

PHP正则表达式 不擒获

PHP正则表达式 不捕获
来源:http://www.iq662.com
替换
好了,现在终于到了解决3位或4位区号问题的时间了。正则表达式里的替换指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。听不明白?没关系,看例子:
0\d{2}-\d{8}|0\d{3}-\d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用替换|把这个表达式扩展成也支持4位区号的。
\d{5}-\d{4}|\d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用替换时,顺序是很重要的。如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配替换时,将会从左到右地测试每个条件,如果满足了某个条件的话,就不会去管其它的替换条件了。
Windows98|Windows2000|WindosXP这个例子是为了告诉你替换不仅仅能用于两种规则,也能用于更多种规则。
分组
我们已经提到了怎么重复单个字符;但如果想要重复一个字符串又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作(教程后面会有介绍)。
(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:\d{1,3}代表1到3位的数字,(\d{1,3}\.}{3}代表三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
不幸的是,它也将匹配256.300.888.999这种不可能存在的IP地址(IP地址中每个数字都不能大于255)。如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解这个表达式的关键是理解2[0-4]\d|25[0-5]|[01]?\d\d?,这里我就不细说了,你自己应该能分析得出来它的意义。
后向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:以分组的左括号为标志,从左向右,第一个分组的组号为1,第二个为2,以此类推。
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。难以理解?请看示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, kitty kitty。首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),然后是1个或几个空白符(\s+,最后是前面匹配的那个单词(\1)。
你也可以自己指定子表达式的组号或组名。要指定一个子表达式的组名,请使用这样的语法:(?
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的一些:
表4.分组语法 捕获
(exp) 匹配exp,并捕获文本到自动命名的组里
(?
(?:exp) 匹配exp,不捕获匹配的文本
位置指定
(?=exp) 匹配exp前面的位置
(?(?!exp) 匹配后面跟的不是exp的位置
(?注释
(?#comment) 这种类型的组不对正则表达式的处理产生任何影响,只是为了提供让人阅读注释
我们已经讨论了前两种语法。第三个(?:exp)不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像前两种那样被捕获到某个组里面。
位置指定
接下来的四个用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们用于指定一个位置,就像\b,^,$那样,因此它们也被称为零宽断言。最好还是拿例子来说明吧:
(?=exp)也叫零宽先行断言,它匹配文本中的某些位置,这些位置的后面能匹配给定的后缀exp。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如果在查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?
假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?
下面这个例子同时使用了前缀和后缀:(?
负向位置指定
前面我们提到过怎么查找不是某个字符或不在某个字符类里的字符的方法(反义)。但是如果我们只是想要确保某个字符没有出现,但并不想去匹配它时怎么办?例如,如果我们想查找这样的单词--它里面出现了字母q,但是q后面跟的不是字母u,我们可以尝试这样:
\b\w*q[^u]\w*\b匹配包含后面不是字母u的字母q的单词。但是如果多做测试(或者你思维足够敏锐,直接就观察出来了),你会发现,如果q出现在单词的结尾的话,像Iraq,Benq,这个表达式就会出错。这是因为[^u]总是匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[^u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),后面的\w+\b将会匹配下一个单词,于是\b\w*q[^u]\w*\b就能匹配整个Iraq fighting。负向位置指定能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。现在,我们可以这样来解决这个问题:\b\w*q(?!u)\w*\b。
零宽负向先行断言(?!exp),只会匹配后缀exp不存在的位置。\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字。
同理,我们可以用(?
一个更复杂的例子:(?).*(?=)匹配不包含属性的简单HTML标签内里的内容。((\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是),然后是.*(任意的字符串),最后是一个后缀(?=)。注意后缀里的\/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是的话,后缀就是了。整个表达式匹配的是和之间的内容(再次提醒,不包括前缀和后缀本身)。
注释
小括号的另一种用途是能过语法(?#comment)来包含注释。要包含注释的话,最好是启用“忽略模式里的空白符”选项,这样在编写表达式时能任意的添加空格,Tab,换行,而实际使用时这些都将被忽略。启用这个选项后,在#后面到这一行结束的所有文本都将被当成注释忽略掉。例如,我们可以把上一个表达式写成这样:
(? # 查找尖括号括起来的字母或数字(标签) ) # 前缀结束 .* # 匹配任意文本 (?= # 查找后缀,但不包含它 # 查找尖括号括起来的内容:前面是一个"/",后面是先前捕获的标签 ) # 后缀结束
贪婪与懒惰
当正则表达式中包含能接受重复的量词(指定数量的代码,例如*,{5,12}等)时,通常的行为是匹配尽可能多的字符。考虑这个表达式:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的量词都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab和ab。
表5.懒惰量词 *? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
还有些什么东西没提到
我已经描述了构造正则表达式的大量元素,还有一些我没有提到的东西。下面是未提到的元素的列表,包含语法和简单的说明。你可以在网上找到更详细的参考资料来学习它们--当你需要用到它们的时候。如果你安装了MSDN Library,你也可以在里面找到关于.net下正则表达式详细的文档。
表6.尚未讨论的语法 \a 报警字符(打印它的效果是电脑嘀一声)
\b 通常是单词分界位置,但如果在字符类里使用代表退格
\t 制表符,Tab
\r 回车
\v 竖向制表符
\f 换页符
\n 换行符
\e Escape
\0nn ASCII代码中八进制代码为nn的字符
\xnn ASCII代码中十六进制代码为nn的字符
\unnnn Unicode代码中十六进制代码为nnnn的字符
\cN ASCII控制字符。比如\cC代表Ctrl+C
\A 字符串开头(类似^,但不受处理多行选项的影响)
\Z 字符串结尾或行尾(不受处理多行选项的影响)
\z 字符串结尾(类似$,但不受处理多行选项的影响)
\G 当前搜索的开头
\p{name} Unicode中命名为name的字符类,例如\p{IsGreek}
(?>exp) 贪婪子表达式
(?
(?-
(?im-nsx:exp) 在子表达式exp中改变处理选项
(?im-nsx) 为表达式后面的部分改变处理选项
(?(exp)yes|no) 把exp当作零宽正向先行断言,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no
(?(exp)yes) 同上,只是使用空表达式作为no
(?(name)yes|no) 如果命名为name的组捕获到了内容,使用yes作为表达式;否则使用no
(?(name)yes) 同上,只是使用空表达式作为no
一些我认为你可能已经知道的术语的参考
字符
程序处理文字时最基本的单位,可能是字母,数字,标点符号,空格,换行符,汉字等等。
字符串
0个或更多个字符的序列。
文本
文字,字符串。
匹配
符合规则,检验是否符合规则,符合规则的部分。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



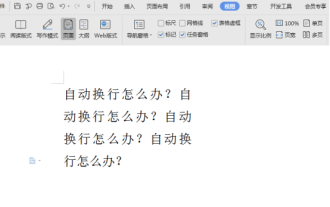 How to cancel automatic word wrapping in word
Mar 19, 2024 pm 10:16 PM
How to cancel automatic word wrapping in word
Mar 19, 2024 pm 10:16 PM
When editing content in a word document, lines may automatically wrap. If no adjustment is made at this time, it will have a great impact on our editing and make people very headache. What is going on? In fact, it is a problem with the ruler. Below, I will introduce the solution to how to cancel automatic word wrapping in word. I hope it can help everyone! After opening a Word document and entering text, when you try to copy and paste, the text may jump to a new line. In this case, you need to adjust the settings to solve this problem. 2. To solve this problem, we must first know the cause of this problem. At this time we click View under the toolbar. 3. Then click the "Ruler" option below. 4. At this time we will find that a ruler appears above the document with several conical markers on it.
 Detailed explanation of how to display the ruler in Word and how to operate the ruler!
Mar 20, 2024 am 10:46 AM
Detailed explanation of how to display the ruler in Word and how to operate the ruler!
Mar 20, 2024 am 10:46 AM
When we use Word, in order to edit the content more beautifully, we often use rulers. You should know that the rulers in Word include horizontal rulers and vertical rulers, which are used to display and adjust the document's page margins, paragraph indents, tabs, etc. So, how do you display the ruler in Word? Next, I will teach you how to set the ruler display. Students in need should quickly collect it! The steps are as follows: 1. First, we need to bring up the word ruler. The default word document does not display the word ruler. We only need to click the [View] button in word. 2. Then, we find the option of [Ruler] and check it. In this way, we can adjust the word ruler! Yes or no
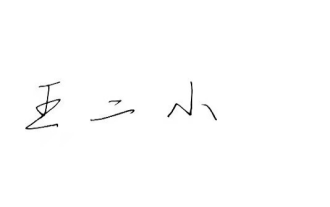 How to add handwritten signature to word document
Mar 20, 2024 pm 08:56 PM
How to add handwritten signature to word document
Mar 20, 2024 pm 08:56 PM
Word documents are widely used due to their powerful functions. Not only can various formats be inserted into Word, such as pictures and tables, etc., but now for the integrity and authenticity of the files, many files require a manual signature at the end of the document. It sounds like this How to solve complex problems? Today I will teach you how to add a handwritten signature to a word document. Use a scanner, camera or mobile phone to scan or photograph the handwritten signature, and then use PS or other image editing software to perform necessary cropping on the image. 2. Select "Insert - Picture - From File" in the Word document where you want to insert the handwritten signature, and select the cropped handwritten signature. 3. Double-click the handwritten signature picture (or right-click the picture and select "Set Picture Format"), and the "Set Picture Format" pops up.
 How to set page margins for Word
Mar 19, 2024 pm 10:00 PM
How to set page margins for Word
Mar 19, 2024 pm 10:00 PM
Among office software, Word is one of our most commonly used software. The text documents we produce are generally operated with Word. Some documents need to be submitted in paper version as required. Before printing, the layout must be set before it can be presented. produce better results. So the question is, how do you set page margins in Word? We have specific course explanations to help you solve your doubts. 1. Open or create a new word document and click the "Page Layout" menu on the menu bar. 2. Click the "Margins" button of the "Page Setup" option. 3. Select a commonly used page margin in the list. 4. If there are no suitable margins in the list, click "Custom Margins". 5. The "Page Setup" dialog box pops up, enter the "Margins" option respectively.
 How to draw a dotted line in word
Mar 19, 2024 pm 10:25 PM
How to draw a dotted line in word
Mar 19, 2024 pm 10:25 PM
Word is a software that we often use in our office. It has many functions that can facilitate our operations. For example, for a large article, we can use the search function inside to find out that a word in the full text is wrong, so we can directly replace it. Make changes one by one; when submitting the document to your superiors, you can beautify the document to make it look better, etc. Below, the editor will share with you the steps on how to draw a dotted line in Word. Let's learn together! 1. First, we open the word document on the computer, as shown in the figure below: 2. Then, enter a string of text in the document, as shown in the red circle in the figure below: 3. Next, press and hold [ctrl+A] Select all the text, as shown in the red circle in the figure below: 4. Click [Start] on the top of the menu bar
 Specific steps to delete down arrow in Word!
Mar 19, 2024 pm 08:50 PM
Specific steps to delete down arrow in Word!
Mar 19, 2024 pm 08:50 PM
In daily office work, if you copy a piece of text from a website and paste it directly into Word, you will often see a [down arrow]. This [down arrow] can be deleted by selecting it, but if there are too many such symbols, So is there a quick way to delete all arrows? So today I will share with you the specific steps to delete the downward arrow in Word! First of all, the [Down Arrow] in Word actually represents [Manual Line Break]. We can replace all [Down Arrows] with [Paragraph Mark] symbols, as shown in the figure below. 2. Then, we select the [Find and Replace] option on the menu bar (as shown in the red circle in the figure below). 3. Then, click the [Replace] command, a pop-up box will pop up, click [Special Symbols]
 Where is the shading setting in word?
Mar 20, 2024 am 08:16 AM
Where is the shading setting in word?
Mar 20, 2024 am 08:16 AM
We often use word for office work, but do you know where the shading settings are in word? Today I will share with you the specific operation steps. Come and take a look, friends! 1. First, open the word document, select a paragraph of text paragraph information that needs to be added with shading, then click the [Start] button on the toolbar, find the paragraph area, and click the drop-down button on the right (as shown in the red circle in the figure below) ). 2. After clicking the drop-down box button, in the pop-up menu options, click the [Border and Shading] option (as shown in the red circle in the figure below). 3. In the pop-up [Border and Shading] dialog box, click the [Shading] option (as shown in the red circle in the figure below). 4. In the filled column, select a color
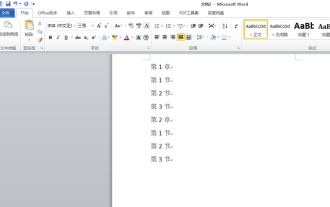 How to automatically sort word serial numbers
Mar 20, 2024 pm 09:20 PM
How to automatically sort word serial numbers
Mar 20, 2024 pm 09:20 PM
When there is a lot of content in word, there will be many chapters. It is impossible for us to write each chapter one by one. In fact, we can use the word serial number to automatically sort. The operation is simple and convenient. Friends who don’t know how to operate, come and learn it. Bar! 1. First, we open the document to be processed on the computer, as shown in the figure below: 2. After opening the document, select the text that needs to be automatically sorted. In this example, select [Chapter 1] and [Chapter 2] and hold down the Ctrl key. To select multiple areas, use the mouse to click the [Start] menu of Word after selection, as shown in the red circle in the figure below: 3. Click the small triangle symbol to the right of the number on the [Paragraph] toolbar, and click in the pop-up menu The serial number type that needs to be selected is as shown below with the red arrow pointing to it.
