

Python toolkit for formatting and cleaning data

The world is messy, and so is the data from the real world. A recent survey report shows that 60% of data scientists’ time is spent organizing data. Unfortunately, 57% of people think this is the most troublesome part of their job.
Organizing data is very time-consuming, but many tools have been developed to make this crucial step slightly more bearable. The Python community provides many libraries to make data organized—from formatting DataFrames to anonymizing datasets.
Tell us which libraries you find useful - we're always working on optimizing the libraries that go into Mode Python Notebooks.

Dora
Dora is designed for exploratory analysis. Especially the most painful parts of automated analysis - like feature selection and extraction, visualization, and you guessed it - data cleaning. Functions related to data cleaning can:
Read data tables containing missing data and unstandardized data
Assign values to missing data
Standardized variables
Developer: Nathan Epstein
More information: https://github.com/ NathanEpstein/Dora
datacleaner
As the name suggests, datacleaner cleans your data - but only if your data is a pandas DataFrame instance. Developer Randy Olson said: "Datacleaner is not magic. It cannot magically parse your unstructured data."
It can delete rows containing missing data, or use the mode or median of the column to fill in missing data, replacing non-structured data. Numeric variables are converted into numeric variables. This library is very new, but considering that DataFrame is the basic data structure for Python data analysis, it is worth giving it a try.
Developer: Randy Olson
More information: https://github.com/rhiever/datacleaner
PrettyPandas
DataFrames are powerful, but they can’t make tables you can show directly to your boss. PrettyPandas uses the pandas style API to convert DataFrame into a presentation-ready table. Generate data summaries, set styles, and adjust data formats, columns, and rows. Bonus: Robust, highly readable usage documentation.
Developer: Henry Hammond
More information: https://github.com/HHammond/PrettyPandas
tabulate
tabulate allows you to generate small and attractive tables with just one function call. Great for making tables more readable by adjusting decimal column alignment, data formatting, table headers and more.
It has a super cool function that allows the table to be output into different formats: HTML, PHP or Markdown Extra, so that you can use other tools or languages to continue to use the data you have tabulated.
Developer: Sergey Astanin
More information: https://pypi.python.org/pypi/tabulate
scrubadub
Data scientists in the health and financial fields often need to anonymize data sets. Scrubadub can remove private information (PII) from text. For example:
Name (noun)
Email address
Internet link
Phone number
Username/password set
Skype username
Social Security Number
The document does a good job of demonstrating the ways you can Customize scrubadub's behavior, such as defining new PII or retaining specific PII.
Developer: Datascope Analytics
More information: http://scrubadub.readthedocs.io/en/stable/index.html
Arrow
Let’s be honest: dealing with dates and times in Python is a pain . The local time zone is not recognized automatically. It takes several uncomfortable lines of code to convert time zones and timestamps.
Arrow aims to solve this problem and fill this functional gap, so that you can complete date and time operations with less code and imported libraries. Unlike Python's standard time library, Arrow automatically recognizes time zones and UTC by default. You can perform time zone conversion or parse time strings with just one line of code.
Developer: Chris Smith
More information: http://arrow.readthedocs.io/en/latest/
Beautifier
Beautifier’s mission is simple: clean URLs and email addresses and make them look prettier. You can parse email by domain name and username; parse URL by domain name and parameters. (UTM or tag)
Developer: Sachin Philip Mathew
More information: https://github.com/sachinvettithanam/beautifier
ftfy
ftfy (fixes text for you) takes in bad Unicode outputs good Unicode. Basically , it fixes all the junk characters. “quotesâ€x9d becomes "quotes"; ü becomes ü;
ftfy (fixes text for you) converts messy Unicode into recognizable Unicode. Simply put, it handles all garbage characters. “quotesâ€x9d becomes "quotes"; ü becomes ü;
Developer: Luminoso
More information: https://github.com/LuminosoInsight/python-ftfy

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to format c drive with dos command
Feb 19, 2024 pm 04:23 PM
How to format c drive with dos command
Feb 19, 2024 pm 04:23 PM
DOS command is a command line tool used in Windows operating system, which can be used to perform various system management tasks and operations. One of the common tasks is to format the hard drive, including the C drive. Formatting the C drive is a relatively dangerous operation because it will erase all data on the C drive and reinitialize the file system. Before performing this operation, make sure you have backed up important files and have a clear understanding of the impact that formatting will have on your computer. The following is formatted in the DOS command line
 Why can't the D drive be formatted?
Aug 30, 2023 pm 02:39 PM
Why can't the D drive be formatted?
Aug 30, 2023 pm 02:39 PM
The reasons why the D drive cannot be formatted include that the drive is being used by other programs or processes, there is a damaged file system on the drive, hard disk failure and permission issues. Detailed introduction: 1. The reason why the D drive cannot be formatted may be because the drive is being used by other programs or processes. In the Windows operating system, if a program is accessing the files or folders on the D drive, the system will not be able to perform the format operation. ;2. The reason why the D drive cannot be formatted may be because there is a damaged file system on the drive. The file system is used by the operating system to organize and manage files and folders on the storage device, etc.
 What is disc formatting
Aug 17, 2023 pm 04:02 PM
What is disc formatting
Aug 17, 2023 pm 04:02 PM
Disc formatting refers to the process of rebuilding and clearing the disc's file system. During the disc formatting process, all data will be completely deleted, and the file system will be re-established to re-store data on the disc. Disc formatting can be used to protect data security, repair disc failures, and remove viruses. When formatting a disc, you need to back up important data, select an appropriate file system, and wait patiently for the formatting to complete.
 Methods to improve Java time and date formatting parsing performance
Jul 01, 2023 am 08:07 AM
Methods to improve Java time and date formatting parsing performance
Jul 01, 2023 am 08:07 AM
How to optimize the performance of time and date formatting and parsing in Java development Summary: In Java development, time and date formatting and parsing are common operations. However, due to the complexity and variety of time and date formats and the huge amount of data processed, it often becomes a performance bottleneck. This article will introduce several methods to optimize the performance of time and date formatting parsing in Java development, including using cache, reducing object creation, selecting appropriate APIs, etc. 1. Introduction Time and date formatting and parsing are very common in Java development. However, in practical applications, since
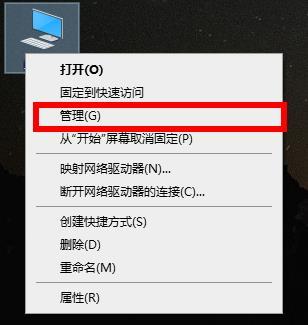 Computer formatting tutorial
Jan 08, 2024 am 08:21 AM
Computer formatting tutorial
Jan 08, 2024 am 08:21 AM
Many times when using a computer, you will encounter too much garbage, but many users still don’t know how to format the computer. It doesn’t matter. Here is a tutorial on computer formatting for you to take a look at. How to format a computer: 1. Right-click "This PC" on the desktop and click "Manage". 2. Click "Storage" in "Computer Management" to open "Disk Management". 3. Select the hard drive you want to clean, right-click and select "Format". 4. Check "Perform Quick Format" and click "OK" to start formatting.
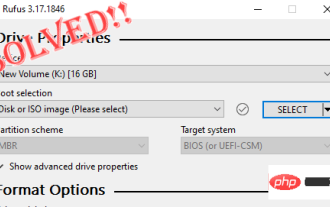 Fix: Rufus cannot create bootable USB issue in Windows PC
Apr 29, 2023 am 09:19 AM
Fix: Rufus cannot create bootable USB issue in Windows PC
Apr 29, 2023 am 09:19 AM
Rufus is an excellent tool for easily creating bootable USB drives. This small and stylish tool is amazingly efficient and generally provides error-free operation. However, sometimes creating a new bootable USB stick can cause some error messages to pop up, stumbling upon the burning process. If you face any difficulty using Rufus, you can follow the steps below to find a quick solution to your problem. Fix 1 – Run the drive’s Error Checker Before trying again with Rufus, you can run the drive’s Error Checker tool to scan the drive for any errors. 1. Press Windows key + E key at the same time to open File Explorer. Then, click "This PC
 Revealed secrets of cell phone format recovery methods (mobile phone malfunction? Don't worry)
May 04, 2024 pm 06:01 PM
Revealed secrets of cell phone format recovery methods (mobile phone malfunction? Don't worry)
May 04, 2024 pm 06:01 PM
Nowadays, we will inevitably encounter some problems such as being unable to turn on the phone or lagging, such as system crash, but during use, mobile phones have become an indispensable part of our lives. We are often at a loss, and sometimes, there are no solutions to these problems. To help you solve cell phone problems, this article will introduce you to some methods of cell phone format recovery and restore your phone to normal operation. Back up data - protect important information, such as photos and contacts, from being lost during the formatting process. Before formatting your phone, the first thing to consider is to back up important data and files on your phone. To ensure data security, or choose to transfer files to a cloud storage service, you can back it up by connecting to a computer. Use the system's built-in recovery function - simple
 Will formatting a laptop make it faster?
Feb 12, 2024 pm 11:54 PM
Will formatting a laptop make it faster?
Feb 12, 2024 pm 11:54 PM
Will formatting a laptop make it faster? If you want to format your Windows laptop but want to know if it will make it faster, this article will help you know the right answer to this question. Will formatting a laptop make it faster? There are many reasons why users format their Windows laptops. But the most common reason is slow performance or speed of your laptop. Formatting a laptop will completely delete all data stored on the C drive or the hard drive partition where Windows operating system is installed. Therefore, every user will think twice before taking this step, especially when it comes to the performance of the laptop. This article will help you understand whether formatting your laptop will speed it up. Formatting your laptop helps
