
 Backend Development
PHP Tutorial
Comparison and sharing of the efficiency of reading and writing files and reading and writing databases in PHP_PHP Tutorial
Backend Development
PHP Tutorial
Comparison and sharing of the efficiency of reading and writing files and reading and writing databases in PHP_PHP Tutorial
Comparison and sharing of the efficiency of reading and writing files and reading and writing databases in PHP_PHP Tutorial

This question also came to my mind recently. Is it faster to read files or databases? How much faster can it be? Tianyuan has also searched and found no netizens have answered this question. It may be because it is too simple. , let’s test it in this article. Due to time constraints, VC has not been installed yet. Tianyuan tested it with PHP first. Next time I have time, I will add tests on C/C++ to this article, because the underlying analysis of PHP should also be based on C. , so it is estimated that the test results of the two environments are similar. Small problems lead to big gains. Now let’s take a look at the test process and results.
The test procedure is as follows:
Note 1: Since the read database statement calls the simple packet function twice, the read file is also changed to two consecutive calls. The database record ID is 1, which is the first one and has a unique index.
Note 2: Tested twice, once with 4K data and once with reshaped data
set_time_limit(0);
function fnGet($filename)
{
$content = file_get_contents($filename);
return $content;
}
function fnGetContent($filename)
{
$content = fnGet($filename);
return $content;
}
$times=100000;
echo 'Database query results:
';
//---------- -----------------------
$begin=fnGetMicroTime();
for($i=0;$i<$times;$i++ )
{
$res=$dbcon->mydb_query("SELECT log_Content FROM blog WHERE log_ID='1'");
$row=$dbcon->mydb_fetch_row($res);
$content=$row[0];
}
echo 'fetch_row '.$times.' Times: '.(fnGetMicroTime()-$begin).'< ;/font>Seconds
';
//-------------------------------- -
$begin=fnGetMicroTime();
for($i=0;$i<$times;$i++)
{
$res=$dbcon->mydb_query("SELECT log_Content FROM blog WHERE log_ID='1'");
$row=$dbcon->mydb_fetch_array($res);
$content=$row['log_Content'];
}
echo 'fetch_array '.$times.' times: '.(fnGetMicroTime()-$begin).'seconds
';
//- --------------------------------
$begin=fnGetMicroTime();
for($i= 0;$i<$times;$i++)
{
$res=$dbcon->mydb_query("SELECT log_Content FROM blog WHERE log_ID='1'");
$row=$dbcon ->mydb_fetch_object($res);
$content=$row->log_Content;
}
echo 'fetch_object '.$times.' times: '. (fnGetMicroTime()-$begin).'seconds
';
//--------------------- ------------
$dbcon->mydb_free_results();
$dbcon->mydb_disconnect();
fnWriteCache('test.txt',$content) ;
echo 'Directly read file test results:
';
//------------------------ --------
$begin=fnGetMicroTime();
for($i=0;$i<$times;$i++)
{
$content = fnGetContent(' test.txt');
}
echo 'file_get_contents read directly'.$times.' times: '.(fnGetMicroTime()-$begin).'';
//---------------------------------
$begin=fnGetMicroTime();
for($i=0;$i<$times;$i++)
{
$fname = 'test.txt';
if(file_exists( $fname))
{
$fp=fopen($fname,"r");//flock($fp,LOCK_EX);
$file_data=fread($fp, filesize($fname) );//rewind($fp);
fclose($fp);
}
$content = fnGetContent('test.txt');
}
echo 'fopen read directly '.$times.'Times:'.(fnGetMicroTime()-$begin).'seconds
';
Query results for 4K size data:
fetch_row 100000 times: 16.737720012665 seconds
fetch_array 100000 times: 16.661195993423 seconds
fetch_object 100000 times: 16.775065898895 seconds
Directly read file test results:
File_get_contents read directly 100000 times time: 5.4631857872009 seconds
fopen directly read 100000 times time: 11.463611125946 seconds
Plastic ID query result:
fetch_row 100000 times time: 12.812072038651 seconds
fetch_array 100000 times time: 12.667390108109 Seconds
fetch_object 100000 times time: 12.988099098206 seconds
Direct file reading test results:
file_get_contents direct reading 100000 times time: 5.6616430282593 seconds
fopen direct reading 100000 times time: 11.542816877365 seconds
Test conclusion:
1. Reading files directly is more efficient than database query, and the connection and disconnection time is not included in the article.
2. The larger the content read at one time, the more obvious the advantage of reading the file directly (the file reading time increases slightly, which is related to the continuity of file storage and cluster size). This result is exactly related to the sky. It is the opposite of what was expected, indicating that MYSQL may have additional operations for reading larger files (the time has increased by nearly 30% twice). If it is just a simple assignment conversion, the difference should be small.
3. It can be inferred that the database efficiency will only get worse without testing when writing files and INSERT.
4. If a small configuration file does not need to use database features, it is more suitable to be stored in a separate file. There is no need to create a separate data table or record. Large files such as pictures, music, etc. are more suitable for file storage. For convenience, it is more reasonable to only put index information such as paths or thumbnails into the database.
5. If you only read files on PHP, file_get_contents is more efficient than fopen and fclose, excluding the time required to determine the existence of this function, which will be about 3 seconds shorter.
6. fetch_row and fetch_object should be converted from fetch_array. I have not seen the source code of PHP. From the execution alone, it can be seen that fetch_array is more efficient. This seems to be contrary to what is said on the Internet.
In fact, before doing this test, I had a rough idea of the results based on my personal experience. After the test was completed, I felt a sense of enlightenment. Assuming that the program efficiency is equivalent to that of key processes and does not include caching and other measures, reading and writing any type of data is not as fast as directly operating files. Regardless of the MSYQL process, the "file" must be read from the disk in the end. (Equivalent to the record store), so of course the premise of all this is that the content is read-only and has nothing to do with any sorting or search operations.

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to turn productivity mode on or off for an app or process in Windows 11
Apr 14, 2023 pm 09:46 PM
How to turn productivity mode on or off for an app or process in Windows 11
Apr 14, 2023 pm 09:46 PM
The new Task Manager in Windows 11 22H2 is a boon for power users. It now provides a better UI experience with additional data to keep tabs on your running processes, tasks, services, and hardware components. If you've been using the new Task Manager, you may have noticed the new productivity mode. what is it? Does it help improve the performance of Windows 11 systems? Let’s find out! What is Productivity Mode in Windows 11? Productivity mode is one of the tasks in Task Manager
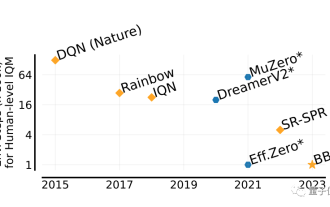 He can surpass humans in two hours! DeepMind's latest AI speedruns 26 Atari games
Jul 03, 2023 pm 08:57 PM
He can surpass humans in two hours! DeepMind's latest AI speedruns 26 Atari games
Jul 03, 2023 pm 08:57 PM
DeepMind’s AI agent is at work again! Pay attention, this guy named BBF mastered 26 Atari games in just 2 hours. His efficiency is equivalent to that of humans, surpassing all his predecessors. You know, AI agents have always been effective in solving problems through reinforcement learning, but the biggest problem is that this method is very inefficient and requires a long time to explore. Picture The breakthrough brought by BBF is in terms of efficiency. No wonder its full name can be called Bigger, Better, or Faster. Moreover, it can complete training on only a single card, and the computing power requirements are also much reduced. BBF was jointly proposed by Google DeepMind and the University of Montreal, and the data and code are currently open source. The highest attainable human
 PyCharm Remote Development Practical Guide: Improve Development Efficiency
Feb 23, 2024 pm 01:30 PM
PyCharm Remote Development Practical Guide: Improve Development Efficiency
Feb 23, 2024 pm 01:30 PM
PyCharm is a powerful Python integrated development environment (IDE) that is widely used by Python developers for code writing, debugging and project management. In the actual development process, most developers will face different problems, such as how to improve development efficiency, how to collaborate with team members on development, etc. This article will introduce a practical guide to remote development of PyCharm to help developers better use PyCharm for remote development and improve work efficiency. 1. Preparation work in PyCh
 Private deployment of Stable Diffusion to play with AI drawing
Mar 12, 2024 pm 05:49 PM
Private deployment of Stable Diffusion to play with AI drawing
Mar 12, 2024 pm 05:49 PM
StableDiffusion is an open source deep learning model. Its main function is to generate high-quality images through text descriptions, and supports functions such as graph generation, model merging, and model training. The operating interface of the model can be seen in the figure below. How to generate a picture. The following is an introduction to the process of creating a picture of a deer drinking water. When generating a picture, it is divided into prompt words and negative prompt words. When entering the prompt words, you must describe it clearly and try to describe the scene, object, style and color you want in detail. . For example, instead of just saying "the deer drinks water", it says "a creek, next to dense trees, and there are deer drinking water next to the creek". The negative prompt words are in the opposite direction. For example: no buildings, no people , no bridges, no fences, and too vague description may lead to inaccurate results.
 Java development skills revealed: Optimizing database transaction processing efficiency
Nov 20, 2023 pm 03:13 PM
Java development skills revealed: Optimizing database transaction processing efficiency
Nov 20, 2023 pm 03:13 PM
With the rapid development of the Internet, the importance of databases has become increasingly prominent. As a Java developer, we often involve database operations. The efficiency of database transaction processing is directly related to the performance and stability of the entire system. This article will introduce some techniques commonly used in Java development to optimize database transaction processing efficiency to help developers improve system performance and response speed. Batch insert/update operations Normally, the efficiency of inserting or updating a single record into the database at one time is much lower than that of batch operations. Therefore, when performing batch insert/update
 How to turn on power saving mode in Microsoft Edge?
Apr 20, 2023 pm 08:22 PM
How to turn on power saving mode in Microsoft Edge?
Apr 20, 2023 pm 08:22 PM
Chromium-based browsers like Edge use a lot of resources, but you can enable efficiency mode in Microsoft Edge to improve performance. The Microsoft Edge web browser has come a long way since its humble beginnings. Recently, Microsoft added a new efficiency mode to the browser, which is designed to improve the overall performance of the browser on PC. Efficiency mode helps extend battery life and reduce system resource usage. For example, browsers built with Chromium, such as Google Chrome and Microsoft Edge, are notorious for hogging RAM and CPU cycles. Therefore, in order
 Master Python to improve work efficiency and quality of life
Feb 18, 2024 pm 05:57 PM
Master Python to improve work efficiency and quality of life
Feb 18, 2024 pm 05:57 PM
Title: Python makes life more convenient: Master this language to improve work efficiency and quality of life. As a powerful and easy-to-learn programming language, Python is becoming more and more popular in today's digital era. Not just for writing programs and performing data analysis, Python can also play a huge role in our daily lives. Mastering this language can not only improve work efficiency, but also improve the quality of life. This article will use specific code examples to demonstrate the wide application of Python in life and help readers
 Subnet mask: role and impact on network communication efficiency
Dec 26, 2023 pm 04:28 PM
Subnet mask: role and impact on network communication efficiency
Dec 26, 2023 pm 04:28 PM
The role of subnet mask and its impact on network communication efficiency Introduction: With the popularity of the Internet, network communication has become an indispensable part of modern society. At the same time, the efficiency of network communication has also become one of the focuses of people's attention. In the process of building and managing a network, subnet mask is an important and basic configuration option, which plays a key role in network communication. This article will introduce the role of subnet mask and its impact on network communication efficiency. 1. Definition and function of subnet mask Subnet mask (subnetmask)
