers is image and video synthesis and generation (Imageandvideosyn
 There are several versions of thinkphp
Apr 09, 2024 pm 06:09 PM
There are several versions of thinkphp
Apr 09, 2024 pm 06:09 PM
ThinkPHP has multiple versions designed for different PHP versions. Major versions include 3.2, 5.0, 5.1, and 6.0, while minor versions are used to fix bugs and provide new features. The latest stable version is ThinkPHP 6.0.16. When choosing a version, consider the PHP version, feature requirements, and community support. It is recommended to use the latest stable version for best performance and support.
 From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
We know that LLM is trained on large-scale computer clusters using massive data. This site has introduced many methods and technologies used to assist and improve the LLM training process. Today, what we want to share is an article that goes deep into the underlying technology and introduces how to turn a bunch of "bare metals" without even an operating system into a computer cluster for training LLM. This article comes from Imbue, an AI startup that strives to achieve general intelligence by understanding how machines think. Of course, turning a bunch of "bare metal" without an operating system into a computer cluster for training LLM is not an easy process, full of exploration and trial and error, but Imbue finally successfully trained an LLM with 70 billion parameters. and in the process accumulate
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
Editor of the Machine Power Report: Yang Wen The wave of artificial intelligence represented by large models and AIGC has been quietly changing the way we live and work, but most people still don’t know how to use it. Therefore, we have launched the "AI in Use" column to introduce in detail how to use AI through intuitive, interesting and concise artificial intelligence use cases and stimulate everyone's thinking. We also welcome readers to submit innovative, hands-on use cases. Video link: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Recently, the life vlog of a girl living alone became popular on Xiaohongshu. An illustration-style animation, coupled with a few healing words, can be easily picked up in just a few days.
 Counting down the 12 pain points of RAG, NVIDIA senior architect teaches solutions
Jul 11, 2024 pm 01:53 PM
Counting down the 12 pain points of RAG, NVIDIA senior architect teaches solutions
Jul 11, 2024 pm 01:53 PM
Retrieval-augmented generation (RAG) is a technique that uses retrieval to boost language models. Specifically, before a language model generates an answer, it retrieves relevant information from an extensive document database and then uses this information to guide the generation process. This technology can greatly improve the accuracy and relevance of content, effectively alleviate the problem of hallucinations, increase the speed of knowledge update, and enhance the traceability of content generation. RAG is undoubtedly one of the most exciting areas of artificial intelligence research. For more details about RAG, please refer to the column article on this site "What are the new developments in RAG, which specializes in making up for the shortcomings of large models?" This review explains it clearly." But RAG is not perfect, and users often encounter some "pain points" when using it. Recently, NVIDIA’s advanced generative AI solution
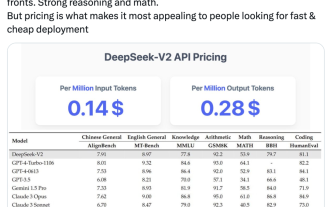 Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent
May 07, 2024 pm 05:34 PM
Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent
May 07, 2024 pm 05:34 PM
The latest large-scale domestic open source MoE model has become popular just after its debut. The performance of DeepSeek-V2 reaches GPT-4 level, but it is open source, free for commercial use, and the API price is only one percent of GPT-4-Turbo. Therefore, as soon as it was released, it immediately triggered a lot of discussion. Judging from the published performance indicators, DeepSeekV2's comprehensive Chinese capabilities surpass those of many open source models. At the same time, closed source models such as GPT-4Turbo and Wenkuai 4.0 are also in the first echelon. The comprehensive English ability is also in the same first echelon as LLaMA3-70B, and surpasses Mixtral8x22B, which is also a MoE. It also shows good performance in knowledge, mathematics, reasoning, programming, etc. And supports 128K context. Picture this
