

Summary of AWK syntax under shell programming_PHP tutorial

The AWK utility comes with its own self-contained language and is one of the most powerful data processing engines available in Unix/Linux or any environment. The greatest power of this programming and data manipulation language (which takes its name from the first letters of the surnames of its founders, Alfred Aho, Peter Weinberger, and Brian Kernighan) depends on the knowledge one possesses. It allows you to create short programs that read input files, sort the data, process the data, perform calculations on the input, and generate reports, among countless other functions.
What is AWK? At its simplest, AWK is a programming language tool for working with text. The language of the AWK utility is similar in many ways to the shell programming language, although AWK has a syntax that is entirely its own. When AWK was originally created, it was intended for text processing, and the basis of the language was to execute a sequence of instructions whenever there was a pattern match in the input data. This utility scans each line in a file for patterns that match what is given on the command line. If a match is found, proceed to the next programming step. If no match is found, continue processing the next line. Although the operation can be complex, the syntax of the command is always: awk {pattern + action} where pattern represents what AWK looks for in the data, and action is a sequence of commands that are executed when a match is found. Curly braces ({}) do not need to appear all the time in a program, but they are used to group a sequence of instructions according to a specific pattern. Understanding Fields The utility divides each input row into records and fields. A record is a single line of input, and each record contains several fields. The default field delimiter is space or tab, and the record delimiter is newline. Although both tabs and spaces are treated as field separators by default (multiple spaces still act as one separator), you can change the separator from a space to any other character. For demonstration, view the following employee list file saved as emp_names: 46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH P HOENIX AZ46022 KANE SHERYL UNKNOWN AR46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN When AWK reads the input content, the entire record is assigned to the variable. Each field is separated by a field delimiter and assigned to variables , , etc. A row can contain essentially an infinite number of fields, each of which is accessed by its field number. Therefore, the print output that the command awk {print ,,,,} names will produce is 46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AR46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN One important thing to note is that AWK interprets five fields separated by spaces, but when it prints the display, between each field There is only one space. With the ability to assign a unique number to each field, you can choose to print only specific fields. For example, to print only the names of each record, just select the second and third fields to print: $ awk {print ,} emp_namesDULANEY EVANDURHAM JEFFSTEEN BILLFELDMAN EVANSWIM STEVEBOGUE ROBERTJUNE MICAHKANE SHERYLWOOD WILLIAMFERGUS SARAHBUCK SARAHTUTTLE BOB$ You can also specify the by Print fields in any order, regardless of how they exist in the record. So, just display the name field, and reverse the order, displaying first name first and then last name: $ awk {print ,} emp_namesEVAN DULANEYJEFF DURHAMBILL STEENEVAN FELDMANSTEVE SWIMROBERT BOGUEMICAH JUNESHERYL KANEWILLIAM WOODSARAH FERGUSSARAH BUCKBOB TUTTLE$ Use patterns by including a pattern that must match , you can choose to operate only on specific records instead of all records. The simplest form of pattern matching is a search, where the item to match is enclosed in slashes (/pattern/). For example, to perform the previous operation only for those employees who live in Alabama: $ awk /AL/ {print ,} emp_namesEVAN DULANEYJEFF DURHAMBILL STEENEVAN FELDMANSTEVE SWIM$ If you do not specify the fields to print, the entire matching entry will be printed : $ awk /AL/ emp_names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL$ Multiple commands for the same data set can be separated by semicolons (;). For example, to print the name on one line and the city and state on another: $ awk /AL/ {print , ; print ,} emp_namesEVAN DULANEYMOBILE ALJEFF DURHAMMOBILE ALBILL STEENMOBILE ALEVAN FELDMANMOBILE ALSTEVE SWIMUNKNOWN AL$ If no semicolon is used (print ,,,) will display everything on the same line.On the other hand, if the two print statements are given separately, it will produce completely different results: $ awk /AL/ {print ,} {print ,} emp_namesEVAN DULANEYMOBILE ALJEFF DURHAMMOBILE ALBILL STEENMOBILE ALEVAN FELDMANMOBILE ALSTEVE SWIMUNKNOWN ALPHOENIX AZPHOENIX AZUNKNOWN ARMUNCIE INMUNCIE INMUNCIE INMUNCIE IN$ will only give fields three and two if AL is found in the list. However, fields four and five are unconditional and they are always printed. Only the command in the first set of curly braces has an effect on the command immediately preceding it (/AL/). The result is very unreadable and could be made slightly clearer. First, insert a space and comma between the city and state. Then, place a blank line after every two lines displayed: $ awk /AL/ {print , ; print ", ""n"} emp_namesEVAN DULANEYMOBILE, ALJEFF DURHAMMOBILE, ALBILL STEENMOBILE, ALEVAN FELDMANMOBILE, ALSTEVE SWIMUNKNOWN, AL$ on the fourth and the fifth field, add a comma and a space (between the quotes), and after the fifth field, print a newline character (n). All the special characters that can be used in the echo command can also be used in the AWK print statement, including: n (newline) t (tab) b (backspace) f (feed) r (carriage return) Therefore, to read To take all five fields initially separated by tabs and print them using tabs too, you can program as follows $ awk {print "t""t""t""t"} emp_names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AR46024 WOOD WILLIAM MUNCIE IN460 26 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN$ by setting multiple items consecutively Standard and separated by pipe (|) symbols, you can search for multiple pattern matches at once: $ awk /AL|IN/ emp_names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN$ This will find matching records for every resident of Alabama and Indiana. But while trying to find out who lives in Arizona, a problem arises: $ awk /AR/ emp_names46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AZ46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN$Employees 46026 and 4 6027 No Live in Arizona; but their names contain the sequence of characters being searched for. Keep in mind that when doing pattern matching in AWK, such as grep, sed, or most other Linux/Unix commands, a match will be found anywhere in the record (line) unless otherwise specified. To solve this problem, the search must be tied to a specific field. This is accomplished by utilizing a tilde (?) along with a description of a specific field, as shown in the following example: $ awk ? /AR/ emp_names46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AZ$ tilde (indicates a match ) is a tilde (!?) preceded by an exclamation point. These characters tell the program to find all rows that match the search sequence if it does not appear in the specified field: $ awk !? /AR/ names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN$ In this case, all rows without an AR in the fifth field will be displayed—including the two Sarah entries, both of which The entry does contain an AR, but in the third field instead of the fifth. Braces and field delimiters The brace characters play an important role in AWK commands. Actions that appear between parentheses indicate what is going to happen and when. When using only one pair of brackets: {print,} all operations between the brackets occur simultaneously. When using more than one pair of parentheses: {print }{print } executes the first set of commands, and after that command completes, executes the second set of commands. Note the difference between the following two lists: $ awk {print ,} namesEVAN DULANEYJEFF DURHAMBILL STEENEVAN FELDMANSTEVE SWIMROBERT BOGUEMICAH JUNESHERYL KANEWILLIAM WOODSARAH FERGUSSARAH BUCKBOB TUTTLE$$ awk {print }{print } namesEVANDULANEYJEFFDURHAMBILLSTEENEVANFELDMANSTEVESWIMROBER TBOGUEMICAHJUNESHERYLKANEWILLIAMWOODSARAHFERGUSSARAHBUCKBOBTUTTLE$ To use multiple sets of brackets to perform repeated searches, execute the first The commands in the group are processed until completion; then the second group of commands is processed. If there is a third set of commands, it is executed after the second set of commands completes, and so on. In the resulting printout, there are two separate print commands, so the first command is executed first, followed by the second command, causing each entry to appear on two lines instead of one. The field separator that distinguishes two fields does not always have to be a space; it can be any recognized character.For demonstration purposes, assume that the emp_names file uses colons instead of tabs to separate fields: $ cat emp_names46012:DULANEY:EVAN:MOBILE:AL46013:DURHAM:JEFF:MOBILE:AL46015:STEEN:BILL:MOBILE:AL46017:FELDMAN:EVAN: MOBILE:AL46018:SWIM:STEEVE:UNKNOWN:AL46019:BOGUE:ROBERT:PHOENIX:AZ46021:JUNE:MICAH:PHOENIX:AZ46022:KANE:SHERYL:UNKNOWN:AR46024:WOOD:WILLIAM:MUNCIE:IN4602

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Remove duplicate values from PHP array using regular expressions
Apr 26, 2024 pm 04:33 PM
Remove duplicate values from PHP array using regular expressions
Apr 26, 2024 pm 04:33 PM
How to remove duplicate values from PHP array using regular expressions: Use regular expression /(.*)(.+)/i to match and replace duplicates. Iterate through the array elements and check for matches using preg_match. If it matches, skip the value; otherwise, add it to a new array with no duplicate values.
 KDE Plasma 6.1 brings many enhancements to the popular Linux desktop
Jun 23, 2024 am 07:54 AM
KDE Plasma 6.1 brings many enhancements to the popular Linux desktop
Jun 23, 2024 am 07:54 AM
After several pre-releases, the KDE Plasma development team unveiled version 6.0 of its desktop environment for Linux and BSD systems on 28 February, using the Qt6 framework for the first time. KDE Plasma 6.1 now comes with a number of new features t
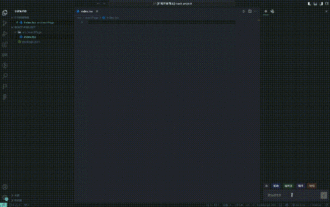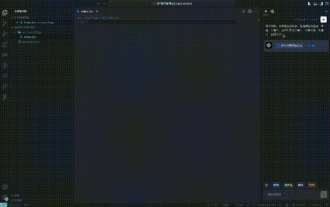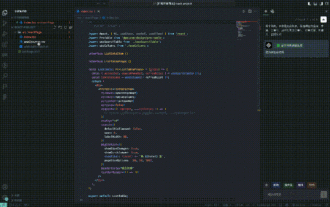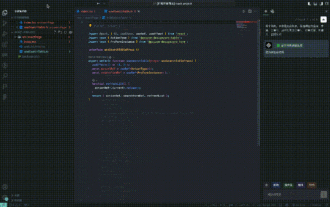 Thoughts and practice on assisted generation of B-end front-end code under large models
Apr 18, 2024 am 09:30 AM
Thoughts and practice on assisted generation of B-end front-end code under large models
Apr 18, 2024 am 09:30 AM
1. Code specifications during background reconstruction work: During the B-end front-end development process, developers will always face the pain point of repeated development. The element modules of many CRUD pages are basically similar, but they still need to be developed manually, and time is spent on simple element construction. This reduces the development efficiency of business requirements. At the same time, because the coding styles of different developers are inconsistent, it makes it more expensive for others to get started during iterations. AI replaces simple brainpower: With the continuous development of large AI models, it has simple understanding capabilities and can convert language into instructions. General instructions for building basic pages can meet the needs of daily basic page building and improve the efficiency of business development in general scenarios. 2. Generate link list. B-side page lists, forms, and details can all be generated. Links can be roughly divided into the following categories:
 What are the syntax and structure characteristics of lambda expressions?
Apr 25, 2024 pm 01:12 PM
What are the syntax and structure characteristics of lambda expressions?
Apr 25, 2024 pm 01:12 PM
Lambda expression is an anonymous function without a name, and its syntax is: (parameter_list)->expression. They feature anonymity, diversity, currying, and closure. In practical applications, Lambda expressions can be used to define functions concisely, such as the summation function sum_lambda=lambdax,y:x+y, and apply the map() function to the list to perform the summation operation.
 The difference between PHP functions and Shell functions
Apr 24, 2024 pm 06:39 PM
The difference between PHP functions and Shell functions
Apr 24, 2024 pm 06:39 PM
The main differences between PHP functions and Shell functions are security (PHP functions are more secure), reliability (Shell functions vary by operating system), functionality (Shell functions are more powerful but limited by the shell), and performance (PHP functions are usually faster) and complexity (Shell functions are more complex). They are both used for file system, process and command operations, but PHP functions are built-in, while Shell functions are called through an external shell. Therefore, in server file download scenarios, the file_put_contents() function is safer, while the wget command is more flexible.
 The Mistral open source code model takes the throne! Codestral is crazy about training in over 80 languages, and domestic Tongyi developers are asking to participate!
Jun 08, 2024 pm 09:55 PM
The Mistral open source code model takes the throne! Codestral is crazy about training in over 80 languages, and domestic Tongyi developers are asking to participate!
Jun 08, 2024 pm 09:55 PM
Produced by 51CTO technology stack (WeChat ID: blog51cto) Mistral released its first code model Codestral-22B! What’s crazy about this model is not only that it’s trained on over 80 programming languages, including Swift, etc. that many code models ignore. Their speeds are not exactly the same. It is required to write a "publish/subscribe" system using Go language. The GPT-4o here is being output, and Codestral is handing in the paper so fast that it’s hard to see! Since the model has just been launched, it has not yet been publicly tested. But according to the person in charge of Mistral, Codestral is currently the best-performing open source code model. Friends who are interested in the picture can move to: - Hug the face: https
 What is programming for and what is the use of learning it?
Apr 28, 2024 pm 01:34 PM
What is programming for and what is the use of learning it?
Apr 28, 2024 pm 01:34 PM
1. Programming can be used to develop various software and applications, including websites, mobile applications, games, and data analysis tools. Its application fields are very wide, covering almost all industries, including scientific research, health care, finance, education, entertainment, etc. 2. Learning programming can help us improve our problem-solving skills and logical thinking skills. During programming, we need to analyze and understand problems, find solutions, and translate them into code. This way of thinking can cultivate our analytical and abstract abilities and improve our ability to solve practical problems.
 The Key to Coding: Unlocking the Power of Python for Beginners
Oct 11, 2024 pm 12:17 PM
The Key to Coding: Unlocking the Power of Python for Beginners
Oct 11, 2024 pm 12:17 PM
Python is an ideal programming introduction language for beginners through its ease of learning and powerful features. Its basics include: Variables: used to store data (numbers, strings, lists, etc.). Data type: Defines the type of data in the variable (integer, floating point, etc.). Operators: used for mathematical operations and comparisons. Control flow: Control the flow of code execution (conditional statements, loops).
