

Detailed introduction and analysis of Java exception model (picture)

1. Introduction and basics of exceptions
The ideal time to find errors is during the compilation phase, that is, before you try to run the program. However, the compiler cannot find all errors during compilation. The remaining errors can only be discovered and resolved during runtime. This type of error is Throwable. This requires the error source to pass appropriate information to a receiver in some way, and the receiver will know how to handle the problem correctly. This is Java's Error ReportMechanism——Exception mechanism. This mechanism allows the program to separate the code of what does during normal execution from the code of what to do if something goes wrong. In terms of exception handling, Java adopts the
termination model. In this model, it will be assumed that the error is so critical that the program cannot return to the point where the exception occurred to continue execution. Once an exception is thrown, it indicates that the error is irreversible and execution cannot be continued. Compared to the termination model, another exception handling model is the recovery model , which enables the program to continue executing after the exception is handled. Although this model is attractive, it is not very practical, mainly because of the coupling it causes: the recovery handler needs to know where the exception was thrown, which necessarily contains non-generic code that depends on the throw location, thus greatly Increases the difficulty of code writing and maintenance. In an exception situation, the throwing of an exception is accompanied by the following three things:
- First of all, the same as other
- objects
in Java As with creation, new will be used to create the exception object on the heap; Secondly,
The current execution path is terminated , and the reference to the exception object is popped from the current environment ; Finally,
The exception handling mechanism takes over the program, and begins to look for the corresponding exception handler, and recovers the program from the error state. ##2. Java standard exceptions
1.
Exception class hierarchy example
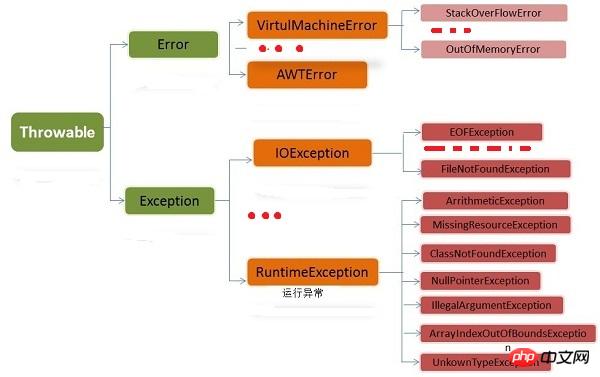 -
-
Throwable: The root class of all exception types
In Java,
Throwable is the root class of all exception types.
Exception and Error. Both are important subclasses of Java exception handling, and each contains a large number of subclasses.
- Error: An error that cannot be handled by the program itself
Error is an error that cannot be handled by the program, indicating a serious problem in running the application.
Runtime Error (Virtual MachineError), an OutOfMemoryError will occur when the JVM no longer has the memory resources required to continue executing the operation. When these exceptions occur, the Java Virtual Machine (JVM) generally chooses to terminate the thread. These errors are not checkable, and they are outside the control and processing capabilities of the application. In Java, errors are described through subclasses of Error. Exception: Error that the program itself can handle
Exception is usually of concern to Java programmers. It may be thrown in Javaclass library, user methods and runtime failures. It consists of two branches: Runtime exceptions (exceptions derived from RuntimeException) and Other exceptions. The rules for dividing these two types of exceptions are: caused by program errors (usually logical errors, such as incorrect type conversion, array out of bounds, etc., which should be avoided) The exception belongs to RuntimeException; while there is no problem with the program itself, but the exception caused by errors such as I/O (eg: trying to open a file that does not exist) belongs to other exceptions.
In addition, Java exceptions (including Exception and Error) can usually be divided into checked exceptions (checked exceptions) and Unchecked exceptions (unchecked exceptions) are two types.
-
Unchecked exceptions: all exceptions derived from Error or RuntimeException
Unchecked exceptions are exceptions that the compiler does not Exceptions that require mandatory handling include runtime exceptions (RuntimeException and its subclasses) and errors (Error). In other words, when this kind of exception may occur in the program, even if it is not caught with a try-catch statement or declared to be thrown using a throws clause, the compiler will pass.
-
Checked exceptions: All exceptions except unchecked exceptions
Checked exceptions are required by the compiler Handled exception. There are two processing methods referred to here: Catching and handling exceptions and Statement Throwing exceptions . That is to say, when such an exception may occur in the program, either use a try-catch statement to catch it, or use a throws clause to declare it to be thrown, otherwise the compilation will not pass.
Guidelines: If a RuntimeException occurs in the program, it must be the programmer's problem
The difference between exceptions and errors: Exceptions can be handled by the program itself, but errors cannot be handled
3. Java exception handling Mechanism
-
Exception handling
In Java applications, the exception handling mechanism is: Throw exception and Catch exception.
Throwing an exception: When an error occurs in a method and an exception is thrown, the method creates an exception object and delivers it to the runtime system. The exception object contains the exception type and the program status when the exception occurs, etc. Exception information. The runtime system is responsible for finding the code to handle the exception and executing it.Catch exceptions:After the method throws an exception, the runtime system will turn to find a suitable exception handler (exception handler). The potential exception handler is a collection of methods that remain in the call stack in sequence when an exception occurs. When the exception type that the exception handler can handle matches the exception type thrown by the method, it is a suitable exception handler. The runtime system starts from the method where the exception occurred, and checks back the methods in the call stack until it finds the method containing the appropriate exception handler and executes it. When the runtime system traverses the call stack without finding a suitable exception handler, the runtime system terminates. At the same time, it means the termination of the Java program.
For runtime exceptions, errors, or checked exceptions, the exception handling methods required by Java technology are different:
Since runtime exceptions are unchecked, Java stipulates that runtime exceptions will be automatically thrown by the Java runtime system, allowing applications to ignore the runtime Exception;
For Error that may occur during the execution of the method, when the running method does not want to catch it, Java allows the method to do nothing throw statement. Because most Errors are unrecoverable and are exceptions that reasonable applications should not catch;
-
Forall checked exceptions, Java stipulates that exceptions must be caught or explained. That is, when a method chooses not to catch checkable exceptions, it must declare that it will throw an exception;
Any Java code can throw exceptions, such as code written by yourself, code from the Java development environment package, or the Java runtime system. Anyone can throw an exception through Java's throw statement.
Generally speaking, Java stipulates that checkable exceptions must be caught or declared to be thrown. Allows ignoring uncheckable RuntimeException and Error.
2. Exception description
For checked exceptions, Java provides corresponding syntax that allows you to tell the client programmer the type of exception that a certain method may throw, and then the client programmer can handle it accordingly. This is the Exception description, which is part of the method declaration, immediately after the formal parameter list, as shown in the following code:
void f() throws TooBig, TooSmall, pZero { ... }represents method f possible Three exceptions, TooBig, TooSmall, and pZero, will be thrown, and
void g() { ... ... }means that method g will not throw any exceptions.
The code must be consistent with the exception description. If the code in the method generates a checked exception but does not handle it, the compiler will discover this problem and remind you: Either handle the exception, or indicate in the exception description that this method will generate an exception. However, we can declare that a method will throw an exception but not actually throw it.
3. Catching exceptions
Monitoring area:It is a piece of code that may generate exceptions, and is followed by code to handle these exceptions, by try…catch… clause Implementation.
(1) try clause
If an exception is thrown inside the method, this method will end in the process of throwing the exception. If you don't want the method to end here, you can set a special block within the method to catch the exception. Among them, in this block, the part that tries to call various methods is called the try block:
try {
// Code that might generate exceptions } (2) catch clause – exception handler
The thrown exception must be handled, And for each exception to be caught, a corresponding exception handler must be prepared. The exception handler must immediately follow the try block, represented by the catch keyword:
try {
// Code that might generate exceptions } catch(Type1 id1)|{
// Handle exceptions of Type1 } catch(Type2 id2) {
// Handle exceptions of Type2 } catch(Type3 id3) {
// Handle exceptions of Type3 } The exception handler may not use the identifier (id1, id2, ...), because the exception type itself already gives enough information to handle the exception, but the identifier is not omitted. When an exception is thrown, the exception handling mechanism will be responsible for searching for the first handler whose parameters match the exception type. Then enter the corresponding catch and execute it automatically. At this time, the exception is considered to be handled. Once the catch clause ends, the handler's lookup ends (unlike switch...case...).
Special attention should be paid to:
Exception matching principle: When an exception is thrown, exception handling The system will find the closest matching handler (an object of the derived class can match the handler of its base class) in the order in which the code is written. Once found, it assumes that the exception will be handled and stops looking;
Unmaskable derived class exceptions:Capture base class exceptions The catch clause must be placed after the catch clause that captures exceptions of its derived class, otherwise the compilation will not pass;
The catch clause must be used together with the try clause .
(3) finally clause
The finally Block Description
The finally block always executes when the try block exits. This ensures that the finally block is executed even if an unexpected exception occurs. But finally is useful for more than just exception handling — it allows the programmer to avoid having cleanup code accidentally bypassed by a return,continue, or break. Putting cleanup code in a finally block is always a good practice, even when no exceptions are anticipated.
Note: If the JVM exits while the try or catch code is being executed, then the finally block may not execute. Likewise, if the thread executing the try or catch code is interrupted or killed, the finally block may not execute even though the application as a whole continues.
finally 子句 总会被执行(前提:对应的 try子句 执行)
下面代码就没有执行 finally 子句:
public class Test {
public static void main(String[] args) {
System.out.println("return value of test(): " + test());
}
public static int test() {
int i = 1;
System.out.println("the previous statement of try block");
i = i / 0;
try {
System.out.println("try block");
return i;
}finally {
System.out.println("finally block");
}
}
}/* Output:
the previous statement of try block
Exception in thread "main" java.lang.ArithmeticException: / by zero
at com.bj.charlie.Test.test(Test.java:15)
at com.bj.charlie.Test.main(Test.java:6)
*///:~当代码抛出一个异常时,就会终止方法中剩余代码的执行,同时退出该方法的执行。如果该方法获得了一些本地资源,并且这些资源(eg:已经打开的文件或者网络连接等)在退出方法之前必须被回收,那么就会产生资源回收问题。这时,就会用到finally子句,示例如下:
InputStream in = new FileInputStream(...);try{
...
}catch (IOException e){
...
}finally{
in.close();
}finally 子句与控制转移语句的执行顺序
A finally clause can also be used to clean up for break, continue and return, which is one reason you will sometimes see a try clause with no catch clauses. When any control transfer statement is executed, all relevant finally clauses are executed. There is no way to leave a try block without executing its finally clause.
先看四段代码:
// 代码片段1
public class Test {
public static void main(String[] args) {
try {
System.out.println("try block");
return ;
} finally {
System.out.println("finally block");
}
}
}/* Output:
try block
finally block
*///:~// 代码片段2public class Test {
public static void main(String[] args) {
System.out.println("reture value of test() : " + test());
}
public static int test(){
int i = 1;
try {
System.out.println("try block");
i = 1 / 0;
return 1;
}catch (Exception e){
System.out.println("exception block");
return 2;
}finally {
System.out.println("finally block");
}
}
}/* Output:
try block
exception block
finally block
reture value of test() : 2
*///:~// 代码片段3public class ExceptionSilencer {
public static void main(String[] args) {
try {
throw new RuntimeException();
} finally {
// Using ‘return’ inside the finally block
// will silence any thrown exception.
return;
}
}
} ///:~// 代码片段4class VeryImportantException extends Exception {
public String toString() {return "A very important exception!"; }
}
class HoHumException extends Exception {
public String toString() {
return "A trivial exception";
}
}
public class LostMessage {
void f() throws VeryImportantException {
throw new VeryImportantException();
}
void dispose() throws HoHumException {
throw new HoHumException();
}
public static void main(String[] args) {
try {
LostMessage lm = new LostMessage();
try {
lm.f();
} finally {
lm.dispose();
}
} catch(Exception e) {
System.out.println(e);
}
}
} /* Output:
A trivial exception
*///:~从上面的四个代码片段,我们可以看出,finally子句 是在 try 或者 catch 中的 return 语句之前执行的。更加一般的说法是,finally子句 应该是在控制转移语句之前执行,控制转移语句除了 return 外,还有 break 和 continue。另外,throw 语句也属于控制转移语句。虽然 return、throw、break 和 continue 都是控制转移语句,但是它们之间是有区别的。其中 return 和 throw 把程序控制权转交给它们的调用者(invoker),而 break 和 continue 的控制权是在当前方法内转移。
下面,再看两个代码片段:
// 代码片段5public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
try {
return 0;
} finally {
return 1;
}
}
}/* Output:
return value of getValue(): 1
*///:~// 代码片段6public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
return i;
} finally {
i++;
}
}
}/* Output:
return value of getValue(): 1
*///:~ 利用我们上面分析得出的结论:finally子句 是在 try子句 或者 catch子句 中的 return 语句之前执行的。 由此,可以轻松的理解代码片段 5 的执行结果是 1。因为 finally 中的 return 1;语句要在 try 中的 return 0;语句之前执行,那么 finally 中的 return 1;语句执行后,把程序的控制权转交给了它的调用者 main()函数,并且返回值为 1。
那为什么代码片段 6 的返回值不是 2,而是 1 呢? 按照代码片段 5 的分析逻辑,finally 中的 i++;语句应该在 try 中的 return i;之前执行啊? i 的初始值为 1,那么执行 i++;之后为 2,再执行 return i;那不就应该是 2 吗?怎么变成 1 了呢?
关于 Java 虚拟机是如何编译 finally 子句的问题,有兴趣的读者可以参考《 The JavaTM Virtual Machine Specification, Second Edition 》中 7.13 节 Compiling finally。那里详细介绍了 Java 虚拟机是如何编译 finally 子句。实际上,Java 虚拟机会把 finally 子句作为 subroutine 直接插入到 try 子句或者 catch 子句的控制转移语句之前。但是,还有另外一个不可忽视的因素,那就是在执行 subroutine(也就是 finally 子句)之前,try 或者 catch 子句会保留其返回值到本地变量表(Local Variable Table)中。待 subroutine 执行完毕之后,再恢复保留的返回值到操作数栈中,然后通过 return 或者 throw 语句将其返回给该方法的调用者(invoker)。
请注意,前文中我们曾经提到过 return、throw 和 break、continue 的区别,对于这条规则(保留返回值),只适用于 return 和 throw 语句,不适用于 break 和 continue 语句,因为它们根本就没有返回值。
下面再看最后三个代码片段:
// 代码片段7public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
@SuppressWarnings("finally")
public static int getValue() {
int i = 1;
try {
i = 4;
} finally {
i++;
return i;
}
}
}/* Output:
return value of getValue(): 5
*///:~// 代码片段8public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
i = 4;
} finally {
i++;
}
return i;
}
}/* Output:
return value of getValue(): 5
*///:~// 代码片段9public class Test {
public static void main(String[] args) {
System.out.println(test());
}
public static String test() {
try {
System.out.println("try block");
return test1();
} finally {
System.out.println("finally block");
}
}
public static String test1() {
System.out.println("return statement");
return "after return";
}
}/* Output:
try block
return statement
finally block
after return
*///:~请注意,最后个案例的唯一一个需要注意的地方就是,return test1(); 这条语句等同于 :
String tmp = test1(); return tmp;
因而会产生上述输出。
特别需要注意的是,在以下4种特殊情况下,finally子句不会被(完全)执行:
1)在 finally 语句块中发生了异常;
2)在前面的代码中用了 System.exit()【JVM虚拟机停止】退出程序;
3)程序所在的线程死亡;
4)关闭 CPU;
四. 异常的限制
当覆盖方法时,只能抛出在基类方法的异常说明里列出的那些异常。这意味着,当基类使用的代码应用到其派生类对象时,一样能够工作。
class BaseballException extends Exception {}
class Foul extends BaseballException {}
class Strike extends BaseballException {}
abstract class Inning {
public Inning() throws BaseballException {}
public void event() throws BaseballException {
// Doesn’t actually have to throw anything
}
public abstract void atBat() throws Strike, Foul;
public void walk() {} // Throws no checked exceptions }
class StormException extends Exception {}
class RainedOut extends StormException {}
class PopFoul extends Foul {}
interface Storm {
public void event() throws RainedOut;
public void rainHard() throws RainedOut;
}
public class StormyInning extends Inning implements Storm {
// OK to add new exceptions for constructors, but you must deal with the base constructor exceptions:
public StormyInning() throws RainedOut, BaseballException {}
public StormyInning(String s) throws Foul, BaseballException {}
// Regular methods must conform to base class:
void walk() throws PopFoul {} //Compile error
// Interface CANNOT add exceptions to existing methods from the base class:
public void event() throws RainedOut {}
// If the method doesn’t already exist in the base class, the exception is OK:
public void rainHard() throws RainedOut {}
// You can choose to not throw any exceptions, even if the base version does:
public void event() {}
// Overridden methods can throw inherited exceptions:
public void atBat() throws PopFoul {}
public static void main(String[] args) {
try {
StormyInning si = new StormyInning();
si.atBat();
} catch(PopFoul e) {
System.out.println("Pop foul");
} catch(RainedOut e) {
System.out.println("Rained out");
} catch(BaseballException e) {
System.out.println("Generic baseball exception");
}
// Strike not thrown in derived version.
try {
// What happens if you upcast? ----印证“编译器的类型检查是静态的,是针对引用的!!!”
Inning i = new StormyInning();
i.atBat();
// You must catch the exceptions from the base-class version of the method:
} catch(Strike e) {
System.out.println("Strike");
} catch(Foul e) {
System.out.println("Foul");
} catch(RainedOut e) {
System.out.println("Rained out");
} catch(BaseballException e) {
System.out.println("Generic baseball exception");
}
}
} ///:~异常限制对构造器不起作用
子类构造器不必理会基类构造器所抛出的异常。然而,因为基类构造器必须以这样或那样的方式被调用(这里默认构造器将自动被调用),派生类构造器的异常说明必须包含基类构造器的异常说明。
派生类构造器不能捕获基类构造器抛出的异常
因为 super() 必须位于子类构造器的第一行,而若要捕获父类构造器的异常的话,则第一行必须是 try 子句,这样会导致编译不会通过。
派生类所重写的方法抛出的异常列表不能大于父类该方法的异常列表,即前者必须是后者的子集
通过强制派生类遵守基类方法的异常说明,对象的可替换性得到了保证。需要指出的是,派生类方法可以不抛出任何异常,即使基类中对应方法具有异常说明。也就是说,一个出现在基类方法的异常说明中的异常,不一定会出现在派生类方法的异常说明里。
异常说明不是方法签名的一部分
尽管在继承过程中,编译器会对异常说明做强制要求,但异常说明本身并不属于方法类型的一部分,方法类型是由方法的名字及其参数列表组成。因此,不能基于异常说明来重载方法。
五. 自定义异常
使用Java内置的异常类可以描述在编程时出现的大部分异常情况。除此之外,用户还可以自定义异常。用户自定义异常类,只需继承Exception类即可。
在程序中使用自定义异常类,大体可分为以下几个步骤:
(1)创建自定义异常类;
(2)在方法中通过throw关键字抛出异常对象;
(3)如果在当前抛出异常的方法中处理异常,可以使用try-catch语句捕获并处理;否则在方法的声明处通过throws关键字指明要抛出给方法调用者的异常,继续进行下一步操作;
(4)在出现异常方法的调用者中捕获并处理异常。
六. 异常栈与异常链
1、栈轨迹
printStackTrace() 方法可以打印Throwable和Throwable的调用栈轨迹。调用栈显示了由异常抛出点向外扩散的所经过的所有方法,即方法调用序列(main方法 通常是方法调用序列中的最后一个)。
2、重新抛出异常
catch(Exception e) {
System.out.println("An exception was thrown");
throw e;
} 既然已经得到了对当前异常对象的引用,那么我们就可以像上面一样将其重新抛出。重新抛出的异常会把异常抛给上一级环境中的异常处理程序,同一个try子句的后续catch子句将被忽略。此外,如果只是把当前异常对象重新抛出,那么printStackTrace() 方法显示的仍是原来异常抛出点的调用栈信息,而并非重新抛出点的信息。要想更新这个信息,可以调用fillInStackTrace() 方法,这将返回一个Throwable对象,它是通过把当前调用栈信息填入原来那个异常对象而建立的。
看下面示例:
public class Rethrowing {
public static void f() throws Exception {
System.out.println("originating the exception in f()");
throw new Exception("thrown from f()");
}
public static void g() throws Exception {
try {
f();
} catch(Exception e) {
System.out.println("Inside g(),e.printStackTrace()");
e.printStackTrace(System.out);
throw e;
}
}
public static void h() throws Exception { try {
f();
} catch(Exception e) {
System.out.println("Inside h(),e.printStackTrace()");
e.printStackTrace(System.out);
throw (Exception)e.fillInStackTrace();
}
}
public static void main(String[] args) {
try {
g();
} catch(Exception e) {
System.out.println("main: printStackTrace()");
e.printStackTrace(System.out);
}
try {
h();
} catch(Exception e) {
System.out.println("main: printStackTrace()");
e.printStackTrace(System.out);
}
}
} /* Output:
originating the exception in f()
Inside g(),e.printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.g(Rethrowing.java:11)
at Rethrowing.main(Rethrowing.java:29)
main: printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.g(Rethrowing.java:11)
at Rethrowing.main(Rethrowing.java:29)
originating the exception in f()
Inside h(),e.printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.h(Rethrowing.java:20)
at Rethrowing.main(Rethrowing.java:35)
main: printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.h(Rethrowing.java:24)
at Rethrowing.main(Rethrowing.java:35)
*///:~3、异常链
异常链:在捕获一个异常后抛出另一个异常,并且希望把原始异常的信息保存下来。
这可以使用带有cause参数的构造器(在Throwable的子类中,只有Error,Exception和RuntimeException三个类提供了带有cause的构造器)或者使用initcause()方法把原始异常传递给新的异常,使得即使在当前位置创建并抛出了新的异常,也能通过这个异常链追踪到异常最初发生的位置,例如:
class DynamicFieldsException extends Exception {}
...
DynamicFieldsException dfe = new DynamicFieldsException();
dfe.initCause(new NullPointerException());
throw dfe;
...//捕获该异常并打印其调用站轨迹为:/**
DynamicFieldsException
at DynamicFields.setField(DynamicFields.java:64)
at DynamicFields.main(DynamicFields.java:94)
Caused by: java.lang.NullPointerException
at DynamicFields.setField(DynamicFields.java:66)
... 1 more
*/以 RuntimeException 及其子类NullPointerException为例,其源码分别为:
RuntimeException 源码包含四个构造器,有两个可接受cause:
public class RuntimeException extends Exception {
static final long serialVersionUID = -7034897190745766939L;
/** Constructs a new runtime exception with <code>null</code> as its
* detail message. The cause is not initialized, and may subsequently be
* initialized by a call to {@link #initCause}.
*/
public RuntimeException() { super();
} /** Constructs a new runtime exception with the specified detail message.
* The cause is not initialized, and may subsequently be initialized by a
* call to {@link #initCause}.
*
* @param message the detail message. The detail message is saved for
* later retrieval by the {@link #getMessage()} method.
*/
public RuntimeException(String message) { super(message);
} /**
* Constructs a new runtime exception with the specified detail message and
* cause. <p>Note that the detail message associated with
* <code>cause</code> is <i>not</i> automatically incorporated in
* this runtime exception's detail message.
*
* @param message the detail message (which is saved for later retrieval
* by the {@link #getMessage()} method).
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A <tt>null</tt> value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public RuntimeException(String message, Throwable cause) { super(message, cause);
} /** Constructs a new runtime exception with the specified cause and a
* detail message of <tt>(cause==null ? null : cause.toString())</tt>
* (which typically contains the class and detail message of
* <tt>cause</tt>). This constructor is useful for runtime exceptions
* that are little more than wrappers for other throwables.
*
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A <tt>null</tt> value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public RuntimeException(Throwable cause) { super(cause);
}
}NullPointerException 源码仅包含两个构造器,均不可接受cause:
public class NullPointerException extends RuntimeException {
/**
* Constructs a <code>NullPointerException</code> with no detail message.
*/
public NullPointerException() { super();
} /**
* Constructs a <code>NullPointerException</code> with the specified
* detail message.
*
* @param s the detail message.
*/
public NullPointerException(String s) { super(s);
}
}注意:
所有的标准异常类都有两个构造器:一个是默认构造器;另一个是接受字符串作为异常说明信息的构造器。
The above is the detailed content of Detailed introduction and analysis of Java exception model (picture). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Java is a popular programming language that can be learned by both beginners and experienced developers. This tutorial starts with basic concepts and progresses through advanced topics. After installing the Java Development Kit, you can practice programming by creating a simple "Hello, World!" program. After you understand the code, use the command prompt to compile and run the program, and "Hello, World!" will be output on the console. Learning Java starts your programming journey, and as your mastery deepens, you can create more complex applications.
