

XML programming is to perform crud operations on XML files.
So why do you need to use java or C/C++ to perform crud operations on XML?
1.XML needs to be parsed as data transfer
2.XML needs to be read as a configuration file
3.XML as a small database needs crud operations
w3C organization makes it convenient for everyone to parse XML , defines a set of specifications (API)
1.XML parsing is divided into: dom parsing and sax parsing
dom: (Document Object Model) is a way of processing XML recommended by the W3C organization
sax:(Simple API for XML), is not an official standard, but it is the de facto standard in the XML community, and almost all XML parsers support it
SAX parsing uses an event-driven model edge Parsing while reading: parse line by line from top to bottom, parse to a certain element, and call the corresponding parsing method.
DOM allocates a tree structure in memory according to the XML hierarchical structure, and encapsulates XML tags, attributes, text and other elements into tree node objects.
Different companies and organizations provide parsers for both DOM and SAX:
Sun's JAXP
Dom4j organized dom4j (most commonly used, such as hibernate)
JDom organized jdom
The JASP is part of J2SE, which are DOM and SAX parsers are provided for DOM and SAX.
Here we mainly introduce three kinds of parsing: dom, sax and dom4j
Sun company provides Java API for XML Parsing (JAXP) interface to use SAX and DOM. Through JAXP, we can use any JAXP-compatible XML parser.
The JAXP development package is part of J2SE, which consists of javax.xml, org.w3c.dom, org.xml.sax packages and their sub-packages
In the javax.xml.parsers package , several factory classes are defined. When programmers call these factory classes, they can get the DOM or SAX parser object that parses the xml document.
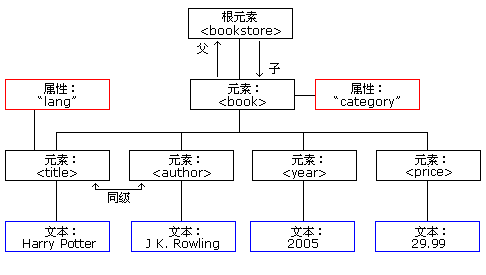
First explain the DOM object of JAXP parsing XML The principle of XML DOM is that the XML document is regarded as a node-tree, and all nodes in the tree are related to each other. All nodes can be accessed through this tree. Their contents can be modified or deleted, and new elements can be created.
For example, the current XML document is as follows (this example comes from w3cschool online tutorial):
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>This tree starts from the root node and grows branches to the text node at the lowest level of the tree:
[Several knowledge points to know]:
1.dom will regard the xml file as a tree and load it into the memory
2.dom Particularly suitable for crud operations
3.dom is not suitable for operating larger xml files (occupying memory)
4.dom will map every element, attribute, and text in the xml file to the corresponding Node object .
1. Call the DocumentBuilderFactory.newInstance() method to get the factory that creates the DOM parser
2. Call The newDocumentBuilder method of the factory object obtains the DOM parser object
3. Call the parse() method of the DOM parser object to parse the XML document and obtain the Document object representing the entire document. The entire XML document can be operated using DOM features.
The XML document is as follows:
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>First use the three steps introduced in 2.2 to get the document object representing the entire document, and call the read(Document document) method we wrote, as follows:
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);The read method is written like this:
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }The final running result is as follows:

Using DOM to update XML documents must use the Transformer class to write changes to the file, otherwise it will just change the XML document object in memory.
The Transformer class in the javax.xml.transform package is used to convert the Document object representing the XML file into a certain format for output. For example, apply a style sheet to the xml file and convert it into An html document. Using this object, of course, you can also write the Document object back to an XML file.
The Transformer class completes the conversion operation through the transform method, which receives a source and a destination. We can associate the document object to be converted through:
javax.xml.transform.dom.DOMSource class
Use javax.xml.transform.stream.StreamResult object to represent the destination of data
Transformer object is obtained through TransformerFactory
【1】Add element
We can add a student child node to the above XML, as follows:
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
}XML编程,就是对XML文件进行crud操作。
那么为什么要用java或者C/C++对XML进行crud操作呢?
1.XML作为数据传递需要解析
2.XML作为配置文件需要读取
3.XML作为小型数据库,需要进行crud操作
w3C组织为了大家解析XML方便,定义了一套规范(API)
1.XML解析分为:dom解析和sax解析
dom:(Document Object Model,即文档对象模型),是W3C组织推荐的处理XML的一种方式
sax:(Simple API for XML),不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它
SAX解析采用事件驱动模型边读边解析:从上到下一行一行解析,解析到某一元素,调用相应的解析方法。
DOM根据XML层级结构在内存中分配一个树形结构,把XML的标签,属性和文本等元素都封装成树的节点对象。
不同的公司和组织提供了针对DOM和SAX两种方式的解析器:
Sun的JAXP
Dom4j组织的dom4j(最常用,例如hibernate)
JDom组织的jdom
其中的JASP是J2SE的一部分,它分别针对DOM和SAX提供了DOM和SAX解析器。
在这里也主要介绍三种解析:dom、sax和dom4j
Sun公司提供了Java API for XML Parsing(JAXP)接口来使用SAX和DOM,通过JAXP,我们可以使用任何与JAXP兼容的XML解析器。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的DOM或SAX的解析器对象。
首先说明JAXP解析XML的DOM对象的原理,XML DOM把XML文档视为一颗节点树(node-tree),树中的所有节点彼此之间都有关系。可通过这棵树访问所有的节点。可以修改或者删除它们的内容,也可以创建新的元素。
比如,现在的XML文档如下(该例子来自w3cschool在线教程):
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>这棵树从根节点开始,在树的最低层级向文本节点长出枝条:
【要知道的几个知识点】:
1.dom会把xml文件看做一棵树,并加载到内存
2.dom特别适合做crud操作
3.dom不太适合去操作比较大的xml文件(占用内存)
4.dom会把xml文件中每一个元素、属性、文本都映射成对应的Node对象。
1.调用DocumentBuilderFactory.newInstance()方法得到创建DOM解析器的工厂
2.调用工厂对象的newDocumentBuilder方法得到DOM解析器对象
3.调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进行可以利用DOM特性对整个XML文档进行操作了。
XML文档如下:
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>首先使用2.2中介绍了三个步骤得到代表整个文档的document对象,并调用我们所写的read(Document document)方法,如下:
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);其中的read方法是这么写的:
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }最后的XML—DOM for XML parsing如下所示:
利用DOM更新XML文档一定要使用Transformer类将更改写入文件,否则只是更改了在内存中的XML文档对象。
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写回到一个XML文件中
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地
Transformer对象通过TransformerFactory获得
【1】添加元素
我们可以向上述XML中添加一个学生子节点,如下:
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
} 以上就是XML—XML解析之DOM的内容,更多相关内容请关注PHP中文网(www.php.cn)!
 How to convert pdf to xml format
How to convert pdf to xml format
 Advantages of downloading the official website of Yiou Exchange App
Advantages of downloading the official website of Yiou Exchange App
 Registration-free CDN acceleration service
Registration-free CDN acceleration service
 What are the problems with using php
What are the problems with using php
 What are the e-commerce platforms?
What are the e-commerce platforms?
 Python return value return usage
Python return value return usage
 JavaScript escape characters
JavaScript escape characters
 How to solve the problem of failure to load dll
How to solve the problem of failure to load dll
 Complement algorithm for negative numbers
Complement algorithm for negative numbers








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



