Unicode is a common character encoding set, so how does Unicode support JavaScript? This article will discuss the JavaScript language's support for UnicodeCharacter Set. I hope readers can understand the concept and usage of character sets in JavaScript from an essential point of view.
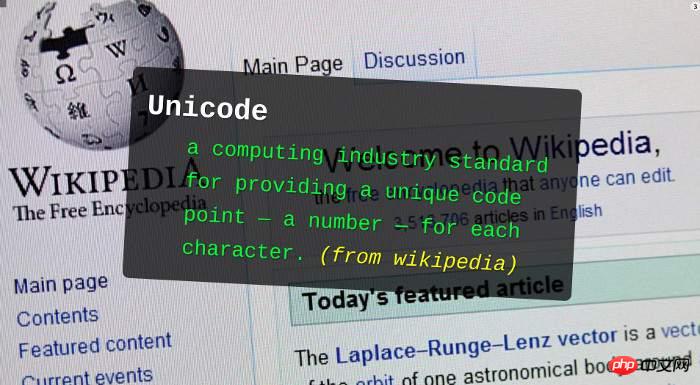
1. What is Unicode?
Unicode originated from a very simple idea: include all the characters in the world in one set. As long as the computer supports this character set, it can display all characters, and there will no longer be garbled characters.
It starts from 0 and assigns a number to each symbol, which is called a "code point". For example, the symbol for code point 0 is null (indicating that all binary bits are 0).
U+0000 = null
Copy after login
In the above formula, U+ indicates that the hexadecimal number immediately following is the Unicode code point.
Currently, the latest version of Unicode is version 7.0, which contains a total of 109,449 symbols, including 74,500 Chinese, Japanese and Korean characters. It can be approximated that more than two-thirds of the existing symbols in the world come from East Asian scripts. For example, the code point for "good" in Chinese is 597D in hexadecimal.
U+597D = 好
Copy after login
With so many symbols, Unicode is not defined at once, but by partition. Each area can store 65536 (216) characters, which is called a plane. Currently, there are 17 (25) planes in total, which means that the size of the entire Unicode character set is now 221.
The first 65536 character bits are called the basic plane (abbreviation BMP). Its code point range is from 0 to 216-1. When written in hexadecimal, it is from U+0000 to U+FFFF. All the most common characters are placed on this plane, which is the first plane defined and announced by Unicode.
The remaining characters are placed in the auxiliary plane (abbreviated as SMP), and the code points range from U+010000 to U+10FFFF.
2. UTF-32 and UTF-8
Unicode only specifies the code point of each character. What kind of byte order is used to represent it? This code point involves the encoding method.
The most intuitive encoding method is that each code point is represented by four bytes, and the byte content corresponds to the code point one-to-one. This encoding method is called UTF-32. For example, code point 0 is represented by four bytes of 0, and code point 597D is preceded by two bytes of 0.
U+0000 = 0x0000 0000
U+597D = 0x0000 597D
Copy after login
The advantage of UTF-32 is that the conversion rules are simple and intuitive, and the search efficiency is high. The disadvantage is that it wastes space. For the same English text, it will be four times larger than ASCII encoding. This shortcoming is so fatal that no one actually uses this encoding method. The HTML 5 standard clearly stipulates that web pages must not be encoded into UTF-32.
What people really needed was a space-saving encoding method, which led to the birth of UTF-8. UTF-8 is a variable-length encoding method, with character lengths ranging from 1 byte to 4 bytes. The more commonly used characters are, the shorter the bytes are. The first 128 characters are represented by only 1 byte, which is exactly the same as the ASCII code.
The above is the detailed content of Detailed introduction to Unicode and JavaScript code examples (). For more information, please follow other related articles on the PHP Chinese website!
Statement of this Website
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn
How to use WebSocket and JavaScript to implement an online speech recognition system Introduction: With the continuous development of technology, speech recognition technology has become an important part of the field of artificial intelligence. The online speech recognition system based on WebSocket and JavaScript has the characteristics of low latency, real-time and cross-platform, and has become a widely used solution. This article will introduce how to use WebSocket and JavaScript to implement an online speech recognition system.
WebSocket and JavaScript: Key technologies for realizing real-time monitoring systems Introduction: With the rapid development of Internet technology, real-time monitoring systems have been widely used in various fields. One of the key technologies to achieve real-time monitoring is the combination of WebSocket and JavaScript. This article will introduce the application of WebSocket and JavaScript in real-time monitoring systems, give code examples, and explain their implementation principles in detail. 1. WebSocket technology
Introduction to how to use JavaScript and WebSocket to implement a real-time online ordering system: With the popularity of the Internet and the advancement of technology, more and more restaurants have begun to provide online ordering services. In order to implement a real-time online ordering system, we can use JavaScript and WebSocket technology. WebSocket is a full-duplex communication protocol based on the TCP protocol, which can realize real-time two-way communication between the client and the server. In the real-time online ordering system, when the user selects dishes and places an order
How to use WebSocket and JavaScript to implement an online reservation system. In today's digital era, more and more businesses and services need to provide online reservation functions. It is crucial to implement an efficient and real-time online reservation system. This article will introduce how to use WebSocket and JavaScript to implement an online reservation system, and provide specific code examples. 1. What is WebSocket? WebSocket is a full-duplex method on a single TCP connection.
JavaScript and WebSocket: Building an efficient real-time weather forecast system Introduction: Today, the accuracy of weather forecasts is of great significance to daily life and decision-making. As technology develops, we can provide more accurate and reliable weather forecasts by obtaining weather data in real time. In this article, we will learn how to use JavaScript and WebSocket technology to build an efficient real-time weather forecast system. This article will demonstrate the implementation process through specific code examples. We
JavaScript tutorial: How to get HTTP status code, specific code examples are required. Preface: In web development, data interaction with the server is often involved. When communicating with the server, we often need to obtain the returned HTTP status code to determine whether the operation is successful, and perform corresponding processing based on different status codes. This article will teach you how to use JavaScript to obtain HTTP status codes and provide some practical code examples. Using XMLHttpRequest
In-depth understanding of PHP: Implementation method of converting JSONUnicode to Chinese During development, we often encounter situations where we need to process JSON data, and Unicode encoding in JSON will cause us some problems in some scenarios, especially when Unicode needs to be converted When encoding is converted to Chinese characters. In PHP, there are some methods that can help us achieve this conversion process. A common method will be introduced below and specific code examples will be provided. First, let us first understand the Un in JSON
Usage: In JavaScript, the insertBefore() method is used to insert a new node in the DOM tree. This method requires two parameters: the new node to be inserted and the reference node (that is, the node where the new node will be inserted).










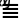 为例,它是一个辅助平面字符,码点为U+1
为例,它是一个辅助平面字符,码点为U+1


































