

Brief analysis of Prototype source code String part (2)_prototype

| 格式 | camelize | capitalize | underscore | dasherize | inspect |
| 变形 | toArray | succ | times |
Since it involves characters that need to be escaped, we naturally need a copy of the escape character information, which is given directly below:
String.specialChar = {
'b': '\b',
't': '\t',
'n': '\n',
'f': '\f',
'r': '\r',
'\': '\\'
}
[In JSON.js, there is an extra '"', because "" cannot appear in the string in JSON, so it needs to be escaped]
The first step, of course, is to Replace special escape characters, initial version:
function inspect () {
return this.replace(/[btnfr\]/,function(a){
return String.specialChar[a];
});
}
For JSON form, double quotes are necessary. Therefore, we should be able to choose our own return form. Therefore, give inspect a parameter useDoubleQuotes. The default is to use single quotes to return the string.
function inspect(useDoubleQuotes) {
var escapedString = this.replace(/[btnfr\]/,function(a){
return String.specialChar[a];
});
if (useDoubleQuotes){
return '"' escapedString. replace(/"/g, '\"') '"';
}
return "'" escapedString.replace(/'/g, '\'') "'";
}
Now this is similar to the function in the source code, but the implementation in the Prototype source code is not like this. The main difference lies in the escapedString section. All control characters are directly listed in the source code, expressed as [x00-x1f], plus '' is [x00-x1f\], so the initial version of the above modification is:
function inspect(useDoubleQuotes) {
var escapedString = this.replace(/[x00-x1f\]/g , function(character) {
if (character in String.specialChar) {
return String.specialChar[character];
}
return character ;
});
if ( useDoubleQuotes) return '"' escapedString.replace(/"/g, '\"') '"';
return "'" escapedString.replace(/'/g, '\'') "'";
}
[html]
Attached is the ASCII control character encoding table, corresponding to x00-x1f:
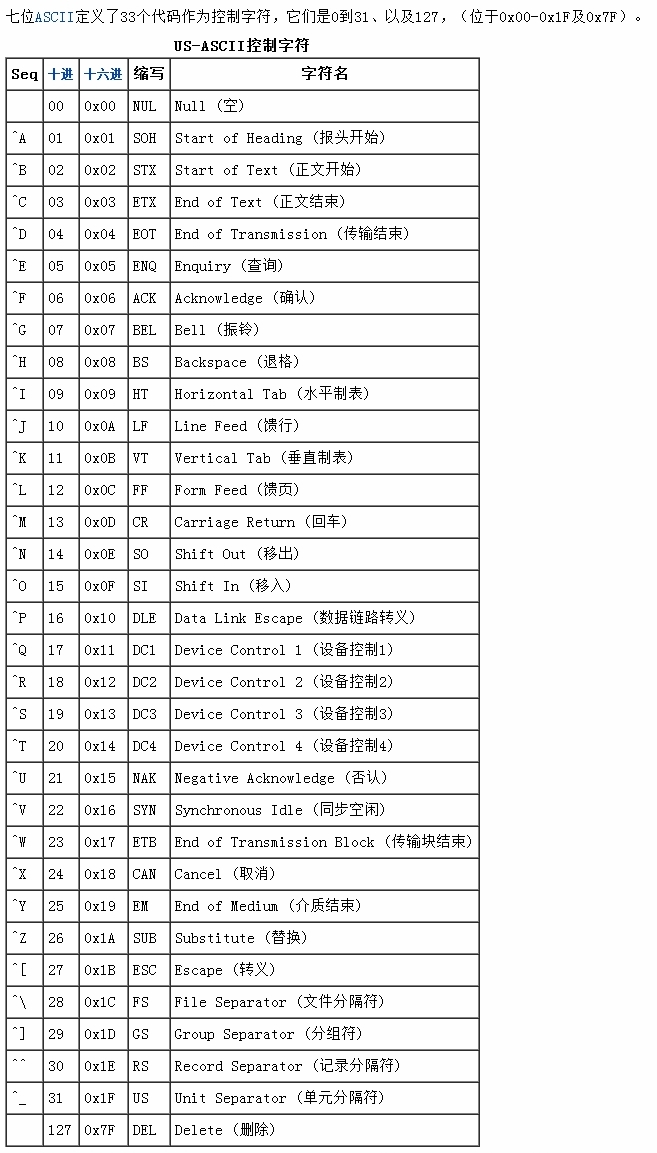
If you find that in addition to the characters in String.specialChar, there are other control characters, there is also a step in the source code, which is to convert the control characters into unicode representation, because this method itself Just to get the string form.
For example, the vertical tab character 'v'. 'v'.inspect() -->'u000b'
Full version:
[code]
function inspect(useDoubleQuotes) {
var escapedString = this.replace(/[x00-x1f \]/g, function(character) {
if (character in String.specialChar) {
return String.specialChar[character];
}
return '\u00' character.charCodeAt() .toPaddedString(2, 16);
});
if (useDoubleQuotes) return '"' escapedString.replace(/"/g, '\"') '"';
return "'" escapedString.replace(/'/g, '\'') "'";
}
where toPaddedString(length[, radix]) converts the current Number object to a string, if If the length of the converted string is less than the value specified by length, 0 is used to pad the remaining digits on the left. The optional parameter radix is used to specify the base used for conversion. This is an extension of Number in Prototype, just know it for now.
Therefore, 'v'.charCodeAt().toPaddedString(2, 16) is to convert the character encoding of 'v' into a hexadecimal two-digit encoding character [the operation character will not be limited in range, so it will not exceed] , and finally start with 'u00'.
Method description:
toArray: Split the string into a character array.
succ: Convert the last character of the string to subsequent characters according to the Unicode alphabet
times: Repeat the string.
The corresponding specific implementation is also very simple. The important part of the String part lies in the subsequent script, JSON and replacement processing, and the others are enhanced.
function toArray() {
return this.split('');
}
Where split('') splits the string into individual Characters and returned in the form of an array. If you want to enhance it further, you can give a parameter to toArray to specify the delimiter.
function toArray(pattern) {
return this. split(pattern);
}
console.log(toArray.call('my name is xesam',' '));//["my", "name", "is", "xesam" ]
It’s just the use of split, but it’s not done in the source code because it’s not necessary.
function succ() {
return this.slice(0, this.length - 1) String.fromCharCode(this.charCodeAt(this.length - 1) 1);
}
The main ones here are fromCharCode and charCodeAt methods of use. It can also be seen from the code that the obvious difference between the two is that fromCharCode is a static method of String, while charCodeAt is a method of string (hanging on String.prototype). Then the two have exactly the opposite effect. The following is the explanation given by http://www.w3school.com.cn:
fromCharCode() accepts a specified Unicode value and then returns a string.
The charCodeAt() method returns the Unicode encoding of the character at the specified position. This return value is an integer between 0 - 65535.
Specific to succ, taking the string 'hello xesam' as an example, first get all the characters 'hello xesa' except the ending character, and then add the character 'n' after 'm' in the Unicode table, so the result It's 'hello xesan'
Based on this, we want to print all letters from 'a' to 'z', you can use the following function:
function printChar(start,end){
var s = (start '').charCodeAt()
var e = (end '').charCodeAt();
if(s > e){
s = [e,e=s][0];
}
for(var i = s ;i <= e; i ){
console.log(String.fromCharCode(i));
}
}
printChar('a','z');
function times(count) {
return count < 1 ? '' : new Array(count 1).join(this);
}
The function of times is to repeat the entire string. The main idea is to add the current character to Calling join as a concatenator of arrays yields the expected results. Of course, you can also add it using a loop, but it's not that simple.
If you want to repeat each character in the string, you can use the same idea:
String.prototype.letterTimes = function(count){
var arr = [];
arr.length = count 1;
return this.replace(/w/g ,function(a){
return arr.join(a);
})
}
console.log('xesam'.letterTimes(3));//xxxeeesssaaammm
camelize | capitalize | underscore | dasherize These four are mainly about variable name conversion.
camelize: Convert a string separated by dashes into Camel form
capitalize: Convert the first letter of a string to uppercase and all other letters to lowercase.
underscore: Converts a Camel-form string into a series of words separated by underscores ("_").
dasherize: Replace all underscores in the string with dashes ("_" is replaced with "-").
The most obvious one can be used in the mutual conversion between CSS attributes and DOM style attributes [class and float do not fall into this category]. Corresponding to the above method, the camelize method can be used to convert CSS attributes into the corresponding DOM style attributes, but there is no such method in reverse, so the underscore -> dasherize method must be called continuously.
function camelize() {
return this.replace (/- (.)?/g, function(match, chr) {
return chr ? chr.toUpperCase() : '';
});
}
The core is the use of the replace method, the rest is quite simple, see "A Brief Analysis of the Application of the Replace Method in Strings"
function capitalize() {
return this.charAt(0).toUpperCase() this.substring(1).toLowerCase();
}
Just pay attention here to the difference between charAt (charAt() method can return the character at the specified position.) and charCodeAt.
function underscore() {
return this.replace(/::/g, '/')
.replace(/([A-Z] )([A-Z][a-z])/g, '$1_$2')
.replace(/ ([a-zd])([A-Z])/g, '$1_$2')
.replace(/-/g, '_')
.toLowerCase();
}
Example to illustrate the steps:
'helloWorld::ABCDefg'.underscore()
//'helloWorld::ABCDefg'
.replace(/::/g, '/') //'helloWorld/ABCDefg'
.replace( /([A-Z] )([A-Z][a-z])/g, '$1_$2')//helloWorld/ABC_Defg
.replace(/([a-zd])([A-Z])/g, '$1_$2') //hello_World/ABC_Defg
.replace(/-/g, '_') //hello_World/ABC_Defg
.toLowerCase(); //hello_world/abc_defg
This method is only suitable for Camel form, that is, it must have a 'peak'.
function dasherize() {
return this.replace (/_/g, '-');
}
This is just a simple character replacement.
From Xiaoxi Shanzi

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Convert basic data types to strings using Java's String.valueOf() function
Jul 24, 2023 pm 07:55 PM
Convert basic data types to strings using Java's String.valueOf() function
Jul 24, 2023 pm 07:55 PM
Convert basic data types to strings using Java's String.valueOf() function In Java development, when we need to convert basic data types to strings, a common method is to use the valueOf() function of the String class. This function can accept parameters of basic data types and return the corresponding string representation. In this article, we will explore how to use the String.valueOf() function for basic data type conversions and provide some code examples to
 How to convert char array to string
Jun 09, 2023 am 10:04 AM
How to convert char array to string
Jun 09, 2023 am 10:04 AM
Method of converting char array to string: It can be achieved by assignment. Use {char a[]=" abc d\0efg ";string s=a;} syntax to let the char array directly assign a value to string, and execute the code to complete the conversion.
 Use Java's String.replace() function to replace characters (strings) in a string
Jul 25, 2023 pm 05:16 PM
Use Java's String.replace() function to replace characters (strings) in a string
Jul 25, 2023 pm 05:16 PM
Replace characters (strings) in a string using Java's String.replace() function In Java, strings are immutable objects, which means that once a string object is created, its value cannot be modified. However, you may encounter situations where you need to replace certain characters or strings in a string. At this time, we can use the replace() method in Java's String class to implement string replacement. The replace() method of String class has two types:
 2w words detailed explanation String, yyds
Aug 24, 2023 pm 03:56 PM
2w words detailed explanation String, yyds
Aug 24, 2023 pm 03:56 PM
Hello everyone, today I will share with you the basic knowledge of Java: String. Needless to say the importance of the String class, it can be said to be the most used class in our back-end development, so it is necessary to talk about it.
 Use java's String.length() function to get the length of a string
Jul 25, 2023 am 09:09 AM
Use java's String.length() function to get the length of a string
Jul 25, 2023 am 09:09 AM
Use Java's String.length() function to get the length of a string. In Java programming, string is a very common data type. We often need to get the length of a string, that is, the number of characters in the string. In Java, we can use the length() function of the String class to get the length of a string. Here is a simple example code: publicclassStringLengthExample{publ
 Golang function byte, rune and string type conversion skills
May 17, 2023 am 08:21 AM
Golang function byte, rune and string type conversion skills
May 17, 2023 am 08:21 AM
In Golang programming, byte, rune and string types are very basic and common data types. They play an important role in processing data operations such as strings and file streams. When performing these data operations, we usually need to convert them to each other, which requires mastering some conversion skills. This article will introduce the byte, rune and string type conversion techniques of Golang functions, aiming to help readers better understand these data types and be able to apply them skillfully in programming practice.
 How to use java's String class
Apr 19, 2023 pm 01:19 PM
How to use java's String class
Apr 19, 2023 pm 01:19 PM
1. Understanding String1. String in JDK First, let’s take a look at the source code of the String class in the JDK. It implements many interfaces. You can see that the String class is modified by final. This means that the String class cannot be inherited and there is no subclass of String. class, so that all people using JDK use the same String class. If String is allowed to be inherited, everyone can extend String. Everyone uses different versions of String, and two different people Using the same method shows different results, which makes it impossible to develop the code. Inheritance and method overriding not only bring flexibility, but also cause many subclasses to behave differently.
 How to use the split method in Java String
May 02, 2023 am 09:37 AM
How to use the split method in Java String
May 02, 2023 am 09:37 AM
The split method in String uses the split() method of String to split the String according to the incoming characters or strings and return the split array. 1. General usage When using general characters, such as @ or, as separators: Stringaddress="Shanghai@Shanghai City@Minhang District@Wuzhong Road";String[]splitAddr=address.split("@");System .out.println(splitAddr[0]+splitAddr[1]+splitAddr[2]+splitAddr[3
