
 Web Front-end
JS Tutorial
Basic tutorial on operating HTML DOM nodes with JavaScript_Basic knowledge
Web Front-end
JS Tutorial
Basic tutorial on operating HTML DOM nodes with JavaScript_Basic knowledge
Basic tutorial on operating HTML DOM nodes with JavaScript_Basic knowledge

Because of the existence of DOM, this allows us to obtain, create, modify, or delete nodes through JavaScript.
NOTE: The elements in the examples provided below are all element nodes.
Get node
Father-son relationship
element.parentNode element.firstChild/element.lastChild element.childNodes/element.children
Brotherly relationship
element.previousSibling/element.nextSibling element.previousElementSibling/element.nextElementSibling
Acquiring nodes through the direct relationship between nodes will greatly reduce the maintainability of the code (changes in the relationship between nodes will directly affect the acquisition of nodes), but this problem can be effectively solved through interfaces.
Acquiring nodes through the direct relationship between nodes will greatly reduce the maintainability of the code (changes in the relationship between nodes will directly affect the acquisition of nodes), but this problem can be effectively solved through interfaces.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>ELEMENT_NODE & TEXT_NODE</title>
</head>
<body>
<ul id="ul">
<li>First</li>
<li>Second</li>
<li>Third</li>
<li>Fourth</li>
</ul>
<p>Hello</p>
<script type="text/javascript">
var ulNode = document.getElementsByTagName("ul")[0];
console.log(ulNode.parentNode); //<body></body>
console.log(ulNode.previousElementSibling); //null
console.log(ulNode.nextElementSibling); //<p>Hello</p>
console.log(ulNode.firstElementChild); //<li>First</li>
console.log(ulNode.lastElementChild); //<li>Fourth</li>
</script>
</body>
</html>
NTOE: Careful people will find that in the example of node traversal, there are no spaces between the body, ul, li, and p nodes, because if there are spaces, then the spaces will be regarded as a TEXT node, so use ulNode.previousSibling gets an empty text node instead of the
Implement browser-compatible version of element.children
Some older browsers do not support the element.children method, but we can use the following method to achieve compatibility.
<html lang>
<head>
<meta charest="utf-8">
<title>Compatible Children Method</title>
</head>
<body id="body">
<div id="item">
<div>123</div>
<p>ppp</p>
<h1>h1</h1>
</div>
<script type="text/javascript">
function getElementChildren(e){
if(e.children){
return e.children;
}else{
/* compatible other browse */
var i, len, children = [];
var child = element.firstChild;
if(child != element.lastChild){
while(child != null){
if(child.nodeType == 1){
children.push(child);
}
child = child.nextSibling;
}
}else{
children.push(child);
}
return children;
}
}
/* Test method getElementChildren(e) */
var item = document.getElementById("item");
var children = getElementChildren(item);
for(var i =0; i < children.length; i++){
alert(children[i]);
}
</script>
</body>
</html>
NOTE: This compatibility method is a preliminary draft and has not been tested for compatibility.
Interface to get element node
getElementById getElementsByTagName getElementsByClassName querySelector querySelectorAll
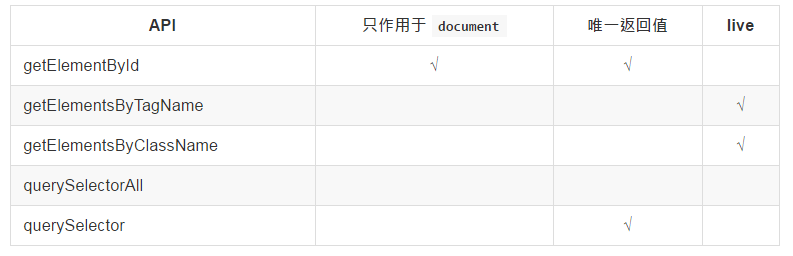
getElementById
Get the node object with the specified id in the document.
var element = document.getElementById('id');
getElementsByTagName
Dynamicly obtain a collection of element nodes with specified tags (its return value will be affected by DOM changes, and its value will change). This interface can be obtained directly through the element and does not have to act directly on the document.
// 示例
var collection = element.getElementsByTagName('tagName');
// 获取指定元素的所有节点
var allNodes = document.getElementsByTagName('*');
// 获取所有 p 元素的节点
var elements = document.getElementsByTagName('p');
// 取出第一个 p 元素
var p = elements[0];
getElementsByClassName
Get all nodes with the specified class in the specified element. Multiple class options can be separated by spaces, regardless of order.
var elements = element.getElementsByClassName('className');
NOTE: IE9 and below do not support getElementsByClassName
Compatible methods
function getElementsByClassName(root, className) {
// 特性侦测
if (root.getElementsByClassName) {
// 优先使用 W3C 规范接口
return root.getElementsByClassName(className);
} else {
// 获取所有后代节点
var elements = root.getElementsByTagName('*');
var result = [];
var element = null;
var classNameStr = null;
var flag = null;
className = className.split(' ');
// 选择包含 class 的元素
for (var i = 0, element; element = elements[i]; i++) {
classNameStr = ' ' + element.getAttribute('class') + ' ';
flag = true;
for (var j = 0, name; name = className[j]; j++) {
if (classNameStr.indexOf(' ' + name + ' ') === -1) {
flag = false;
break;
}
}
if (flag) {
result.push(element);
}
}
return result;
}
}
querySelector / querySelectorAll
Get the first element or all elements of a list (the return result will not be affected by subsequent DOM modifications and will not change after acquisition) that matches the incoming CSS selector.
var listElementNode = element.querySelector('selector');
var listElementsNodes = element.querySelectorAll('selector');
var sampleSingleNode = element.querySelector('#className');
var sampleAllNodes = element.querySelectorAll('#className');
NOTE: IE9 does not support querySelector and querySelectorAll
Create Node
Create node -> Set properties -> Insert node
var element = document.createElement('tagName');
Modify node
textContent
Gets or sets the text content of the node and its descendant nodes (for all text content in the node).
element.textContent; // 获取 element.textContent = 'New Content';
NOTE: IE 9 and below are not supported.
innerText (not W3C compliant)
Gets or sets the text content of the node and its descendants. Its effect on textContent is almost the same.
element.innerText;
NOTE: Not compliant with W3C specifications and does not support FireFox browser.
FireFox Compatibility Solution
if (!('innerText' in document.body)) {
HTMLElement.prototype.__defineGetter__('innerText', function(){
return this.textContent;
});
HTMLElement.prototype.__defineSetter__('innerText', function(s) {
return this.textContent = s;
});
}
Insert node
appendChild
Append an element node within the specified element.
var aChild = element.appendChild(aChild);
insertBefore
Insert the specified element before the specified node of the specified element.
var aChild = element.insertBefore(aChild, referenceChild);
Delete node
Delete the child element nodes of the specified node.
var child = element.removeChild(child);
innerHTML
Get or set all HTML content in the specified node. Replaces all previous internal content and creates a completely new batch of nodes (removing previously added events and styles). innerHTML does not check the content, runs directly and replaces the original content.
NOTE: This is only recommended when creating a brand new node. Not to be used under user control.
var elementsHTML = element.innerHTML;
存在的问题+
- 低版本 IE 存在内存泄露
- 安全问题(用户可以在名称中运行脚本代码)
PS: appendChild() , insertBefore()插入节点需注意的问题
使用appendChild()和insertBefore()插入节点都会返回给插入的节点,
//由于这两种方法操作的都是某个节点的子节点,所以必须现取得父节点,代码中 someNode 表示父节点 //使用appendChild()方法插入节点 var returnedNode = someNode.appendChild(newNode); alert(returnedNode == newNode) //true //使用insertBefore()方法插入节点 var returnedNode = someNode.appendChild(newNode); alert(returnedNode == newNode) //true
值得注意的是,如果这两种方法插入的节点原本已经存在与文档树中,那么该节点将会被移动到新的位置,而不是被复制。
<div id="test">
<div>adscasdjk</div>
<div id="a">adscasdjk</div>
</div>
<script type="text/javascript">
var t = document.getElementById("test");
var a = document.getElementById('a');
//var tt = a.cloneNode(true);
t.appendChild(a);
</script>
在这段代码中,页面输出的结果和没有Javascript时是一样的,元素并没有被复制,由于元素本来就在最后一个位置,所以就和没有操作一样。如果把id为test的元素的两个子元素点换位置,就可以在firbug中看到这两个div已经被调换了位置。
如果我们希望把id为a的元素复制一个,然后添加到文档中,那么必须使被复制的元素现脱离文档流。这样被添加复制的节点被添加到文档中之后就不会影响到文档流中原本的节点。即我们可以把复制的元素放到文档的任何地方,而不影响被复制的元素。下面使用了cloneNode()方法,实现节点的深度复制,使用这种方法复制的节点会脱离文档流。当然,我不建议使用这种方法复制具有id属性的元素。因为在文档中id值是唯一的。
<div id="test">
<div>adscasdjk</div>
<div id="a">adscasdjk</div>
</div>
<script type="text/javascript">
var t = document.getElementById("test");
var a = document.getElementById('a');
var tt = a.cloneNode(true);
t.appendChild(tt);
</script>
相似的操作方法还有 removeNode(node)删除一个节点,并返回该节;replaceNode(newNode,node)替换node节点,并返回该节点。这两种方法相对来说更容易使用一些。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 Table Border in HTML
Sep 04, 2024 pm 04:49 PM
Table Border in HTML
Sep 04, 2024 pm 04:49 PM
Guide to Table Border in HTML. Here we discuss multiple ways for defining table-border with examples of the Table Border in HTML.
 Nested Table in HTML
Sep 04, 2024 pm 04:49 PM
Nested Table in HTML
Sep 04, 2024 pm 04:49 PM
This is a guide to Nested Table in HTML. Here we discuss how to create a table within the table along with the respective examples.
 HTML margin-left
Sep 04, 2024 pm 04:48 PM
HTML margin-left
Sep 04, 2024 pm 04:48 PM
Guide to HTML margin-left. Here we discuss a brief overview on HTML margin-left and its Examples along with its Code Implementation.
 HTML Table Layout
Sep 04, 2024 pm 04:54 PM
HTML Table Layout
Sep 04, 2024 pm 04:54 PM
Guide to HTML Table Layout. Here we discuss the Values of HTML Table Layout along with the examples and outputs n detail.
 HTML Ordered List
Sep 04, 2024 pm 04:43 PM
HTML Ordered List
Sep 04, 2024 pm 04:43 PM
Guide to the HTML Ordered List. Here we also discuss introduction of HTML Ordered list and types along with their example respectively
 Moving Text in HTML
Sep 04, 2024 pm 04:45 PM
Moving Text in HTML
Sep 04, 2024 pm 04:45 PM
Guide to Moving Text in HTML. Here we discuss an introduction, how marquee tag work with syntax and examples to implement.
 HTML Input Placeholder
Sep 04, 2024 pm 04:54 PM
HTML Input Placeholder
Sep 04, 2024 pm 04:54 PM
Guide to HTML Input Placeholder. Here we discuss the Examples of HTML Input Placeholder along with the codes and outputs.
 How do you parse and process HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
How do you parse and process HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
This tutorial demonstrates how to efficiently process XML documents using PHP. XML (eXtensible Markup Language) is a versatile text-based markup language designed for both human readability and machine parsing. It's commonly used for data storage an
