
 Backend Development
Python Tutorial
Analysis of the key points of writing a basic code interpreter using Python
Backend Development
Python Tutorial
Analysis of the key points of writing a basic code interpreter using Python
Analysis of the key points of writing a basic code interpreter using Python

I have always been very interested in compilers and parsers. I am also very clear about the concept and overall framework of a compiler, but I don’t know much about the details. The program source code we write is actually a sequence of characters. The compiler or interpreter can directly understand and execute this sequence of characters. This seems really amazing. This article will use Python to implement a simple parser to interpret a small list manipulation language (similar to python's list). In fact, compilers and interpreters are not mysterious. As long as the basic theory is understood, implementation is relatively simple (of course, a product-level compiler or interpreter is still very complicated).
Operations supported by this list language:
veca = [1, 2, 3] # 列表声明 vecb = [4, 5, 6] print 'veca:', veca # 打印字符串、列表,print expr+ print 'veca * 2:', veca * 2 # 列表与整数乘法 print 'veca + 2:', veca + 2 # 列表与整数加法 print 'veca + vecb:', veca + vecb # 列表加法 print 'veca + [11, 12]:', veca + [11, 12] print 'veca * vecb:', veca * vecb # 列表乘法 print 'veca:', veca print 'vecb:', vecb
Corresponding output:
veca: [1, 2, 3] veca * 2: [2, 4, 6] veca + 2: [1, 2, 3, 2] veca + vecb: [1, 2, 3, 2, 4, 5, 6] veca + [11, 12]: [1, 2, 3, 2, 11, 12] veca * vecb: [4, 5, 6, 8, 10, 12, 12, 15, 18, 8, 10, 12] veca: [1, 2, 3, 2] vecb: [4, 5, 6]
When compilers and interpreters process input character streams, they are basically consistent with the way humans understand sentences. For example:
I love you.
If you are new to learning English, you first need to know the meaning of each word, and then analyze the part of speech of each word to conform to the subject-predicate-object structure, so that you can understand the meaning of this sentence. This sentence is a character sequence. According to the lexical division, a lexical unit stream is obtained. In fact, this is lexical analysis, which completes the conversion from the character stream to the lexical unit stream. Analyzing the part of speech and determining the subject-verb-object structure is to identify this structure according to English grammar. This is grammatical analysis, and the grammatical parsing tree is identified based on the input lexical unit flow. Finally, combining the meaning of the word and the grammatical structure, the meaning of the sentence is finally obtained. This is semantic analysis. The processing process of compiler and interpreter is similar, but it is slightly more complicated. Here we only focus on the interpreter:
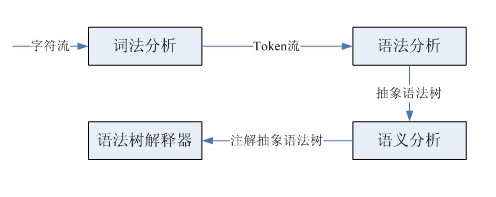
We are just implementing a very simple small language, so it does not involve the generation of syntax trees and subsequent complex semantic analysis. Next I will take a look at lexical analysis and syntax analysis.
Lexical analysis and syntax analysis are completed by lexical parser and syntax parser respectively. These two parsers have similar structure and functionality. They both take an input sequence as input and then identify specific structures. The lexical parser parses tokens (lexical units) one by one from the source code character stream, and the syntax parser identifies substructures and lexical units, and then performs some processing. Both parsers can be implemented through LL(1) recursive descent parsers. The steps completed by this type of parser are: predict the type of the clause, call the parsing function to match the substructure, match the lexical unit, and then insert code as needed. Perform custom actions.
Here is a brief introduction to LL(1). The structure of a statement is usually represented by a tree structure, called a parse tree. LL(1) relies on the parse tree for syntax parsing. For example: x = x +2;
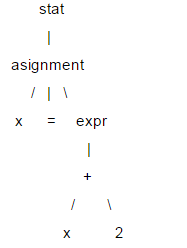
In this tree, leaf nodes like x, =, and 2 are called terminal nodes, and the others are called non-terminal nodes. When parsing LL(1), there is no need to create a specific tree data structure. You can write a parsing function for each non-terminal node and call it when the corresponding node is encountered. In this way, you can pass the parsing function in the calling sequence (equivalent to Tree traversal) to obtain parse tree information. When LL(1) is parsed, it is executed in the order from the root node to the leaf node, so this is a "descending" process, and the parsing function can call itself, so it is "recursive", so LL(1 ) is also called a recursive descent parser.
The two L's in LL(1) both mean left-to-right. The first L means that the parser parses the input content in order from left to right. The second L means that during the descending process, it also analyzes the input content from left to right. Traverse the child nodes in order to the right, and 1 means making predictions based on 1 lookahead unit.
Let's take a look at the implementation of the list mini-language. The first is the grammar of the language. Grammar is used to describe a language and is regarded as the design specification of the parser.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
这是用DSL描述的文法,其中大部分概念和正则表达式类似。"a|b"表示a或者b,所有以单引号括起的字符串是关键字,比如:print,=等。大写的单词是词法单元。可以看到这个小语言的文法还是很简单的。有很多解析器生成器可以自动根据文法生成对应的解析器,比如:ANTRL,flex,yacc等,这里采用手写解析器主要是为了理解解析器的原理。下面看一下这个小语言的解释器是如何实现的。
首先是词法解析器,完成字符流到token流的转换。采用LL(1)实现,所以使用1个向前看字符预测匹配的token。对于像INT、ID这样由多个字符组成的词法规则,解析器有一个与之对应的方法。由于语法解析器并不关心空白字符,所以词法解析器在遇到空白字符时直接忽略掉。每个token都有两个属性类型和值,比如整型、标识符类型等,对于整型类型它的值就是该整数。语法解析器需要根据token的类型进行预测,所以词法解析必须返回类型信息。语法解析器以iterator的方式获取token,所以词法解析器实现了next_token方法,以元组方式(type, value)返回下一个token,在没有token的情况时返回EOF。
'''''
A simple lexer of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
Created on 2012-9-26
@author: bjzllou
'''
EOF = -1
# token type
COMMA = 'COMMA'
EQUAL = 'EQUAL'
LBRACK = 'LBRACK'
RBRACK = 'RBRACK'
TIMES = 'TIMES'
ADD = 'ADD'
PRINT = 'print'
ID = 'ID'
INT = 'INT'
STR = 'STR'
class Veclexer:
'''''
LL(1) lexer.
It uses only one lookahead char to determine which is next token.
For each non-terminal token, it has a rule to handle it.
LL(1) is a quit weak parser, it isn't appropriate for the grammar which is
left-recursive or ambiguity. For example, the rule 'T: T r' is left recursive.
However, it's rather simple and has high performance, and fits simple grammar.
'''
def __init__(self, input):
self.input = input
# current index of the input stream.
self.idx = 1
# lookahead char.
self.cur_c = input[0]
def next_token(self):
while self.cur_c != EOF:
c = self.cur_c
if c.isspace():
self.consume()
elif c == '[':
self.consume()
return (LBRACK, c)
elif c == ']':
self.consume()
return (RBRACK, c)
elif c == ',':
self.consume()
return (COMMA, c)
elif c == '=':
self.consume()
return (EQUAL, c)
elif c == '*':
self.consume()
return (TIMES, c)
elif c == '+':
self.consume()
return (ADD, c)
elif c == '\'' or c == '"':
return self._string()
elif c.isdigit():
return self._int()
elif c.isalpha():
t = self._print()
return t if t else self._id()
else:
raise Exception('not support token')
return (EOF, 'EOF')
def has_next(self):
return self.cur_c != EOF
def _id(self):
n = self.cur_c
self.consume()
while self.cur_c.isalpha():
n += self.cur_c
self.consume()
return (ID, n)
def _int(self):
n = self.cur_c
self.consume()
while self.cur_c.isdigit():
n += self.cur_c
self.consume()
return (INT, int(n))
def _print(self):
n = self.input[self.idx - 1 : self.idx + 4]
if n == 'print':
self.idx += 4
self.cur_c = self.input[self.idx]
return (PRINT, n)
return None
def _string(self):
quotes_type = self.cur_c
self.consume()
s = ''
while self.cur_c != '\n' and self.cur_c != quotes_type:
s += self.cur_c
self.consume()
if self.cur_c != quotes_type:
raise Exception('string quotes is not matched. excepted %s' % quotes_type)
self.consume()
return (STR, s)
def consume(self):
if self.idx >= len(self.input):
self.cur_c = EOF
return
self.cur_c = self.input[self.idx]
self.idx += 1
if __name__ == '__main__':
exp = '''''
veca = [1, 2, 3]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
'''
lex = Veclexer(exp)
t = lex.next_token()
while t[0] != EOF:
print t
t = lex.next_token()
运行这个程序,可以得到源代码:
veca = [1, 2, 3] print 'veca:', veca print 'veca * 2:', veca * 2 print 'veca + 2:', veca + 2
对应的token序列:
('ID', 'veca')
('EQUAL', '=')
('LBRACK', '[')
('INT', 1)
('COMMA', ',')
('INT', 2)
('COMMA', ',')
('INT', 3)
('RBRACK', ']')
('print', 'print')
('STR', 'veca:')
('COMMA', ',')
('ID', 'veca')
('print', 'print')
('STR', 'veca * 2:')
('COMMA', ',')
('ID', 'veca')
('TIMES', '*')
('INT', 2)
('print', 'print')
('STR', 'veca + 2:')
('COMMA', ',')
('ID', 'veca')
('ADD', '+')
('INT', 2)
接下来看一下语法解析器的实现。语法解析器的的输入是token流,根据一个向前看词法单元预测匹配的规则。对于每个遇到的非终结符调用对应的解析函数,而终结符(token)则match掉,如果不匹配则表示有语法错误。由于都是使用的LL(1),所以和词法解析器类似, 这里不再赘述。
'''''
A simple parser of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
example:
veca = [1, 2, 3]
vecb = veca + 4 # vecb: [1, 2, 3, 4]
vecc = veca * 3 # vecc:
Created on 2012-9-26
@author: bjzllou
'''
import veclexer
class Vecparser:
'''''
LL(1) parser.
'''
def __init__(self, lexer):
self.lexer = lexer
# lookahead token. Based on the lookahead token to choose the parse option.
self.cur_token = lexer.next_token()
# similar to symbol table, here it's only used to store variables' value
self.symtab = {}
def statlist(self):
while self.lexer.has_next():
self.stat()
def stat(self):
token_type, token_val = self.cur_token
# Asignment
if token_type == veclexer.ID:
self.consume()
# For the terminal token, it only needs to match and consume.
# If it's not matched, it means that is a syntax error.
self.match(veclexer.EQUAL)
# Store the value to symbol table.
self.symtab[token_val] = self.expr()
# print statement
elif token_type == veclexer.PRINT:
self.consume()
v = str(self.expr())
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v += ' ' + str(self.expr())
print v
else:
raise Exception('not support token %s', token_type)
def expr(self):
token_type, token_val = self.cur_token
if token_type == veclexer.STR:
self.consume()
return token_val
else:
v = self.multipart()
while self.cur_token[0] == veclexer.ADD:
self.consume()
v1 = self.multipart()
if type(v1) == int:
v.append(v1)
elif type(v1) == list:
v = v + v1
return v
def multipart(self):
v = self.primary()
while self.cur_token[0] == veclexer.TIMES:
self.consume()
v1 = self.primary()
if type(v1) == int:
v = [x*v1 for x in v]
elif type(v1) == list:
v = [x*y for x in v for y in v1]
return v
def primary(self):
token_type = self.cur_token[0]
token_val = self.cur_token[1]
# int
if token_type == veclexer.INT:
self.consume()
return token_val
# variables reference
elif token_type == veclexer.ID:
self.consume()
if token_val in self.symtab:
return self.symtab[token_val]
else:
raise Exception('undefined variable %s' % token_val)
# parse list
elif token_type == veclexer.LBRACK:
self.match(veclexer.LBRACK)
v = [self.expr()]
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v.append(self.expr())
self.match(veclexer.RBRACK)
return v
def consume(self):
self.cur_token = self.lexer.next_token()
def match(self, token_type):
if self.cur_token[0] == token_type:
self.consume()
return True
raise Exception('expecting %s; found %s' % (token_type, self.cur_token[0]))
if __name__ == '__main__':
prog = '''''
veca = [1, 2, 3]
vecb = [4, 5, 6]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
print 'veca + vecb:', veca + vecb
print 'veca + [11, 12]:', veca + [11, 12]
print 'veca * vecb:', veca * vecb
print 'veca:', veca
print 'vecb:', vecb
'''
lex = veclexer.Veclexer(prog)
parser = Vecparser(lex)
parser.statlist()
运行代码便会得到之前介绍中的输出内容。这个解释器极其简陋,只实现了基本的表达式操作,所以不需要构建语法树。如果要为列表语言添加控制结构,就必须实现语法树,在语法树的基础上去解释执行。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Is there any mobile app that can convert XML into PDF?
Apr 02, 2025 pm 08:54 PM
Is there any mobile app that can convert XML into PDF?
Apr 02, 2025 pm 08:54 PM
An application that converts XML directly to PDF cannot be found because they are two fundamentally different formats. XML is used to store data, while PDF is used to display documents. To complete the transformation, you can use programming languages and libraries such as Python and ReportLab to parse XML data and generate PDF documents.
 How to control the size of XML converted to images?
Apr 02, 2025 pm 07:24 PM
How to control the size of XML converted to images?
Apr 02, 2025 pm 07:24 PM
To generate images through XML, you need to use graph libraries (such as Pillow and JFreeChart) as bridges to generate images based on metadata (size, color) in XML. The key to controlling the size of the image is to adjust the values of the <width> and <height> tags in XML. However, in practical applications, the complexity of XML structure, the fineness of graph drawing, the speed of image generation and memory consumption, and the selection of image formats all have an impact on the generated image size. Therefore, it is necessary to have a deep understanding of XML structure, proficient in the graphics library, and consider factors such as optimization algorithms and image format selection.
 Is the conversion speed fast when converting XML to PDF on mobile phone?
Apr 02, 2025 pm 10:09 PM
Is the conversion speed fast when converting XML to PDF on mobile phone?
Apr 02, 2025 pm 10:09 PM
The speed of mobile XML to PDF depends on the following factors: the complexity of XML structure. Mobile hardware configuration conversion method (library, algorithm) code quality optimization methods (select efficient libraries, optimize algorithms, cache data, and utilize multi-threading). Overall, there is no absolute answer and it needs to be optimized according to the specific situation.
 Is there a mobile app that can convert XML into PDF?
Apr 02, 2025 pm 09:45 PM
Is there a mobile app that can convert XML into PDF?
Apr 02, 2025 pm 09:45 PM
There is no APP that can convert all XML files into PDFs because the XML structure is flexible and diverse. The core of XML to PDF is to convert the data structure into a page layout, which requires parsing XML and generating PDF. Common methods include parsing XML using Python libraries such as ElementTree and generating PDFs using ReportLab library. For complex XML, it may be necessary to use XSLT transformation structures. When optimizing performance, consider using multithreaded or multiprocesses and select the appropriate library.
 How to convert XML files to PDF on your phone?
Apr 02, 2025 pm 10:12 PM
How to convert XML files to PDF on your phone?
Apr 02, 2025 pm 10:12 PM
It is impossible to complete XML to PDF conversion directly on your phone with a single application. It is necessary to use cloud services, which can be achieved through two steps: 1. Convert XML to PDF in the cloud, 2. Access or download the converted PDF file on the mobile phone.
 How to modify node content in XML
Apr 02, 2025 pm 07:21 PM
How to modify node content in XML
Apr 02, 2025 pm 07:21 PM
XML node content modification skills: 1. Use the ElementTree module to locate nodes (findall(), find()); 2. Modify text attributes; 3. Use XPath expressions to accurately locate them; 4. Consider encoding, namespace and exception handling; 5. Pay attention to performance optimization (avoid repeated traversals)
 What is the process of converting XML into images?
Apr 02, 2025 pm 08:24 PM
What is the process of converting XML into images?
Apr 02, 2025 pm 08:24 PM
To convert XML images, you need to determine the XML data structure first, then select a suitable graphical library (such as Python's matplotlib) and method, select a visualization strategy based on the data structure, consider the data volume and image format, perform batch processing or use efficient libraries, and finally save it as PNG, JPEG, or SVG according to the needs.
 How to convert xml format to html
Apr 02, 2025 pm 08:57 PM
How to convert xml format to html
Apr 02, 2025 pm 08:57 PM
The correct way to convert XML to HTML is to extract XML structure data into a tree structure using a parser. Building an HTML structure based on the extracted data. Avoid inefficient and error-prone string operations.
