

爬虫如何获得biilbili播放数?

<i id="dianji" title="播放"></i><i id="dm_count" title="弹幕"></i><i id="stow_count" title="收藏"></i><i id="pt"><span class="v_ctimes" title="硬币数量"></span></i>
回复内容:
用av2047063举例,访问下面的网址:【网址已隐去】@妹空酱 提醒我才想起来。。。。
先去自己申请一个appkey。。。在这里:
bilibili - 提示
然后就可以对bilibiliapi为所欲为了。。。。
B站第三方客户端就是这么开发出来的。。。


可以看到最后两个参数id=av号&page=分p
play后面的18253即为播放数。
==============================
b站有公开api啊。。。。。。。那么麻烦干嘛。。。 答主的第一次就就交在这里了,,,
———————————————————————————————————————
前不久学习了python,正好复习一下
代码如下:
import re,urllib
page=urllib.urlopen('http://m.acg.tv/video/av2046040.html')
HTML=page.read()
re_times=r'
result = re.findall(re_times,HTML)
re_title=r'
(.*)
'title=re.findall(re_title,HTML)
print title[0],'的播放次数为',result[0]
下面以av2046040为例:http://www.bilibili.com/video/av2046040/
可以看到
 使用火狐查看选中部分源代码,如下
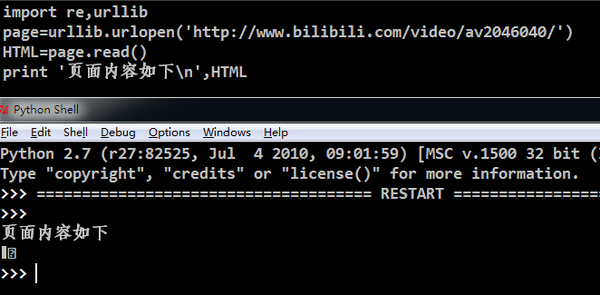
使用火狐查看选中部分源代码,如下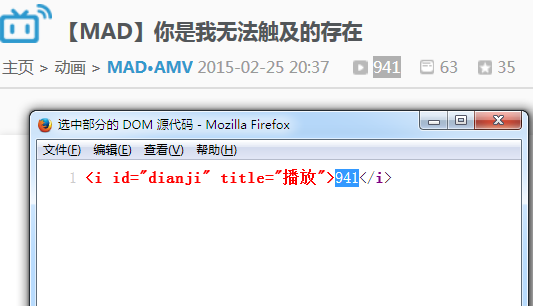 但是我通过python的urllib模块并没有获取到页面内容:
但是我通过python的urllib模块并没有获取到页面内容:page=urllib.urlopen('http://www.bilibili.com/video/av2046040/')
 于是我转换思路,貌似B站的手机版网页可以,
于是我转换思路,貌似B站的手机版网页可以,然后使用火狐的User-Agent Overrider修改浏览器UA为Android FireFox/29
 既可以获得如下界面:
既可以获得如下界面: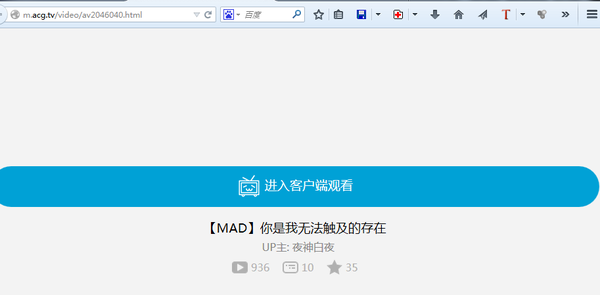 获取到页面实际地址后,就可以再次使用火狐查看源代码
获取到页面实际地址后,就可以再次使用火狐查看源代码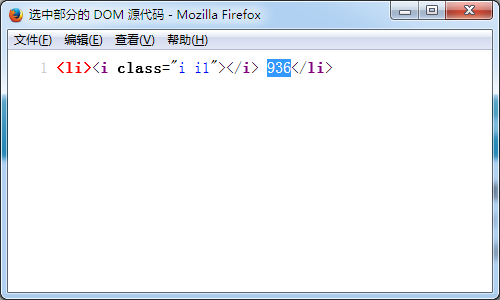 既可以写出正则表达式:
既可以写出正则表达式:re_times=r'
然后正则匹配就好了。
<span class="c"># encoding=utf8</span>
<span class="c"># author:shell-von</span>
<span class="kn">import</span> <span class="nn">requests</span>
<span class="kn">import</span> <span class="nn">re</span>
<span class="n">aid</span> <span class="o">=</span> <span class="s">'3210612'</span>
<span class="n">api_key</span> <span class="o">=</span> <span class="s">"http://interface.bilibili.com/count?key=27f582250563d5d6b11d6833&aid=</span><span class="si">%s</span><span class="s">"</span>
<span class="n">data</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">api_key</span> <span class="o">%</span> <span class="n">aid</span><span class="p">)</span><span class="o">.</span><span class="n">content</span>
<span class="n">regex</span> <span class="o">=</span> <span class="s">r"\('(?:.|#)([\w_]+)'\)\.html\('?(\d+)'?\)"</span>
<span class="k">print</span> <span class="nb">dict</span><span class="p">(</span><span class="n">re</span><span class="o">.</span><span class="n">findall</span><span class="p">(</span><span class="n">regex</span><span class="p">,</span> <span class="n">data</span><span class="p">))</span>
 haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:
haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:<span class="n">aid</span> <span class="p">=</span> <span class="mi">3295561</span><span class="p">;</span>
<span class="n">api</span> <span class="p">=</span> <span class="s">'http://interface.bilibili.com/count?key=b9415053057bb00966665eaa'</span><span class="p">;</span>
<span class="n">data</span> <span class="p">=</span> <span class="n">regexp</span><span class="p">(</span><span class="n">webread</span><span class="p">(</span><span class="n">api</span><span class="p">,</span><span class="s">'aid'</span><span class="p">,</span><span class="n">aid</span><span class="p">),</span><span class="s">'#(\w)+\D*(\d)+'</span><span class="p">,</span><span class="s">'tokens'</span><span class="p">);</span>
<span class="n">data</span> <span class="p">=</span> <span class="p">[</span><span class="n">data</span><span class="p">{:}]</span>
0、打开特定的av页面,通过这条语句来找到CID和AID。注意:ctrl + u中能看到的源代码就是能匹配的源代码。
1、发送请求到interface.bilibili.com/player?id=cid:(匹配的CID,要前面的冒号)&aid=(匹配的AID)
2、从获取的xml文件中找到
=====================================================
实际上,我们ctrl + u看到的页面是网站发给我们的其中一个包而已,而最终的结果页面是网站发给我们的多个包组合的结果。
有时候,网站会将数据封装在json或者xml中,然后通过多个请求获取数据,最后在本地用js来进行最后的构建。
因此,页面上看到的内容是最后的结果,如果你要判断这个结果来自于源页面还是json还是xml,就需要通过开发者工具抓抓包,然后自己分析。
总之,逻辑就是:
0、这个数据哪来的? —— 通过抓包分析
1、模拟获取这个数据的过程。 —— 直接访问该数据的来源url
当然还要注意你要传的参数。这个参数从哪些地方获取也需要自己分析。
====================================================
还是举个例子吧。
注意:B站发回的数据是gzip,然而urllib2的urlopen不会自动解压,需要手动处理。
可以参考这个回答:
Does python urllib2 automatically uncompress gzip data fetched from webpage?
随便在首页找了个页面,地址如下:
【爱深黑切】路人女主的玩坏方法~第一弹
import urllib2
import re
from StringIO import StringIO
import gzip
def find_cid_aid(html):
target = re.compile('EmbedPlayer(?P<args>.*?)</script>',re.DOTALL)
cidaid = target.search(html)
cidaid = html[cidaid.start('args'):cidaid.end('args')]
cid = cidaid.find('cid=')
aid = cidaid.find('&aid=')
index = aid
while cidaid[index] != '"':
index += 1
return (cidaid[cid + 4:aid],cidaid[aid + 5:index])
def find_how_many(cid_aid):
target = re.compile(r'<click>(?P<result>.*?)</click>',re.DOTALL)
cid = cid_aid[0]
aid = cid_aid[1]
addr = r'http://interface.bilibili.com/player?id=cid:' + cid + '&aid=' + aid
f = urllib2.urlopen(addr)
res = f.read()
target = target.search(res)
return res[target.start('result'):target.end('result')]
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', \
'Accept-Language':'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3', \
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:28.0) Gecko/20100101 Firefox/28.0',\
'Host':'www.bilibili.com', \
'Accept-Encoding':'gzip, deflate', \
'Cache-Control':'max-age=0', \
'Connection':'keep-alive'}
request = urllib2.Request(r'http://www.bilibili.com/video/av2046145/', headers=headers)
html = urllib2.urlopen(request)
if html.info().get('Content-Encoding') == 'gzip':
buf = StringIO(html.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
cid_aid = find_cid_aid(html)
print find_how_many(cid_aid)
什么东西抓抓包就知道了
比如说如图一样的懒人眼镜,你懂的~~这里的源码直接可以直接用正则匹配到cid和aid,
cid=1511100&aid=1044050然后请求
http://interface.bilibili.com/player?id=cid:1511100&aid=1044050然后被
<click>4611</click>

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 What are the differences between Huawei GT3 Pro and GT4?
Dec 29, 2023 pm 02:27 PM
What are the differences between Huawei GT3 Pro and GT4?
Dec 29, 2023 pm 02:27 PM
Many users will choose the Huawei brand when choosing smart watches. Among them, Huawei GT3pro and GT4 are very popular choices. Many users are curious about the difference between Huawei GT3pro and GT4. Let’s introduce the two to you. . What are the differences between Huawei GT3pro and GT4? 1. Appearance GT4: 46mm and 41mm, the material is glass mirror + stainless steel body + high-resolution fiber back shell. GT3pro: 46.6mm and 42.9mm, the material is sapphire glass + titanium body/ceramic body + ceramic back shell 2. Healthy GT4: Using the latest Huawei Truseen5.5+ algorithm, the results will be more accurate. GT3pro: Added ECG electrocardiogram and blood vessel and safety
 Fix: Snipping tool not working in Windows 11
Aug 24, 2023 am 09:48 AM
Fix: Snipping tool not working in Windows 11
Aug 24, 2023 am 09:48 AM
Why Snipping Tool Not Working on Windows 11 Understanding the root cause of the problem can help find the right solution. Here are the top reasons why the Snipping Tool might not be working properly: Focus Assistant is On: This prevents the Snipping Tool from opening. Corrupted application: If the snipping tool crashes on launch, it might be corrupted. Outdated graphics drivers: Incompatible drivers may interfere with the snipping tool. Interference from other applications: Other running applications may conflict with the Snipping Tool. Certificate has expired: An error during the upgrade process may cause this issu simple solution. These are suitable for most users and do not require any special technical knowledge. 1. Update Windows and Microsoft Store apps
 The difference between counta and count
Nov 20, 2023 am 10:01 AM
The difference between counta and count
Nov 20, 2023 am 10:01 AM
The Count function is used to count the number of numbers in a specified range. It ignores text, logical values, and null values, but counts empty cells. The Count function only counts the number of cells that contain actual numbers. The CountA function is used to count the number of non-empty cells in a specified range. It not only counts cells containing actual numbers, but also counts the number of non-empty cells containing text, logical values, and formulas.
 How to Fix Can't Connect to App Store Error on iPhone
Jul 29, 2023 am 08:22 AM
How to Fix Can't Connect to App Store Error on iPhone
Jul 29, 2023 am 08:22 AM
Part 1: Initial Troubleshooting Steps Checking Apple’s System Status: Before delving into complex solutions, let’s start with the basics. The problem may not lie with your device; Apple's servers may be down. Visit Apple's System Status page to see if the AppStore is working properly. If there's a problem, all you can do is wait for Apple to fix it. Check your internet connection: Make sure you have a stable internet connection as the "Unable to connect to AppStore" issue can sometimes be attributed to a poor connection. Try switching between Wi-Fi and mobile data or resetting network settings (General > Reset > Reset Network Settings > Settings). Update your iOS version:
 what does title mean
Aug 04, 2023 am 11:18 AM
what does title mean
Aug 04, 2023 am 11:18 AM
Title is the meaning that defines the title of the web page. It is located within the tag and is the text displayed in the title bar of the browser. Title is very important for the search engine optimization and user experience of the web page. When writing HTML web pages, you should pay attention to using relevant keywords and attractive descriptions to define the title element to attract more users to click and browse.
 php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出php提交表单通过后,弹出的对话框怎样在当前页弹出而不是在空白页弹出?想实现这样的效果:而不是空白页弹出:------解决方案--------------------如果你的验证用PHP在后端,那么就用Ajax;仅供参考:HTML code
 What is the meaning of title in HTML
Mar 06, 2024 am 09:53 AM
What is the meaning of title in HTML
Mar 06, 2024 am 09:53 AM
The title in HTML displays the title tag of the web page, which allows the viewer to know what the current page is about, so each web page should have a separate title.
 What are the differences between div and span?
Nov 02, 2023 pm 02:29 PM
What are the differences between div and span?
Nov 02, 2023 pm 02:29 PM
The differences are: 1. div is a block-level element, and span is an inline element; 2. div will automatically occupy a line, while span will not automatically wrap; 3. div is used to wrap larger structures and layouts, and span is used to wrap Text or other inline elements; 4. div can contain other block-level elements and inline elements, and span can contain other inline elements.
