
 Backend Development
Python Tutorial
Sharing code examples of Python simulating logging into Taobao and counting Taobao consumption
Backend Development
Python Tutorial
Sharing code examples of Python simulating logging into Taobao and counting Taobao consumption
Sharing code examples of Python simulating logging into Taobao and counting Taobao consumption

The numbers on Alipay’s ten-year bill are a bit scary, but it counts too many items. I just wanted to see how much I spent on Taobao, so I wrote a script to count the consumption of Taobao orders in any period of time. Judging from the results, I am actually quite frugal on Taobao.
The main job of the script is to simulate browser login and parse the "Purchased Baby" page to obtain the specified order and baby information.
For usage, see the code or execute the command with parameter -h. In addition, BeautifulSoup4 support is required. BeautifulSoup’s official project list page: https://www.crummy.com/software/BeautifulSoup/bs4/download/
First let’s talk about how to use the code:
python taobao.py -u USERNAME -p PASSWORD -s START-DATE -e END-DATE --verbose
All parameters are optional, such as:
python taobao.py -u jinnlynn
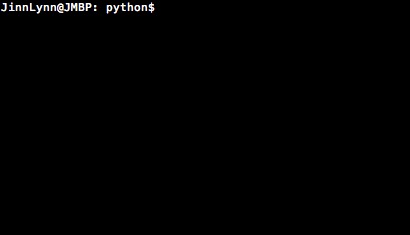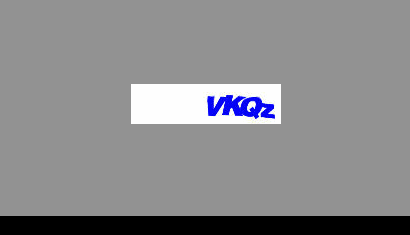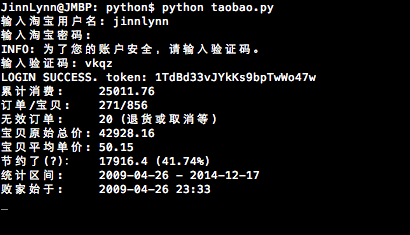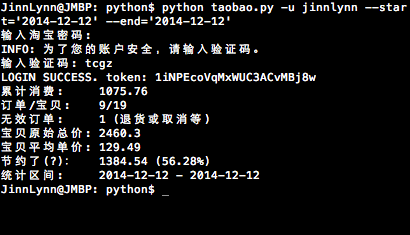
Statistics on all orders of user jinnlynn
python taobao.py -s 2014-12-12 -e 2014-12-12
Statistics on the order status of users (the user name will be required to be entered when the command is executed) on 2014-12-12
python taobao.py --verbose
In this way, order details can be counted and output.
Okay, having said so much, let’s take a look at the code:
from __future__ import unicode_literals, print_function, absolute_import, division
import urllib
import urllib2
import urlparse
import cookielib
import re
import sys
import os
import json
import subprocess
import argparse
import platform
from getpass import getpass
from datetime import datetime
from pprint import pprint
try:
from bs4 import BeautifulSoup
except ImportError:
sys.exit('BeautifulSoup4 missing.')
__version__ = '1.0.0'
__author__ = 'JinnLynn'
__copyright__ = 'Copyright (c) 2014 JinnLynn'
__license__ = 'The MIT License'
HEADERS = {
'x-requestted-with' : 'XMLHttpRequest',
'Accept-Language' : 'zh-cn',
'Accept-Encoding' : 'gzip, deflate',
'ContentType' : 'application/x-www-form-urlencoded; chartset=UTF-8',
'Cache-Control' : 'no-cache',
'User-Agent' :'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.38 Safari/537.36',
'Connection' : 'Keep-Alive'
}
DEFAULT_POST_DATA = {
'TPL_username' : '', #用户名
'TPL_password' : '', #密码
'TPL_checkcode' : '',
'need_check_code' : 'false',
'callback' : '0', # 有值返回JSON
}
# 无效订单状态
INVALID_ORDER_STATES = [
'CREATE_CLOSED_OF_TAOBAO', # 取消
'TRADE_CLOSED', # 订单关闭
]
LOGIN_URL = 'https://login.taobao.com/member/login.jhtml'
RAW_IMPUT_ENCODING = 'gbk' if platform.system() == 'Windows' else 'utf-8'
def _request(url, data, method='POST'):
if data:
data = urllib.urlencode(data)
if method == 'GET':
if data:
url = '{}?{}'.format(url, data)
data = None
# print(url)
# print(data)
req = urllib2.Request(url, data, HEADERS)
return urllib2.urlopen(req)
def stdout_cr(msg=''):
sys.stdout.write('\r{:10}'.format(' '))
sys.stdout.write('\r{}'.format(msg))
sys.stdout.flush()
def get(url, data=None):
return _request(url, data, method='GET')
def post(url, data=None):
return _request(url, data, method='POST')
def login_post(data):
login_data = DEFAULT_POST_DATA
login_data.update(data)
res = post(LOGIN_URL, login_data)
return json.load(res, encoding='gbk')
def login(usr, pwd):
data = {
'TPL_username' : usr.encode('utf-8' if platform.system() == 'Windows' else 'GB18030'),
'TPL_password' : pwd
}
# 1. 尝试登录
ret = login_post(data)
while not ret.get('state', False):
code = ret.get('data', {}).get('code', 0)
if code == 3425 or code == 1000:
print('INFO: {}'.format(ret.get('message')))
check_code = checkcode(ret.get('data', {}).get('ccurl'))
data.update({'TPL_checkcode' : check_code, 'need_check_code' : 'true'})
ret = login_post(data)
else:
sys.exit('ERROR. code: {}, message:{}'.format(code, ret.get('message', '')))
token = ret.get('data', {}).get('token')
print('LOGIN SUCCESS. token: {}'.format(token))
# 2. 重定向
# 2.1 st值
res = get('https://passport.alipay.com/mini_apply_st.js', {
'site' : '0',
'token' : token,
'callback' : 'stCallback4'})
content = res.read()
st = re.search(r'"st":"(\S*)"( |})', content).group(1)
# 2.1 重定向
get('http://login.taobao.com/member/vst.htm',
{'st' : st, 'TPL_uesrname' : usr.encode('GB18030')})
def checkcode(url):
filename, _ = urllib.urlretrieve(url)
if not filename.endswith('.jpg'):
old_fn = filename
filename = '{}.jpg'.format(filename)
os.rename(old_fn, filename)
if platform.system() == 'Darwin':
# mac 下直接preview打开
subprocess.call(['open', filename])
elif platform.system() == 'Windows':
# windows 执行文件用默认程序打开
subprocess.call(filename, shell=True)
else:
# 其它系统 输出文件名
print('打开该文件获取验证码: {}'.format(filename))
return raw_input('输入验证码: '.encode(RAW_IMPUT_ENCODING))
def parse_bought_list(start_date=None, end_date=None):
url = 'http://buyer.trade.taobao.com/trade/itemlist/list_bought_items.htm'
# 运费险 增值服务 分段支付(定金,尾款)
extra_service = ['freight-info', 'service-info', 'stage-item']
stdout_cr('working... {:.0%}'.format(0))
# 1. 解析第一页
res = urllib2.urlopen(url)
soup = BeautifulSoup(res.read().decode('gbk'))
# 2. 获取页数相关
page_jump = soup.find('span', id='J_JumpTo')
jump_url = page_jump.attrs['data-url']
url_parts = urlparse.urlparse(jump_url)
query_data = dict(urlparse.parse_qsl(url_parts.query))
total_pages = int(query_data['tPage'])
# 解析
orders = []
cur_page = 1
out_date = False
errors = []
while True:
bought_items = soup.find_all('tbody', attrs={'data-orderid' : True})
# pprint(len(bought_items))
count = 0
for item in bought_items:
count += 1
# pprint('{}.{}'.format(cur_page, count))
try:
info = {}
# 订单在页面上的位置 页数.排序号
info['pos'] = '{}.{}'.format(cur_page, count)
info['orderid'] = item.attrs['data-orderid']
info['status'] = item.attrs['data-status']
# 店铺
node = item.select('tr.order-hd a.shopname')
if not node:
# 店铺不存在,可能是赠送彩票订单,忽略
# print('ignore')
continue
info['shop_name'] = node[0].attrs['title'].strip()
info['shop_url'] = node[0].attrs['href']
# 日期
node = item.select('tr.order-hd span.dealtime')[0]
info['date'] = datetime.strptime(node.attrs['title'], '%Y-%m-%d %H:%M')
if end_date and info['date'].toordinal() > end_date.toordinal():
continue
if start_date and info['date'].toordinal() < start_date.toordinal():
out_date = True
break
# 宝贝
baobei = []
node = item.find_all('tr', class_='order-bd')
# pprint(len(node))
for n in node:
try:
bb = {}
if [True for ex in extra_service if ex in n.attrs['class']]:
# 额外服务处理
# print('额外服务处理')
name_node = n.find('td', class_='baobei')
# 宝贝地址
bb['name'] = name_node.text.strip()
bb['url'] = ''
bb['spec'] = ''
# 宝贝快照
bb['snapshot'] = ''
# 宝贝价格
bb['price'] = 0.0
# 宝贝数量
bb['quantity'] = 1
bb['is_goods'] = False
try:
bb['url'] = name_node.find('a').attrs['href']
bb['price'] = float(n.find('td', class_='price').text)
except:
pass
else:
name_node = n.select('p.baobei-name a')
# 宝贝地址
bb['name'] = name_node[0].text.strip()
bb['url'] = name_node[0].attrs['href']
# 宝贝快照
bb['snapshot'] = ''
if len(name_node) > 1:
bb['snapshot'] = name_node[1].attrs['href']
# 宝贝规格
bb['spec'] = n.select('.spec')[0].text.strip()
# 宝贝价格
bb['price'] = float(n.find('td', class_='price').attrs['title'])
# 宝贝数量
bb['quantity'] = int(n.find('td', class_='quantity').attrs['title'])
bb['is_goods'] = True
baobei.append(bb)
# 尝试获取实付款
# 实付款所在的节点可能跨越多个tr的td
amount_node = n.select('td.amount em.real-price')
if amount_node:
info['amount'] = float(amount_node[0].text)
except Exception as e:
errors.append({
'type' : 'baobei',
'id' : '{}.{}'.format(cur_page, count),
'node' : '{}'.format(n),
'error' : '{}'.format(e)
})
except Exception as e:
errors.append({
'type' : 'order',
'id' : '{}.{}'.format(cur_page, count),
'node' : '{}'.format(item),
'error' : '{}'.format(e)
})
info['baobei'] = baobei
orders.append(info)
stdout_cr('working... {:.0%}'.format(cur_page / total_pages))
# 下一页
cur_page += 1
if cur_page > total_pages or out_date:
break
query_data.update({'pageNum' : cur_page})
page_url = '{}?{}'.format(url, urllib.urlencode(query_data))
res = urllib2.urlopen(page_url)
soup = BeautifulSoup(res.read().decode('gbk'))
stdout_cr()
if errors:
print('INFO. 有错误发生,统计结果可能不准确。')
# pprint(errors)
return orders
def output(orders, start_date, end_date):
amount = 0.0
org_amount = 0
baobei_count = 0
order_count = 0
invaild_order_count = 0
for order in orders:
if order['status'] in INVALID_ORDER_STATES:
invaild_order_count += 1
continue
amount += order['amount']
order_count += 1
for baobei in order.get('baobei', []):
if not baobei['is_goods']:
continue
org_amount += baobei['price'] * baobei['quantity']
baobei_count += baobei['quantity']
print('{:<9} {}'.format('累计消费:', amount))
print('{:<9} {}/{}'.format('订单/宝贝:', order_count, baobei_count))
if invaild_order_count:
print('{:<9} {} (退货或取消等, 不在上述订单之内)'.format('无效订单:', invaild_order_count))
print('{:<7} {}'.format('宝贝原始总价:', org_amount))
print('{:<7} {:.2f}'.format('宝贝平均单价:', 0 if baobei_count == 0 else org_amount / baobei_count))
print('{:<9} {} ({:.2%})'.format('节约了(?):',
org_amount - amount,
0 if org_amount == 0 else (org_amount - amount) / org_amount))
from_date = start_date if start_date else orders[-1]['date']
to_date = end_date if end_date else datetime.now()
print('{:<9} {:%Y-%m-%d} - {:%Y-%m-%d}'.format('统计区间:', from_date, to_date))
if not start_date:
print('{:<9} {:%Y-%m-%d %H:%M}'.format('败家始于:', orders[-1]['date']))
def ouput_orders(orders):
print('所有订单:')
if not orders:
print(' --')
return
for order in orders:
print(' {:-^20}'.format('-'))
print(' * 订单号: {orderid} 实付款: {amount} 店铺: {shop_name} 时间: {date:%Y-%m-%d %H:%M}'.format(**order))
for bb in order['baobei']:
if not bb['is_goods']:
continue
print(' - {name}'.format(**bb))
if bb['spec']:
print(' {spec}'.format(**bb))
print(' {price} X {quantity}'.format(**bb))
def main():
parser = argparse.ArgumentParser(
prog='python {}'.format(__file__)
)
parser.add_argument('-u', '--username', help='淘宝用户名')
parser.add_argument('-p', '--password', help='淘宝密码')
parser.add_argument('-s', '--start', help='起始时间,可选, 格式如: 2014-11-11')
parser.add_argument('-e', '--end', help='结束时间,可选, 格式如: 2014-11-11')
parser.add_argument('--verbose', action='store_true', default=False, help='订单详细输出')
parser.add_argument('-v', '--version', action='version',
version='v{}'.format(__version__), help='版本号')
args = parser.parse_args()
usr = args.username
if not usr:
usr = raw_input('输入淘宝用户名: '.encode(RAW_IMPUT_ENCODING))
usr = usr.decode('utf-8') # 中文输入问题
pwd = args.password
if not pwd:
if platform.system() == 'Windows':
# Windows下中文输出有问题
pwd = getpass()
else:
pwd = getpass('输入淘宝密码: '.encode('utf-8'))
pwd = pwd.decode('utf-8')
verbose = args.verbose
start_date = None
if args.start:
try:
start_date = datetime.strptime(args.start, '%Y-%m-%d')
except Exception as e:
sys.exit('ERROR. {}'.format(e))
end_date = None
if args.end:
try:
end_date = datetime.strptime(args.end, '%Y-%m-%d')
except Exception as e:
sys.exit('ERROR. {}'.format(e))
if start_date and end_date and start_date > end_date:
sys.exit('ERROR, 结束日期必须晚于或等于开始日期')
cj_file = './{}.tmp'.format(usr)
cj = cookielib.LWPCookieJar()
try:
cj.load(cj_file)
except:
pass
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj), urllib2.HTTPHandler)
urllib2.install_opener(opener)
login(usr, pwd)
try:
cj.save(cj_file)
except:
pass
orders = parse_bought_list(start_date, end_date)
output(orders, start_date, end_date)
# 输出订单明细
if verbose:
ouput_orders(orders)
if __name__ == '__main__':
main()

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python have their own advantages and disadvantages, and the choice depends on project needs and personal preferences. 1.PHP is suitable for rapid development and maintenance of large-scale web applications. 2. Python dominates the field of data science and machine learning.
 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python excels in automation, scripting, and task management. 1) Automation: File backup is realized through standard libraries such as os and shutil. 2) Script writing: Use the psutil library to monitor system resources. 3) Task management: Use the schedule library to schedule tasks. Python's ease of use and rich library support makes it the preferred tool in these areas.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
