

Apache Commons Configuration reads xml configuration

Recent project is to write a string connection pool by hand. Because the environments are different, there are development versions, test versions, and online versions, and the database used by each version is also different. Therefore, it is necessary to flexibly switch database connections. Of course this can be solved using maven. The Apache Commons Configuration framework is mainly used to parse database connection strings.
The following introduces the common parts of the Apache Commons Configuration framework.
1) Apache Commons Configuration framework uses
**
# to download the jar package http://www.php.cn/ or http: //www.php.cn/ Search and download
in maven to study the use of api.
Benefits of use
·When the xml structure changes greatly, there is no need to modify the code for parsing xml too much
Users only need to modify their own parsing syntax tree.
Customers only need to modify the syntax tree framework for parsing. The starting point for thinking is whether it is similar to the interpreter pattern in the design pattern. Build abstract syntax trees and interpret execution.
Users only need to care about and modify their own parsing syntax tree.
Users do not need to worry about how to parse, they only need to configure the corresponding parsing grammar rules.
-
Simplify the program and significantly modify the code after the xml configuration structure changes.
First configure Maven.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
Define a springok1.xml with the following content 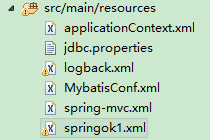
1 2 3 4 5 6 7 |
|
The parsing code begins
1 2 3 4 5 6 7 |
|
The output is as follows: It means that the xml has been successfully parsed.
127.0.0.1
3306
admin
Acquisition methods There are many more detailed acquisition methods that can be found in the AbstractConfiguration method.
The above configuration is the connection information of one database. If the connection information of many databases is configured, how to parse and switch the connection information. Modify the information of springok1.xml to configure multiple connections as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
Now assume that we want to obtain two configuration database connection information, the program is as follows:
1 2 3 4 5 6 7 8 9 10 11 |
|
Output:
127.0. 0.1
3306
admin
127.0.0.1
3302
admin
admin
Parsing is ok,
Combined with the previous configuration file example In actual combat, we found that if there are multiple identical tags, the index starts from 0.
XPath expression uses the
point access method. The above method is no problem. For some complex configurations, we may need to use the XPath expression language. The main advantage here is that, using XML's advanced queries, the program still looks relatively simple and easy to understand. High understandability. 
Or parse the springok.xml file above. The code is as follows:
1 2 3 4 |
|
Output:
127.0.0.1
3302
Test ok.
Access environment variables
1 2 |
|
How to implement source code analysis:
1 2 3 |
|
Joint configuration
Combining two methods, 1 and 2, can we define a database string key that needs to be connected in the system variable, and obtain dynamic loading during parsing? ?
1 2 3 4 5 6 7 8 9 |
|
The test is ok, no problem.
Unified management modularity
xml configuration is as shown below:
public String getDbUrl()throws ConfigurationException {
DefaultConfigurationBuilder builder =
new DefaultConfigurationBuilder(“config.xml”);
boolean load =true;
CombinedConfiguration config = builder.getConfiguration(load);
config.setExpressionEngine(new XPathExpressionEngine());
String env = config.getString("ENV_TYPE");
if(“dev”.equals(env) ||”production”.equals(env)) {
String xpath =”databases/database[name = ‘”+ env +”’]/url”;
Return config.getString(xpath);
}else{
String msg =”ENV_TYPE environment variable is “+
“not properly set”;
Throw new IllegalStateException(msg);
}
}
Automatic reload
Automatically load when the file-based configuration changes, because we can set the loading strategy. The framework polls the configuration file, and when the file's contents change, the configuration object is refreshed. You can use program control:
1 2 3 4 |
|
or control during configuration:
1 2 3 4 5 |
|
下面是dom和sax方式的手动解析方式可参考使用。
java语言中xml解析有很多种方式,最流行的方式有sax和dom两种。
1. dom是把所有的解析内容一次性加入内存所以xml内容大的话性能不好。
2. sax是驱动解析。所以内存不会占用太多。(spring用的就是sax解析方式)
需要什么包自己到网上找下吧?
xml文件如下:
1 2 3 4 5 6 7 8 9 10 11 |
|
1)DOM(JAXP Crimson解析器)
1 |
|
1 2 3 4 5 6 7 |
|
2)SAX
1 2 3 4 5 6 7 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
**
总结:个人喜欢这个框架,支持定时刷新、xpath、import方式。
近期项目自己手写一个字符串连接池。因为环境不同有开发版本、测试版本、上线版本、每一个版本用到的数据库也是不一样的。所以需要能灵活的切换数据库连接。当然这个用maven就解决了。Apache Commons Configuration 框架用的主要是解析数据库连接字符串。
下面介绍Apache Commons Configuration 框架的常用部分。
1)Apache Commons Configuration framework框架使用
**
下载jar包http://www.php.cn/或者http://www.php.cn/ maven中搜索下载
研究api的使用。
使用好处
·当xml结构大变化的时候不用过多的修改解析xml的代码
用户只需要修改自己的解析语法树即可。
客户只需要修改语法树框架去解析,思考的起点是不是跟设计模式中的解释器模式类似。构建抽象语法树并解释执行。
用户只需要关心和修改自己的解析语法树即可。
用户不用关系如何解析只需要配置对应的解析语法规则即可。
简化程序xml配置结构变化后大幅度的修改代码。
首先先配置一下Maven。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
定义一个springok1.xml内容如下
1 2 3 4 5 6 7 |
|
解析代码开始了
1 2 3 4 5 6 7 |
|
输出如下:说明已经成功解析xml了。
127.0.0.1
3306
admin
获取的方法有很多种更详细的获取方法可以从AbstractConfiguration方法中对应找到。
上面配置的是一个数据库的连接信息,如果配置很多数据库的连接信息,怎么解析连接信息切换呢。修改springok1.xml的信息为多个连接配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
现在假设我们要获取两个的配置数据库连接信息,程序如下:
1 2 3 4 5 6 7 8 9 10 11 |
|
输出:
127.0.0.1
3306
admin
127.0.0.1
3302
admin
admin
解析ok,
结合前面的配置文件的例子跟实战我们发现多个相同的标签的话索引是从0开始的。
XPath表达式使用
点的访问方式上面的那种方式是没问题,对于一些复杂的配置来讲,我们可能需要使用XPath表达式语言。这里的主要优点是,使用了XML的高级查询,程序看起来仍然比较简洁易懂。可理解性高。
还是解析上面的springok.xml文件。代码如下:
1 2 3 4 |
|
输出:
127.0.0.1
3302
测试ok.
访问环境变量
1 2 |
|
源码分析如何实现:
1 2 3 |
|
联合配置
联合一和2两种方式,是不是我们可以再系统变量中定义一个需要连接的数据库字符串key,解析的时候获取动态加载呢?
1 2 3 4 5 6 7 8 9 |
|
测试ok没问题。
统一管理模块化
xml配置如下图:
public String getDbUrl()throws ConfigurationException {
DefaultConfigurationBuilder builder =
new DefaultConfigurationBuilder(“config.xml”);
boolean load =true;
CombinedConfiguration config = builder.getConfiguration(load);
config.setExpressionEngine(new XPathExpressionEngine());
String env = config.getString(“ENV_TYPE”);
if(“dev”.equals(env) ||”production”.equals(env)) {
String xpath =”databases/database[name = ‘”+ env +”’]/url”;
return config.getString(xpath);
}else{
String msg =”ENV_TYPE environment variable is “+
“not properly set”;
throw new IllegalStateException(msg);
}
}
自动重新加载
当基于文件的配置变化的时候自动加载,因为我们可以设置加载策略。框架会轮询配置文件,当文件的内容发生改变时,配置对象也会刷新。你可以用程序控制:
1 2 3 4 |
|
或者配置的时候控制:
1 2 3 4 5 |
|
下面是dom和sax方式的手动解析方式可参考使用。
java语言中xml解析有很多种方式,最流行的方式有sax和dom两种。
1. dom是把所有的解析内容一次性加入内存所以xml内容大的话性能不好。
2. sax是驱动解析。所以内存不会占用太多。(spring用的就是sax解析方式)
需要什么包自己到网上找下吧?
xml文件如下:
1 2 3 4 5 6 7 8 9 10 11 |
|
1)DOM(JAXP Crimson解析器)
1 |
|
1 2 3 4 5 6 7 |
|
2)SAX
1 2 3 4 5 6 7 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
**
总结:个人喜欢这个框架,支持定时刷新、xpath、import方式。
以上就是Apache Commons Configuration读取xml配置的内容,更多相关内容请关注PHP中文网(www.php.cn)!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to set the cgi directory in apache
Apr 13, 2025 pm 01:18 PM
How to set the cgi directory in apache
Apr 13, 2025 pm 01:18 PM
To set up a CGI directory in Apache, you need to perform the following steps: Create a CGI directory such as "cgi-bin", and grant Apache write permissions. Add the "ScriptAlias" directive block in the Apache configuration file to map the CGI directory to the "/cgi-bin" URL. Restart Apache.
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
 How to start apache
Apr 13, 2025 pm 01:06 PM
How to start apache
Apr 13, 2025 pm 01:06 PM
The steps to start Apache are as follows: Install Apache (command: sudo apt-get install apache2 or download it from the official website) Start Apache (Linux: sudo systemctl start apache2; Windows: Right-click the "Apache2.4" service and select "Start") Check whether it has been started (Linux: sudo systemctl status apache2; Windows: Check the status of the "Apache2.4" service in the service manager) Enable boot automatically (optional, Linux: sudo systemctl
 What to do if the apache80 port is occupied
Apr 13, 2025 pm 01:24 PM
What to do if the apache80 port is occupied
Apr 13, 2025 pm 01:24 PM
When the Apache 80 port is occupied, the solution is as follows: find out the process that occupies the port and close it. Check the firewall settings to make sure Apache is not blocked. If the above method does not work, please reconfigure Apache to use a different port. Restart the Apache service.
 How to delete more than server names of apache
Apr 13, 2025 pm 01:09 PM
How to delete more than server names of apache
Apr 13, 2025 pm 01:09 PM
To delete an extra ServerName directive from Apache, you can take the following steps: Identify and delete the extra ServerName directive. Restart Apache to make the changes take effect. Check the configuration file to verify changes. Test the server to make sure the problem is resolved.
 How to view your apache version
Apr 13, 2025 pm 01:15 PM
How to view your apache version
Apr 13, 2025 pm 01:15 PM
There are 3 ways to view the version on the Apache server: via the command line (apachectl -v or apache2ctl -v), check the server status page (http://<server IP or domain name>/server-status), or view the Apache configuration file (ServerVersion: Apache/<version number>).
 How Debian improves Hadoop data processing speed
Apr 13, 2025 am 11:54 AM
How Debian improves Hadoop data processing speed
Apr 13, 2025 am 11:54 AM
This article discusses how to improve Hadoop data processing efficiency on Debian systems. Optimization strategies cover hardware upgrades, operating system parameter adjustments, Hadoop configuration modifications, and the use of efficient algorithms and tools. 1. Hardware resource strengthening ensures that all nodes have consistent hardware configurations, especially paying attention to CPU, memory and network equipment performance. Choosing high-performance hardware components is essential to improve overall processing speed. 2. Operating system tunes file descriptors and network connections: Modify the /etc/security/limits.conf file to increase the upper limit of file descriptors and network connections allowed to be opened at the same time by the system. JVM parameter adjustment: Adjust in hadoop-env.sh file
 How to configure zend for apache
Apr 13, 2025 pm 12:57 PM
How to configure zend for apache
Apr 13, 2025 pm 12:57 PM
How to configure Zend in Apache? The steps to configure Zend Framework in an Apache Web Server are as follows: Install Zend Framework and extract it into the Web Server directory. Create a .htaccess file. Create the Zend application directory and add the index.php file. Configure the Zend application (application.ini). Restart the Apache Web server.
