

留言板内容不文明词语过滤的问题

如题。
现在不文明词语是个数组,在留言板内容后,我需要用这个不文明词语数组里面逐个查找留言板内容中是否有匹配的。如果有则提示。在纠结着怎么样才能实现这个不文明词语过滤的效果
回复讨论(解决方案)
首先得有一个脏词包(数据库,或者数组形式)。然后循环正则替换。
function filterWd($content){ $fn = "common/filterword.txt"; $fd = fopen($fn, "rb"); if(file_exists($fn)){ $fw = array(); while(!feof($fd)){ $fw[] = fgets($fd); } for($i = 0; $i < count($fw); $i++){ $srs = stripos($content, $fw[$i]); if($srs = false){ echo "error"; }else{ echo "您输入的内容包含不文明用语'$fw[$i]',请重新输入"; break; } } }else{ echo null; }}filterWd("你妹的找死啊");比如 filterword.txt 里面有 不文明、你妹、找死 三个词语 “echo "您输入的内容包含不文明用语'$fw[$i]',请重新输入";” 这行输出的永远是 不文明 这个单词啊,这个怎么判断?
12行的 if($srs = false){
改为 if($srs == false){
12行的 if($srs = false){
改为 if($srs == false){
嗯,我改过来了还是觉得不行。但是我后面改了一下要过滤的词语后就能找出来了,现在问题又来了,为什么有些词语明明是有的就是没检测出来。如
function filterWd($content){ $fw = array("不文明", "去你的"); for($i = 0; $i < count($fw); $i++){ $srs = stripos($content, $fw[$i]); if($srs == false){ echo "error 第" . $i . "次<br />"; }else{ echo "您输入的内容包含不文明用语'$fw[$i]',请重新输入"; break; } } }filterWd("不文明啊去你的");输出:error 第0次您输入的内容包含不文明用语'去你的',请重新输入//为什么不首先检测到“不文明”呢? 你不是在找到第一个就不再找(break)了吗?
第一个 “不文明” 不等于 false 输出:您输入的内容包含不文明用语'去你的',请重新输入。然后再断开
不应该是这样的吗?怎么会跳到第二个“去你的”去断开
出现的次序是由你的字典顺序决定的
如果你用 trie 算法(精华区有)的话,才能按输入文字的次序检查
不是很理解 , 刚接触不久
你的算法是遍历字典,逐个查看字典字是否出现在正文中
也就是字典有多大,就要检查多少遍
而 trie 算法是:逐字扫描正文,检查由字组成的次是否出现在字典中
只需扫描一遍正文,就可找到所有存在的字典字
经你这么,有点似懂非懂。我换了个 strstr() 就解决了这个问题, strstr() 应该就是全文检索
unction filterWd($content){ $fw = array("天堂", "地狱", "找死", "你妹的", "不文明"); for($i = 0; $i < count($fw); $i++){ $srs = stristr($content, $fw[$i]); if($srs == false){ echo "error"; }else{ echo "您输入的内容包含不文明用语'$fw[$i]',请重新输入"; break; } } }filterWd("不文明啊去你的天堂找死");输出:您输入的内容包含不文明用语'天堂',请重新输入//不管我数组里面怎么打乱次序,数组中第一个 “天堂” 首先在正文中被检索到 如果只是用单个字符串去检索正文用 strpos() 效率应该会更快些
关键是我现在是数组去检索正文 还得判断从数组中取出的是不是匹配 这个有点难理解
if($srs === false){
echo "error 第" . $i . "次
";
}else{
echo "您输入的内容包含不文明用语'$fw[$i]',请重新输入";
break;
}
//楼主该好好看手册了。
if($srs === false){
echo "error 第" . $i . "次
";
}else{
echo "您输入的内容包含不文明用语'$fw[$i]',请重新输入";
break;
}
//楼主该好好看手册了。
有一个我真的不明白,读取文件得来的 存到数组里面
运行到这步
(在下面这行代码之前我运行过 echo $fw[0....9])都是有结果的)
$srs = stristr($content, $fw[$i]); //到这行就是 false 了
返回值永为 false ;
实在让人费解
用var_dump();分别输出一下两个值看看。
var_dump() 也度过了, 只要是过了 $srs = stristr($content, $fw[$i]); 输出的全都是 false
function filterWd($content){ $fw = array("天堂", "地狱", "找死", "你妹的", "不文明"); for($i = 0; $i < count($fw); $i++){ $srs = stristr($content, $fw[$i]); if($srs !== false){ echo "您输入的内容包含不文明用语'$fw[$i]',请重新输入<br>"; //break; } } }filterWd("不文明啊去你的天堂找死");您输入的内容包含不文明用语'找死',请重新输入
您输入的内容包含不文明用语'不文明',请重新输入
之前写了个php替换敏感字符的类,有白名单和黑名单。
黑名单的会替换为*。
可以参考一下: http://blog.csdn.net/fdipzone/article/details/8486985
function filterWd($content){ $fw = array("天堂", "地狱", "找死", "你妹的", "不文明"); for($i = 0; $i < count($fw); $i++){ $srs = stristr($content, $fw[$i]); if($srs !== false){ echo "您输入的内容包含不文明用语'$fw[$i]',请重新输入<br>"; //break; } } }filterWd("不文明啊去你的天堂找死");您输入的内容包含不文明用语'找死',请重新输入
您输入的内容包含不文明用语'不文明',请重新输入
我知道这样是可以。如果数组是读取文件得来的就不行
你读文件时没有去掉换行符
$fn = "common/filterword.txt";$fd = fopen($fn, "rb");if(file_exists($fn)){ $fw = array(); while(!feof($fd)){ $fw[] = trim(fgets($fd)); }}print_r($fw);干脆这样
$fn = "common/filterword.txt";$fw = file($fn, FILE_IGNORE_NEW_LINES | FILE_SKIP_EMPTY_LINES);print_r($fw);
过滤的话...可不可以不提示直接和谐后发布?
echo str_replace($脏话数组, , $content);
还真的是这样,去掉 空格 换行符 就可以了
$fw[] = trim(fgets($fn));
然后再检索 strstr($content,$fw[$i]);
这样就可以了

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 How to enable Sensitive Content Warning on iPhone and learn about its features
Sep 22, 2023 pm 12:41 PM
How to enable Sensitive Content Warning on iPhone and learn about its features
Sep 22, 2023 pm 12:41 PM
Especially over the past decade, mobile devices have become the primary way to share content with friends and family. The easy-to-access, easy-to-use interface and ability to capture images and videos in real time make it a great choice for creating and sharing content. However, it's easy for malicious users to abuse these tools to forward unwanted, sensitive content that may not be suitable for viewing and does not require your consent. To prevent this from happening, a new feature with "Sensitive Content Warning" was introduced in iOS17. Let's take a look at it and how to use it on your iPhone. What is the new Sensitive Content Warning and how does it work? As mentioned above, Sensitive Content Warning is a new privacy and security feature designed to help prevent users from viewing sensitive content, including iPhone
 How to change the Microsoft Edge browser to open with 360 navigation - How to change the opening with 360 navigation
Mar 04, 2024 pm 01:50 PM
How to change the Microsoft Edge browser to open with 360 navigation - How to change the opening with 360 navigation
Mar 04, 2024 pm 01:50 PM
How to change the page that opens the Microsoft Edge browser to 360 navigation? It is actually very simple, so now I will share with you the method of changing the page that opens the Microsoft Edge browser to 360 navigation. Friends in need can take a look. I hope Can help everyone. Open the Microsoft Edge browser. We see a page like the one below. Click the three-dot icon in the upper right corner. Click "Settings." Click "On startup" in the left column of the settings page. Click on the three points shown in the picture in the right column (do not click "Open New Tab"), then click Edit and change the URL to "0" (or other meaningless numbers). Then click "Save". Next, select "
 How to open filtered duplicate files in Quark
Mar 01, 2024 am 11:25 AM
How to open filtered duplicate files in Quark
Mar 01, 2024 am 11:25 AM
When using Quark Browser, there is a function to filter duplicate files. Some friends are not very familiar with this. Here I will introduce how to turn on this function. If you are interested, come and take a look with me. 1. First, click "Quark Browser" on your mobile phone to enter the interface, then click and select "Quark Network Disk" in the options in the middle of the page to open and enter. 2. Find "Backup Settings" in the lower part of the Quark network disk interface, and click to open it, as shown in the figure below: 3. Next, on the page you enter, there is a "Filter Duplicate Files", which is displayed behind it There is a switch button. Click the circular slider on it and set it to color to turn on this function. When you continue to back up files, duplicate files will be skipped to save network disk capacity.
 Python implements XML data filtering and filtering
Aug 09, 2023 am 10:13 AM
Python implements XML data filtering and filtering
Aug 09, 2023 am 10:13 AM
Python implements XML data filtering and filtering. XML (eXtensibleMarkupLanguage) is a markup language used to store and transmit data. It is flexible and scalable and is often used for data exchange between different systems. When processing XML data, we often need to filter and filter it to extract the information we need. This article will introduce how to use Python to filter and filter XML data. Import the required modules Before starting, we
 How to use PHP functions to search and filter data?
Jul 24, 2023 am 08:01 AM
How to use PHP functions to search and filter data?
Jul 24, 2023 am 08:01 AM
How to use PHP functions to search and filter data? In the process of developing using PHP, it is often necessary to search and filter data. PHP provides a wealth of functions and methods to help us achieve these operations. This article will introduce some commonly used PHP functions and techniques to help you search and filter data efficiently. String search Commonly used string search functions in PHP are strpos() and strstr(). strpos() is used to find the position of a certain substring in a string. If it exists, it returns
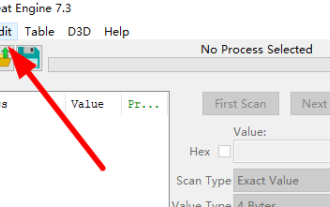 How to set up Cheat Engine in Chinese? Cheat Engine setting Chinese method
Mar 13, 2024 pm 04:49 PM
How to set up Cheat Engine in Chinese? Cheat Engine setting Chinese method
Mar 13, 2024 pm 04:49 PM
CheatEngine is a game editor that can edit and modify the game's memory. However, its default language is non-Chinese, which is inconvenient for many friends. So how to set Chinese in CheatEngine? Today, the editor will give you a detailed introduction to how to set up Chinese in CheatEngine. I hope it can help you. Setting method one: 1. Double-click to open the software and click "edit" in the upper left corner. 2. Then click “settings” in the option list below. 3. In the opened window interface, click "languages" in the left column
 PHP and PHPMAILER: How to implement automatic filtering of mail sending?
Jul 21, 2023 am 09:25 AM
PHP and PHPMAILER: How to implement automatic filtering of mail sending?
Jul 21, 2023 am 09:25 AM
PHP and PHPMAILER: How to implement automatic filtering of mail sending? In modern society, email has become one of the important ways for people to communicate. However, with the popularity and widespread use of email, the amount of spam has also shown an explosive growth trend. Spam emails not only waste users' time and network resources, but may also bring viruses and phishing behaviors. Therefore, when developing the email sending function, it becomes crucial to add the function of automatically filtering spam. This article will introduce how to use PHP and PHPMai
 Form validation and filtering methods in PHP?
Jun 29, 2023 pm 10:04 PM
Form validation and filtering methods in PHP?
Jun 29, 2023 pm 10:04 PM
PHP is a scripting language widely used in web development, and its form validation and filtering are very important parts. When the user submits the form, the data entered by the user needs to be verified and filtered to ensure the security and validity of the data. This article will introduce methods and techniques on how to perform form validation and filtering in PHP. 1. Form validation Form validation refers to checking the data entered by the user to ensure that the data complies with specific rules and requirements. Common form verification includes verification of required fields, email format, and mobile phone number format.
