
 Backend Development
Python Tutorial
Full analysis of the operation method of reading and writing txt text files in Python
Backend Development
Python Tutorial
Full analysis of the operation method of reading and writing txt text files in Python
Full analysis of the operation method of reading and writing txt text files in Python

1. Opening and creating files
>>> f = open('/tmp/test.txt')
>>> f.read()
'hello python!\nhello world!\n'
>>> f
<open file '/tmp/test.txt', mode 'r' at 0x7fb2255efc00>
2. Reading files
Steps: Open -- Read -- Close
>>> f = open('/tmp/test.txt')
>>> f.read()
'hello python!\nhello world!\n'
>>> f.close()
Reading data is a necessary step for post-data processing. .txt is a widely used data file format. Some .csv, .xlsx and other files can be converted to .txt files for reading. I often use the I/O interface that comes with Python to read the data and store it in a list, and then use the numpy scientific computing package to convert the list data into array format, so that scientific calculations can be performed like MATLAB.
The following is a commonly used code for reading txt files, which can be used in most txt file readings
filename = 'array_reflection_2D_TM_vertical_normE_center.txt' # txt文件和当前脚本在同一目录下,所以不用写具体路径
pos = []
Efield = []
with open(filename, 'r') as file_to_read:
while True:
lines = file_to_read.readline() # 整行读取数据
if not lines:
break
pass
p_tmp, E_tmp = [float(i) for i in lines.split()] # 将整行数据分割处理,如果分割符是空格,括号里就不用传入参数,如果是逗号, 则传入‘,'字符。
pos.append(p_tmp) # 添加新读取的数据
Efield.append(E_tmp)
pass
pos = np.array(pos) # 将数据从list类型转换为array类型。
Efield = np.array(Efield)
pass
For example, the following is the txt file to be read
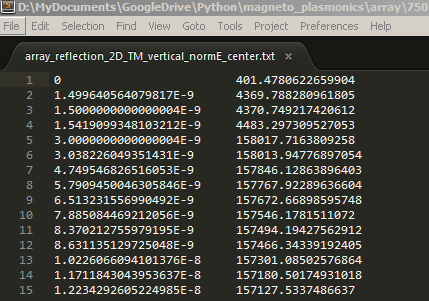
After reading, view the read data in the variable window of Enthought Canopy. Pos is on the left and Efield is on the right.
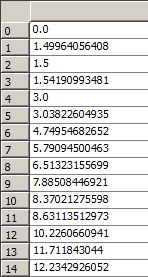
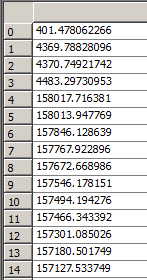
3. File writing (be careful not to clear the original file)
Steps: Open -- Write -- (Save) Close
Directly writing data is not possible because the 'r' read-only mode is opened by default
>>> f.write('hello boy')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IOError: File not open for writing
>>> f
<open file '/tmp/test.txt', mode 'r' at 0x7fe550a49d20>
You should specify the writable mode first
>>> f1 = open('/tmp/test.txt','w')
>>> f1.write('hello boy!')
But at this time the data is only written to the cache and not saved to the file. As you can see from the output below, the original configuration has been cleared
[root@node1 ~]# cat /tmp/test.txt [root@node1 ~]#
Close this file to write the data in the cache to the file
>>> f1.close() [root@node1 ~]# cat /tmp/test.txt [root@node1 ~]# hello boy!
Note: This step needs to be done very carefully, because if the edited file exists, this step will first clear the file and then rewrite it. So what should you do if you don’t want to clear the file and then write it?
Using r mode will not clear it first, but will replace the original file, as in the following example: hello boy! is replaced by hello aay!
>>> f2 = open('/tmp/test.txt','r+')
>>> f2.write('\nhello aa!')
>>> f2.close()
[root@node1 python]# cat /tmp/test.txt
hello aay!
How to achieve non-replacement?
>>> f2 = open('/tmp/test.txt','r+')
>>> f2.read()
'hello girl!'
>>> f2.write('\nhello boy!')
>>> f2.close()
[root@node1 python]# cat /tmp/test.txt
hello girl!
hello boy!
As you can see, if you read the file before writing and then write, the written data will be added to the end of the file without replacing the original file. This is caused by pointers. The pointer in r mode is at the beginning of the file by default. If written directly, the source file will be overwritten. After reading the file through read(), the pointer will move to the end of the file and then write data. There will be no problem. You can also use a mode here
>>> f = open('/tmp/test.txt','a')
>>> f.write('\nhello man!')
>>> f.close()
>>>
[root@node1 python]# cat /tmp/test.txt
hello girl!
hello boy!
hello man!
For introduction to other modes, see the table below:

Methods of file object:
f.readline() Read data line by line
Method 1:
>>> f = open('/tmp/test.txt')
>>> f.readline()
'hello girl!\n'
>>> f.readline()
'hello boy!\n'
>>> f.readline()
'hello man!'
>>> f.readline()
''
Method 2:
>>> for i in open('/tmp/test.txt'):
... print i
...
hello girl!
hello boy!
hello man!
f.readlines() 将文件内容以列表的形式存放
>>> f = open('/tmp/test.txt')
>>> f.readlines()
['hello girl!\n', 'hello boy!\n', 'hello man!']
>>> f.close()
f.next() reads data line by line, similar to f.readline(). The only difference is that f.readline() will return empty if there is no data at the end, while f.next() does not. An error will be reported when data is read
>>> f = open('/tmp/test.txt')
>>> f.readlines()
['hello girl!\n', 'hello boy!\n', 'hello man!']
>>> f.close()
>>>
>>> f = open('/tmp/test.txt')
>>> f.next()
'hello girl!\n'
>>> f.next()
'hello boy!\n'
>>> f.next()
'hello man!'
>>> f.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
f.writelines() Multi-line writing
>>> l = ['\nhello dear!','\nhello son!','\nhello baby!\n']
>>> f = open('/tmp/test.txt','a')
>>> f.writelines(l)
>>> f.close()
[root@node1 python]# cat /tmp/test.txt
hello girl!
hello boy!
hello man!
hello dear!
hello son!
hello baby!
f.seek(offset, option)
>>> f = open('/tmp/test.txt','r+')
>>> f.readline()
'hello girl!\n'
>>> f.readline()
'hello boy!\n'
>>> f.readline()
'hello man!\n'
>>> f.readline()
' '
>>> f.close()
>>> f = open('/tmp/test.txt','r+')
>>> f.read()
'hello girl!\nhello boy!\nhello man!\n'
>>> f.readline()
''
>>> f.close()
This example can fully explain why when using r mode earlier, it is necessary to execute f.read() before inserting normally
f.seek(offset, option)
(1) Option = 0, indicating that the file pointer points from the file head to the "offset" byte
(2) Option = 1, which means to point the file pointer to the current position of the file and move the "offset" byte backward
(3) Option = 2 means to point the file pointer to the end of the file and move the "offset" byte forward
Offset: Positive number means offset to the right, negative number means offset to the left
>>> f = open('/tmp/test.txt','r+')
>>> f.seek(0,2)
>>> f.readline()
''
>>> f.seek(0,0)
>>> f.readline()
'hello girl!\n'
>>> f.readline()
'hello boy!\n'
>>> f.readline()
'hello man!\n'
>>> f.readline()
''
f.flush() Write modifications to the file (without closing the file)
>>> f.write('hello python!')
>>> f.flush()
[root@node1 python]# cat /tmp/test.txt
hello girl! hello boy! hello man! hello python!
f.tell() Get the pointer position
>>> f = open('/tmp/test.txt')
>>> f.readline()
'hello girl!\n'
>>> f.tell()
12
>>> f.readline()
'hello boy!\n'
>>> f.tell()
23
4. Content search and replacement
1. Content search
Example: Number of hellos in statistics file
Idea: Open the file, traverse the file content, match keywords through regular expressions, and count the number of matches.
[root@node1 ~]# cat /tmp/test.txt
hello girl! hello boy! hello man! hello python!
The script is as follows:
Method 1:
#!/usr/bin/python
import re
f = open('/tmp/test.txt')
source = f.read()
f.close()
r = r'hello'
s = len(re.findall(r,source))
print s
[root@node1 python]# python count.py
4
Method 2:
#!/usr/bin/python
import re
fp = file("/tmp/test.txt",'r')
count = 0
for s in fp.readlines():
li = re.findall("hello",s)
if len(li)>0:
count = count + len(li)
print "Search",count, "hello"
fp.close()
[root@node1 python]# python count1.py
Search 4 hello
2、替换
实例:把test.txt 中的hello全部换为"hi",并把结果保存到myhello.txt中。
#!/usr/bin/python
import re
f1 = open('/tmp/test.txt')
f2 = open('/tmp/myhello.txt','r+')
for s in f1.readlines():
f2.write(s.replace('hello','hi'))
f1.close()
f2.close()
[root@node1 python]# touch /tmp/myhello.txt
[root@node1 ~]# cat /tmp/myhello.txt
hi girl!
hi boy!
hi man!
hi python!
实例:读取文件test.txt内容,去除空行和注释行后,以行为单位进行排序,并将结果输出为result.txt。test.txt 的内容如下所示:
#some words Sometimes in life, You find a special friend; Someone who changes your life just by being part of it. Someone who makes you laugh until you can't stop; Someone who makes you believe that there really is good in the world. Someone who convinces you that there really is an unlocked door just waiting for you to open it. This is Forever Friendship. when you're down, and the world seems dark and empty, Your forever friend lifts you up in spirits and makes that dark and empty world suddenly seem bright and full. Your forever friend gets you through the hard times,the sad times,and the confused times. If you turn and walk away, Your forever friend follows, If you lose you way, Your forever friend guides you and cheers you on. Your forever friend holds your hand and tells you that everything is going to be okay.
脚本如下:
f = open('cdays-4-test.txt')
result = list()
for line in f.readlines(): # 逐行读取数据
line = line.strip() #去掉每行头尾空白
if not len(line) or line.startswith('#'): # 判断是否是空行或注释行
continue #是的话,跳过不处理
result.append(line) #保存
result.sort() #排序结果
print result
open('cdays-4-result.txt','w').write('%s' % '\n'.join(result)) #保存入结果文件

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Is there any mobile app that can convert XML into PDF?
Apr 02, 2025 pm 08:54 PM
Is there any mobile app that can convert XML into PDF?
Apr 02, 2025 pm 08:54 PM
An application that converts XML directly to PDF cannot be found because they are two fundamentally different formats. XML is used to store data, while PDF is used to display documents. To complete the transformation, you can use programming languages and libraries such as Python and ReportLab to parse XML data and generate PDF documents.
 Is there a mobile app that can convert XML into PDF?
Apr 02, 2025 pm 09:45 PM
Is there a mobile app that can convert XML into PDF?
Apr 02, 2025 pm 09:45 PM
There is no APP that can convert all XML files into PDFs because the XML structure is flexible and diverse. The core of XML to PDF is to convert the data structure into a page layout, which requires parsing XML and generating PDF. Common methods include parsing XML using Python libraries such as ElementTree and generating PDFs using ReportLab library. For complex XML, it may be necessary to use XSLT transformation structures. When optimizing performance, consider using multithreaded or multiprocesses and select the appropriate library.
 Is the conversion speed fast when converting XML to PDF on mobile phone?
Apr 02, 2025 pm 10:09 PM
Is the conversion speed fast when converting XML to PDF on mobile phone?
Apr 02, 2025 pm 10:09 PM
The speed of mobile XML to PDF depends on the following factors: the complexity of XML structure. Mobile hardware configuration conversion method (library, algorithm) code quality optimization methods (select efficient libraries, optimize algorithms, cache data, and utilize multi-threading). Overall, there is no absolute answer and it needs to be optimized according to the specific situation.
 How to convert XML files to PDF on your phone?
Apr 02, 2025 pm 10:12 PM
How to convert XML files to PDF on your phone?
Apr 02, 2025 pm 10:12 PM
It is impossible to complete XML to PDF conversion directly on your phone with a single application. It is necessary to use cloud services, which can be achieved through two steps: 1. Convert XML to PDF in the cloud, 2. Access or download the converted PDF file on the mobile phone.
 What is the process of converting XML into images?
Apr 02, 2025 pm 08:24 PM
What is the process of converting XML into images?
Apr 02, 2025 pm 08:24 PM
To convert XML images, you need to determine the XML data structure first, then select a suitable graphical library (such as Python's matplotlib) and method, select a visualization strategy based on the data structure, consider the data volume and image format, perform batch processing or use efficient libraries, and finally save it as PNG, JPEG, or SVG according to the needs.
 How to open xml format
Apr 02, 2025 pm 09:00 PM
How to open xml format
Apr 02, 2025 pm 09:00 PM
Use most text editors to open XML files; if you need a more intuitive tree display, you can use an XML editor, such as Oxygen XML Editor or XMLSpy; if you process XML data in a program, you need to use a programming language (such as Python) and XML libraries (such as xml.etree.ElementTree) to parse.
 Recommended XML formatting tool
Apr 02, 2025 pm 09:03 PM
Recommended XML formatting tool
Apr 02, 2025 pm 09:03 PM
XML formatting tools can type code according to rules to improve readability and understanding. When selecting a tool, pay attention to customization capabilities, handling of special circumstances, performance and ease of use. Commonly used tool types include online tools, IDE plug-ins, and command-line tools.
 How to beautify the XML format
Apr 02, 2025 pm 09:57 PM
How to beautify the XML format
Apr 02, 2025 pm 09:57 PM
XML beautification is essentially improving its readability, including reasonable indentation, line breaks and tag organization. The principle is to traverse the XML tree, add indentation according to the level, and handle empty tags and tags containing text. Python's xml.etree.ElementTree library provides a convenient pretty_xml() function that can implement the above beautification process.
