
 Backend Development
PHP Tutorial
A brief discussion on large-scale web system architecture, web system architecture_PHP tutorial
Backend Development
PHP Tutorial
A brief discussion on large-scale web system architecture, web system architecture_PHP tutorial
A brief discussion on large-scale web system architecture, web system architecture_PHP tutorial

A brief discussion of large-scale web system architecture. Web system architecture
Dynamic applications refer to c/c, php, Java, perl, Network application software developed in server-side languages such as .net, such as forums, online photo albums, dating, BLOG and other common applications. Dynamic application systems are usually inseparable from database systems, cache systems, distributed storage systems, etc.
The large-scale dynamic application system platform is mainly aimed at the underlying system architecture established for large-traffic, high-concurrency websites. The operation of large-scale websites requires the support of a reliable, secure, scalable, and easy-to-maintain application system platform to ensure the smooth operation of website applications.
Large-scale dynamic application systems can be divided into several subsystems:
1) Web front-end system
2) Load balancing system
3) Database cluster system
4) Caching system
5) Distributed storage system
6) Distributed server management system
7) Code distribution system
Web front-endSystem
Structural diagram:

In order to achieve server sharing for different applications, avoid single points of failure, centralized management, unified configuration, etc., servers are not divided by applications, but all servers are used uniformly. Each server can provide services for multiple applications. , when the number of visits to certain applications increases, the performance of the entire server cluster can be improved by adding server nodes, and other applications will also benefit. The Web front-end system is based on virtual host platforms such as Apache/Lighttpd/Eginx, etc., and provides PHP program operating environment. The server is transparent to developers and does not require developers to intervene in server management
Load balancing system

Load balancing systems are divided into two types: hardware and software. Hardware load balancing is highly efficient but expensive, such as F5 and so on. Software load balancing systems are less expensive or free and less efficient than hardware load balancing systems, but they are sufficient for websites with average or slightly larger traffic, such as lvs and nginx. Most websites use a combination of hardware and software load balancing systems.
Database cluster system
Structural diagram:

Since the Web front-end adopts a load balancing cluster structure to improve the effectiveness and scalability of the service, the database must also be highly reliable to ensure the high reliability of the entire service system. How to build a highly reliable system that can provide large-scale services? Database system for large-scale concurrent processing?
We can use the solution shown in the picture above:
1) Use the MySQL database. Considering the characteristics of Web application databases that read more and write less, we mainly optimized the reading database and provided dedicated reading and writing databases. Database, read operations and write operations are implemented in the application to access different databases respectively.
2) Use the MySQL Replication mechanism to quickly copy the database of the master database (writing database) to the slave database (reading database). One master database corresponds to multiple slave databases, and data from the master database is synchronized to the slave databases in real time. Dumpling machine www.yjlmj.com Organized and released
3) There are multiple writing databases, each of which can be used by multiple applications. This can solve the performance bottleneck problem and single point of failure problem of writing database.
4) There are multiple reading databases, and load balancing is achieved through load balancing equipment, thereby achieving high performance, high reliability and high scalability of the reading database.
5) Separate database server and application server.
6) Use BigIP for load balancing from the database.
Caching system

Caching is divided into file cache, memory cache and database cache. The most commonly used and most efficient method in large-scale web applications is memory caching. The most commonly used memory caching tool is Memcached. Using the right caching system can achieve the following goals:
1. Using the cache system can improve access efficiency, improve server throughput, and improve user experience.
2. Reduce the access pressure on the database and save set server.
3. There are multiple Memcached servers to avoid single points of failure, provide high reliability and scalability, and improve performance.
Distributed storage system
Structure diagram:

The storage requirements in the Web system platform have the following two characteristics:
1) The storage capacity is large, often reaching a scale that a single server cannot provide, such as photo albums, videos and other applications. Therefore, professional large-scale storage systems are needed.
2) Each node in the load balancing cluster may access any data object, and the data processing by each node can also be shared by other nodes. Therefore, the data to be operated by these nodes can logically only be A whole, not independent data resources.
Therefore, a high-performance distributed storage system is a very important part for large-scale website applications. (A brief introduction to a distributed storage system needs to be added here.)
Distributed server management system
Structure diagram:

With the continuous increase in website access traffic, most network services are provided externally in the form of load balancing clusters. With the expansion of cluster scale, the original server management model based on a single machine can no longer meet our needs. The new requirements must be able to manage servers in a centralized, grouped, batch, and automated manner, and execute planned tasks in batches.
There are some excellent software among distributed server management system software, and one of the more ideal ones is Cfengine. It can group servers, and different groups can customize system configuration files, scheduled tasks and other configurations. It is based on the C/S structure. All server configuration and management script programs are saved on the Cfengine Server, and the managed server runs the Cfengine Client program. The Cfengine Client regularly sends requests to the server through an SSL encrypted connection. Get the latest configuration files and management commands, scripts , patch installation and other tasks.
With Cfengine, a centralized server management tool, we can efficiently implement large-scale server cluster management. The managed server and Cfengine Server can be distributed in any location. As long as the network can be connected, rapid automation can be achieved. manage.
Code release system
Structure diagram:

With the continuous increase of website access traffic, most network services are provided externally in the form of load balancing clusters. As the cluster size expands, in order to meet the batch distribution and update of program code in the cluster environment, we also A program code publishing system is required.
This publishing system can help us achieve the following goals:
1) The server in the production environment provides services in the form of a virtual host, which does not require developers to intervene in maintenance and direct operations. The release system can be used to distribute programs to the target server without logging in to the server.
2) We need to realize the management of the four development stages of internal development, internal testing, production environment testing, and production environment release. The release system can intervene in the code release at each stage.
3) We need to implement source code management and version control, and SVN can achieve this requirement.
Here you can use the commonly used tool Rsync to achieve code synchronization distribution between server clusters by developing corresponding script tools.

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Comparative analysis of deep learning architectures
May 17, 2023 pm 04:34 PM
Comparative analysis of deep learning architectures
May 17, 2023 pm 04:34 PM
The concept of deep learning originates from the research of artificial neural networks. A multi-layer perceptron containing multiple hidden layers is a deep learning structure. Deep learning combines low-level features to form more abstract high-level representations to represent categories or characteristics of data. It is able to discover distributed feature representations of data. Deep learning is a type of machine learning, and machine learning is the only way to achieve artificial intelligence. So, what are the differences between various deep learning system architectures? 1. Fully Connected Network (FCN) A fully connected network (FCN) consists of a series of fully connected layers, with every neuron in each layer connected to every neuron in another layer. Its main advantage is that it is "structure agnostic", i.e. no special assumptions about the input are required. Although this structural agnostic makes the complete
 What is the architecture and working principle of Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
What is the architecture and working principle of Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA is based on the JPA architecture and interacts with the database through mapping, ORM and transaction management. Its repository provides CRUD operations, and derived queries simplify database access. Additionally, it uses lazy loading to only retrieve data when necessary, thus improving performance.
 Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Deep learning models for vision tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images). Generally, an application that completes vision tasks for multiple domains needs to build multiple models for each separate domain and train them independently. Data is not shared between different domains. During inference, each model will handle a specific domain. input data. Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL). In addition, MDL models can also outperform single
 This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Jun 14, 2023 pm 01:43 PM
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Jun 14, 2023 pm 01:43 PM
Some time ago, a tweet pointing out the inconsistency between the Transformer architecture diagram and the code in the Google Brain team's paper "AttentionIsAllYouNeed" triggered a lot of discussion. Some people think that Sebastian's discovery was an unintentional mistake, but it is also surprising. After all, considering the popularity of the Transformer paper, this inconsistency should have been mentioned a thousand times. Sebastian Raschka said in response to netizen comments that the "most original" code was indeed consistent with the architecture diagram, but the code version submitted in 2017 was modified, but the architecture diagram was not updated at the same time. This is also the root cause of "inconsistent" discussions.
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
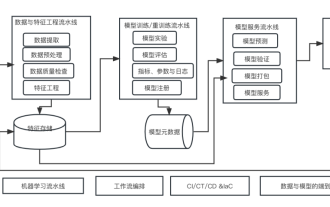 Ten elements of machine learning system architecture
Apr 13, 2023 pm 11:37 PM
Ten elements of machine learning system architecture
Apr 13, 2023 pm 11:37 PM
This is an era of AI empowerment, and machine learning is an important technical means to achieve AI. So, is there a universal machine learning system architecture? Within the cognitive scope of experienced programmers, Anything is nothing, especially for system architecture. However, it is possible to build a scalable and reliable machine learning system architecture if applicable to most machine learning driven systems or use cases. From a machine learning life cycle perspective, this so-called universal architecture covers key machine learning stages, from developing machine learning models, to deploying training systems and service systems to production environments. We can try to describe such a machine learning system architecture from the dimensions of 10 elements. 1.
 AI Infrastructure: The Importance of IT and Data Science Team Collaboration
May 18, 2023 pm 11:08 PM
AI Infrastructure: The Importance of IT and Data Science Team Collaboration
May 18, 2023 pm 11:08 PM
Artificial intelligence (AI) has changed the game in many industries, enabling businesses to improve efficiency, decision-making and customer experience. As AI continues to evolve and become more complex, it is critical that enterprises invest in the right infrastructure to support its development and deployment. A key aspect of this infrastructure is collaboration between IT and data science teams, as both play a critical role in ensuring the success of AI initiatives. The rapid development of artificial intelligence has led to increasing demands for computing power, storage and network capabilities. This demand puts pressure on traditional IT infrastructure, which was not designed to handle the complex and resource-intensive workloads required by AI. As a result, enterprises are now looking to build systems that can support AI workloads.
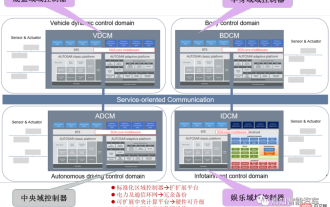 Software architecture design and software and hardware decoupling methodology in SOA
Apr 08, 2023 pm 11:21 PM
Software architecture design and software and hardware decoupling methodology in SOA
Apr 08, 2023 pm 11:21 PM
For the next generation of centralized electronic and electrical architecture, the use of central+zonal central computing unit and regional controller layout has become a must-have option for various OEMs or tier1 players. Regarding the architecture of the central computing unit, there are three ways: separation SOC, hardware isolation, software virtualization. The centralized central computing unit will integrate the core business functions of the three major domains of autonomous driving, smart cockpit and vehicle control. The standardized regional controller has three main responsibilities: power distribution, data services, and regional gateway. Therefore, the central computing unit will integrate a high-throughput Ethernet switch. As the degree of integration of the entire vehicle becomes higher and higher, more and more ECU functions will be slowly absorbed into the regional controller. And platformization
