

In-depth explanation of MySQL indexes and structures

B-tree
B-Tree is also called a balanced multi-path search tree (not binary). Using the B-tree structure can significantly reduce Locate the intermediate process experienced when recording, thereby speeding up access.
Left sub-node key value 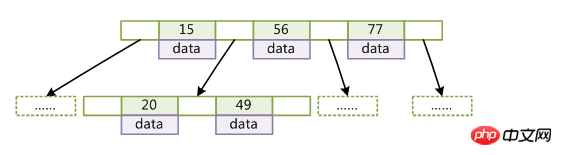
(key is the key value of the record. For different data records, the key is different from each other; data is the data in the data record except key)
B+tree
B+Tree is an improved B-tree. 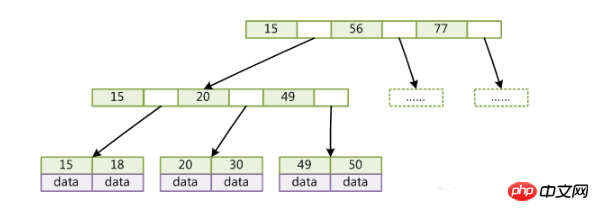
(key is the key value of the record. For different data records, the key is different from each other; data is the data in the data record except key)
Compatible with B-Tree Compared with B+Tree, there are the following differences:
The upper limit of the pointer of each node is 2d instead of 2d+1.
Internal nodes do not store data, only keys; leaf nodes do not store pointers.
Why does the database use B-tree
The mechanical disk of the computer? In order to amortize the waiting time for mechanical movement, the disk will access multiple data items at one time. Not one, such an information unit read at a time is page. We can use the number of pages read or written as the main approximation of the total disk access time. At any time, B Tree algorithms only need to keep a certain number of pages in memory. The design of B-tree takes into account disk pre-reading. A B-tree node is usually as large as a complete disk page (page), and the size of the disk page limits the children that a B-tree node can contain The number (branching factor), of course, this also depends on the size of a keyword relative to a page.
In order to minimize I/O operations, disk reads are read ahead every time, and the size is usually an integer multiple of the page. Even if only one byte needs to be read, the disk will read one page of data (usually 4K) and put it into the memory. The memory and the disk exchange data in units of pages. Because the principle of locality holds that when one piece of data is usually used, nearby data will also be used immediately. B-Tree: If a retrieval requires access to 4 nodes, the database system designer uses the principle of disk read-ahead to design the size of the node as one page, then reading one node only requires one I/O operation , to complete this retrieval operation, up to 3 I/Os are required (the root node is resident in memory).The smaller the data record, the more data is stored in each node, the smaller the height of the tree, the fewer I/O operations, and the retrieval efficiency increases.
B+Tree: Non-leaf nodes only store keys, which greatly reduces the size of non-leaf nodes. Then each node can store more records,The tree is shorter, and I/O Less operations. So B+Tree has better performance.
What is an indexTo put it bluntly, an index is a data structure. The cost of indexThe index also comes at a cost: the index file itself consumes storage space, and the index will increase the burden of inserting, deleting, and modifying records. In addition, MySQL will also Resources are consumed to maintain indexes, so more indexes are not always better. Generally, it is not recommended to build an index in two situations.The first situation is that the table records are relatively small.
The other situation where it is not recommended to build an index is that the selectivity of the index is low. The so-called index selectivity (Selectivity) refers to the ratio of unique index values (also called cardinality) to the number of table records (#T)
2. Unique index
3. Primary key index
4. Combined index
Clustered index and non-clustered index
The so-called clustered index means that the main index file and the data file are the same file. Clustered index is mainly used in the Innodb storage engine. In this index implementation, the data on the leaf nodes of B+Tree is the data itself, and the key is the primary key. As shown below: 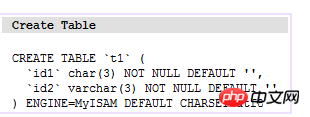
(t1 table) 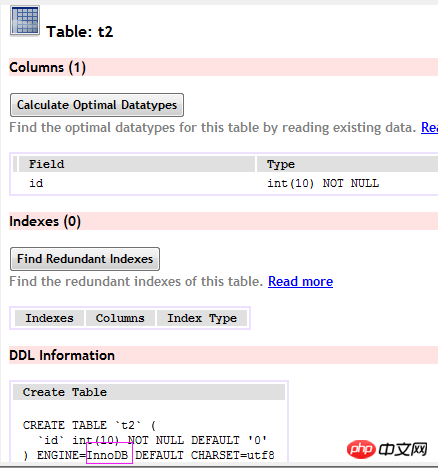
(t2 table) 
(file corresponding to the database)
Because of InnoDB The data files themselves must be aggregated by primary key, so InnoDB requires that the table must have a primary key (MyISAM may not have one). If not explicitly specified, the MySQL system will automatically select a column that can uniquely identify the data record as the primary key. If such a column does not exist , then MySQL automatically generates an implicit field as the primary key for the InnoDB table. The length of this field is 6 bytes and the type is long.
MyISAM and InnoDB data storage engines in MySQL database
Main differences:
MyISAM is non-transactionally safe, while InnoDB is transactionally safe.
The granularity of MyISAM locks is table level, while InnoDB supports row-level locking.
MyISAM supports full-text type indexes, while InnoDB does not support full-text indexes.
MyISAM is relatively simple, so it is better than InnoDB in terms of efficiency. Small applications can consider using MyISAM.
MyISAM tables are saved in the form of files. Using MyISAM storage in cross-platform data transfer will save a lot of trouble.
InnoDB tables are more secure than MyISAM tables. You can switch non-transactional tables to transactional tables (alter table tablename type=innodb) while ensuring that data will not be lost.
Application scenarios:
MyISAM manages non-transaction tables. It provides high-speed storage and retrieval, as well as full-text search capabilities. If your application needs to perform a large number of SELECT queries, MyISAM is a better choice.
InnoDB is used for transaction processing applications and has numerous features, including ACID transaction support. If your application needs to perform a large number of INSERT or UPDATE operations, you should use InnoDB, which can improve the performance of multi-user concurrent operations.
Supplement
Main memory storage
Fetch process
When the system needs to read the main memory, the address signal is put on the address bus and passed to the main memory. After the main memory reads the address signal, it parses the signal and locates the specified storage unit, and then puts the data of this storage unit on the data bus for other components to read.
The process of writing to main memory is similar. The system places the unit address and data to be written on the address bus and data bus respectively. The main memory reads the contents of the two buses and performs corresponding write operations.
It can be seen here that the time of main memory access is only linearly related to the number of accesses. Because there is no mechanical operation, the "distance" of the data accessed twice will not have any impact on the time. For example, fetch first The time consumption of fetching A0 and then A1 is the same as fetching A0 and then D3.
Disk access principle
When data needs to be read from the disk, the system will transfer the data logical address to the disk , the disk's control circuit translates the logical address into a physical address according to the addressing logic, that is, determines which track and sector the data to be read is on. In order to read the data in this sector, the magnetic head needs to be placed over this sector. In order to achieve this, the magnetic head needs to move to align with the corresponding track. This process is called seek, and the time spent is called seek time. Then the disk rotation will The target sector is rotated under the head. The time spent in this process is called rotation time.
The above is an in-depth and detailed explanation of MySQL index and structure. For more related content, please pay attention to the PHP Chinese website (www.php.cn)!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
52

 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
 How to view sql database error
Apr 10, 2025 pm 12:09 PM
How to view sql database error
Apr 10, 2025 pm 12:09 PM
The methods for viewing SQL database errors are: 1. View error messages directly; 2. Use SHOW ERRORS and SHOW WARNINGS commands; 3. Access the error log; 4. Use error codes to find the cause of the error; 5. Check the database connection and query syntax; 6. Use debugging tools.
