

The concept of optimization is always mentioned during the development project. This article is an exploration of Mysql data optimization practice. It briefly introduces the reasons, methods, partition table management methods and a simple practice of partitioning.
When operating big data, divide and conquer the data table, and divide a table with a large amount of data into A smaller operating unit, each operating unit will have a separate name. At the same time, for program developers, partitioning is the same as no partitioning. Generally speaking, mysql partitioning is transparent to program applications and is just a rearrangement of data by the database.
Partition function:
(1) Improve performance.
The ultimate goal of partitioning is to improve performance. After partitioning is completed, mysql generates specific data files and index files for each partition, and retrieves specific partial data during retrieval, so it is better Implement and maintain database. This is because the partitioned table is assigned to different physical drives, reducing partition physical I/O contention when accessing multiple partitions at the same time.
(2) Easy to manage.
After partitioning, the management data can directly manage the corresponding partition. The operation is simple. When the data reaches millions, directly operating the partition is far more direct than operating the data table.
(3) Fault tolerance
After the partition is completed, if one partition is destroyed, other data will not be affected.
The partitioning methods of mysql are: RANGE partition, LIST partition, HASH partition, and KEY partition.
RANGE partitioning: Partition management is performed based on the value of a certain field. It is partitioned when directly creating a table. eg:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date, salary int ) partition by range(salary) ( partition p1 values less than (1000), partition p2 values less than (2000), partition p3 values less than maxvalue );
LIST partition: similar to RANG partition, the difference is that list partition is a hash value, RANG partition It is partitioned based on a certain field range. eg:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by list(deptno) ( partition p1 values in (10,15), partition p2 values in (20,25), partition p3 values in (30,35) );
HASH partitioning: ensure that the data is evenly distributed among the partitions of pre-specified bibliographies, and the column values when partitioning are specified. and number of partitions. eg:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by hash(year(birthdate)) partitions 4;
KEY partition: similar to HASH partition, different from KEY partition which only supports calculation of one or more columns, provided by MySQL server Its own hash function must have one or more columns containing integer values. eg:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by key(birthdate) partitions 4;
Delete Partition:
##alter table emp drop partition p1;
Cannot delete hash or key partition.
Delete multiple partitions at once, alter table emp drop partition p1,p2;
Add partition:
alter table emp add partition (partition p3 values less than (4000));
alter table empl add partition ( partition p3 values in (40));
Reorganize partition:
The Reorganizepartition keyword can modify some or all partitions of the table without losing it data. The overall scope of the partition should be consistent before and after decomposition.
alter table te
reorganize partition p1 into
(
##partition p1 values less than (100) ,
partition p3 values less than (1000)
); ----No data loss
Merge Partition:
Merge Partition: Merge 2 partitions into one.
alter table te
reorganize partition p1,p3 into
(partition p1 values less than (1000));
----No data loss
Redefine hash partition table:
##Alter table emp partition by hash(salary )partitions 7;
##---- will not be lost Data
Redefine range partition table:
Alter table emp partitionbyrange(salary)
(partition p1
values less than (2000),
partition p2values less than (4000 )
); ----No data loss
Delete all partitions of the table:
Alter table emp removepartitioning;--No data loss
##Rebuild the partition:
This has the same effect as first deleting all records saved in the partition and then reinserting them. Effect. It can be used to defragment partitions.
ALTER TABLE emp rebuild partitionp1,p2;
Optimize partitioning:
If a large number of rows are deleted from the partition, or a variable with If the length of the row (that is, there are VARCHAR, BLOB, or TEXT type columns) has made many modifications, you can use "ALTER TABLE ... OPTIMIZE PARTITION" to reclaim unused space and defragment the partition data file.
ALTER TABLE emp optimize partition p1,p2;
Analysis partition:
Read and save The key distribution of the partition.
ALTER TABLE emp analyze partition p1,p2;
Patch partition:
Patch the damaged one Partition.
ALTER TABLE emp repairpartition p1,p2;
Checking Partitions:
You can check partitions in much the same way as using CHECK TABLE on a non-partitioned table.
ALTER TABLE emp CHECK partition p1,p2;
这个命令可以告诉你表emp的分区p1,p2中的数据或索引是否已经被破坏。如果发生了这种情况,使用“ALTER TABLE ... REPAIR PARTITION”来修补该分区。
1. 创建分区表和不分区表:
-- 创建分区表 CREATE TABLE part_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null) PARTITION BY RANGE(year(c3)) (PARTITION p0 VALUES LESS THAN (1995), PARTITION p1 VALUES LESS THAN (1996) , PARTITION p2 VALUES LESS THAN (1997) , PARTITION p3 VALUES LESS THAN (1998) , PARTITION p4 VALUES LESS THAN (1999) , PARTITION p5 VALUES LESS THAN (2000) , PARTITION p6 VALUES LESS THAN (2001) , PARTITION p7 VALUES LESS THAN (2002) , PARTITION p8 VALUES LESS THAN (2003) , PARTITION p9 VALUES LESS THAN (2004) , PARTITION p10 VALUES LESS THAN (2010), PARTITION p11 VALUES LESS THAN (MAXVALUE) );
-- 创建没有分区表 CREATE TABLE nopart_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null)
2. 创建大数据操作环境。为了测试结果的准确度提高,需要表中存在大数据,通过以下事务可在数据表中创建800万条数据:
-- 创建生成数据事物
CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end; 执行事务:call load_part_tab(); ,因为执行此事务执行的时间很长,我只在表中插入了283304条数据。
创建完成一张表后,可以将该表的数据复制到未分区表,这样执行速度会很快:
insert into test.nopart_tab select * from test.part_tab
3. 查看分区表分区结构:
-- 查询分区情况 select partition_name part, partition_expression expr, partition_description descr, table_rows from information_schema.partitions where table_schema = schema() and table_name='part_tab';
执行结果:
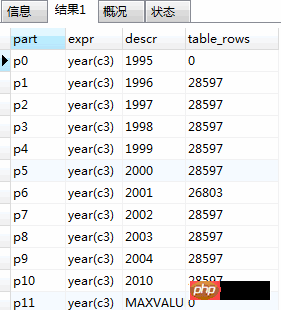
3. 测试速度:
执行分区表查询语句:
select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

执行未分区表查询语句:
select count(*) from nopart_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

从时间对比可以看出,同样的查询语句,分区表执行速度在20ms左右,未分区表在175ms左右,执行速度相差8倍左右,因此得出结论:分区表的执行速度要比未分区表执行速度快。
1. MySQL分区处理NULL值的方式
如果分区键所在列没有notnull约束。
如果是range分区表,那么null行将被保存在范围最小的分区。
如果是list分区表,那么null行将被保存到list为0的分区。
在按HASH和KEY分区的情况下,任何产生NULL值的表达式mysql都视同它的返回值为0。
为了避免这种情况的产生,建议分区键设置成NOT NULL。
2. The partition key must be of type INT, or return INT type through expression, which can be NULL. The only exception is when the partition type is KEY partitioning, you can use other types of columns as partition keys (except BLOB or TEXT columns).
3. Create an index on the partition key of the partition table, then this index will also be partitioned. There is no global index for the partition key. .
4. Only RANG and LIST partitions can be sub-partitioned, HASH and KEY partitions cannot be sub-partitioned.
5. Temporary tables cannot be partitioned.
The above is the content of Mysql optimization experiment (1)-Partition. For more related content, please pay attention to the PHP Chinese website (www.php.cn)!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



