

This article mainly introduces the relevant information and the final solution of a slow query event caused by misjudgment of the online mysql optimizer. I share it with you, hoping to give you some inspiration.
Foreword:
I received crazy slow query and request timeout alarms, and analyzed the exceptions from mysql requests through metrics. I saw a lot of slow queries using cli —> show proceslist. This sql did not exist before, but this problem appeared later due to the increase in data volume. Although the feeds table is as large as 100 million, because the feeds flow information has the characteristics of recent hotness, the frequent IO is not caused by innodb_buffer_pool_size inefficiency. Later, after further explaining the execution plan analysis, the reason was found. The mysql query optimizer chose an index that it thought was efficient.
Mysql query optimizer is reliable in most cases! But you should pay attention when your SQL language contains multiple indexes. Often the final result is a bit hesitant. Because mysql can only use one index for the same sql, which one should I choose? When the amount of data is small, the MySQL optimizer will post the primary key index and give priority to index and unique. When you reach a data level, and because your query operation has in, the mysql query optimizer is likely to use the primary key!
Remember one sentence, mysql query optimization is based on retrieval cost considerations, not time cost considerations. The optimizer calculates the cost based on the existing data status, rather than actually executing SQL.
So, the mysql optimizer cannot achieve the optimization effect every time. It cannot accurately estimate the cost. If you want to accurately get the cost of each index, you have to actually execute it once to know. Therefore, the cost analysis is only an estimate. Since it is an estimate, there is a misjudgment.
The table we are talking about here is the feed information flow table. We know that the feeds information flow table is not only accessed frequently, but also has a large amount of data. But the data structure of this table is very simple, and the index is also simple. There are only two indexes in total, one is the primary key index, and the other is the unique key index.
As follows, the size of this table has reached the 100 million level. Because there are enough caches, and for various reasons, there is no time to divide the database into tables.
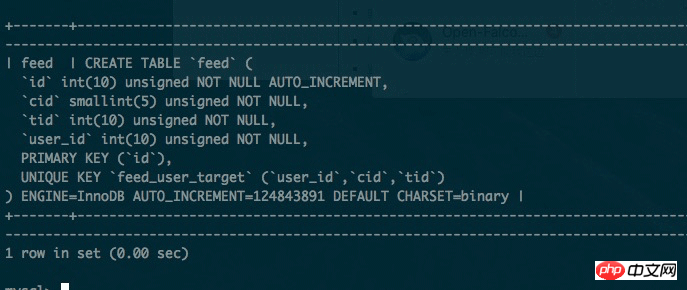
The problem is this. When the data magnitude is less than 100 million, the mysql optimizer chooses to use the index index. When the data magnitude exceeds 100 million, the mysql query The optimizer chooses to use the primary key index. The problem this brings is that the query speed is too slow.
This is under normal circumstances:
mysql> explain SELECT * FROM `feed` WHERE user_id IN (116537309,116709093,116709377)
AND cid IN (1001,1005,1054,1092,1093,1095)
AND id <= 128384713 ORDER BY id DESC LIMIT 0, 11 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: feed
partitions: NULL
type: range
possible_keys: PRIMARY,feed_user_target
key: feed_user_target
key_len: 6
ref: NULL
rows: 18
filtered: 50.00
Extra: Using where; Using index; Using filesort
1 row in set, 1 warning (0.00 sec)For the same SQL statement, after the data volume changes significantly, the mysql query optimizer will Index selection has also changed.
mysql> explain SELECT * FROM `feed` WHERE user_id IN (116537309,116709093,116709377)
AND cid IN (1001,1005,1054,1092,1093,1095)
AND id <= 128384713 ORDER BY id DESC LIMIT 0, 11 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: feed
type: range
possible_keys: PRIMARY,feed_user_target
key: PRIMARY
key_len: 4
ref: NULL
rows: 11873197
Extra: Using where
1 row in set (0.00 sec)The solution is to use force index to force the query optimizer to use the index we gave. This is a python development environment. Common python ORMs have force index, ignore index, and user index parameters.
explain SELECT * FROM `feed` force index (feed_user_target) WHERE user_id IN (116537309,116709093,116709377) ...
So how should we prevent this problem? Because of the increase in data, the mysql optimizer chooses an inefficient index?
I consulted DBAs from several factories on this issue, and the answers I got were the same as our method. The problem can only be discovered through later slow queries, and then specify force index in the SQL statement to solve the index problem. In addition, such problems will be avoided in the early stages of the system being launched, but often business developers will cooperate with the DBA's review work in the early stage, but in the later stage, in order to save trouble, or they think that there is no problem, they cause MySQL query accidents.
I know little about the index selection rules of the MySQL optimizer, and I plan to spend time studying the rules later.
The above is a sharing of a slow query event caused by a misjudgment by the online MySQL optimizer. For more related content, please pay attention to the PHP Chinese website (www.php.cn)!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



