

Detailed explanation of MySQL indexes

The index of mysql is through B+tree. B+tree is a variant of balanced binary tree, so the query speed is very fast.
Indexes are mainly divided into clustered indexes and auxiliary indexes:
clustered index: The data in mysql is stored through the clustered index of the primary key, and the leaf nodes store Each row of data, so we use the primary key to query the speed
The reason why it is as fast as before is that the primary key is a clustered index, but in actual use only one such B+tree will be built, so this can explain why the primary key The only one.
Quote from the picture on the Internet:
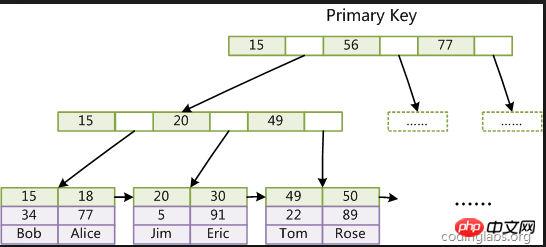
The search at each layer is an IO operation, and generally the number of B+tree layers is 2-4. So in the worst case, only 4 IO operations are required.
Auxiliary index: The difference between the auxiliary index and the clustered index is that not all the data is stored in the leaf nodes, but the location of the data is stored. It is equivalent to using the
auxiliary index to find the data, and then we need to find detailed information through the clustered index tree.
Quote from the diagram on the Internet:
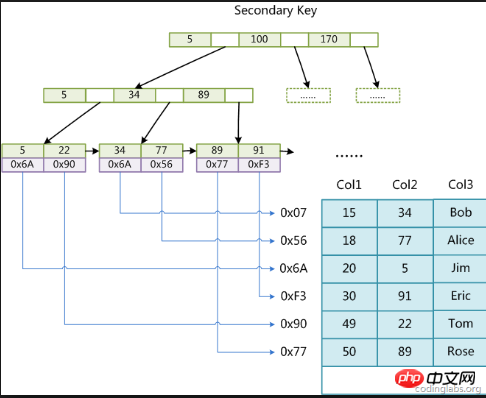
This diagram is a logical diagram, but the bottom layer points to the clustered index through the leaf nodes, that is Say, you still need to go through the
logic of the first type of diagram.
So the final result is that multiple auxiliary index trees point to a clustered index tree
(The painting is really ugly)
About when to create an index
Because this is a tree, it is retrieved through binary search, so it is applicable when used as the condition behind where, and this The values are in a wide range, suitable for index creation. It is not suitable for those with a small range (is_delete, sex, etc. enumerations).
For specific situations, we can analyze it through show index:
show index from company_related_person
Result:

Then calculate by cardinality
select 105/(select count(*) from company_related_person) from DUAL
The result obtained here is 0.913 (this value is related to the storage capacity, it is best to have a certain amount of data). The closer this value is to 1, the higher the efficiency of the index. If the value obtained is very small, it is recommended not to create it. Index
We can also check the usage of the index through explain
EXPLAIN select * from company_related_person where company_id='2'
Output

key represents the currently used index column . The last extra indicates which method is used. Here, Using index indicates that the index is used. If Using filesort indicates that the disk is read directly.
For those complex SQL statements with slow queries, you can use this ways to analyze.
The goal of SQL performance optimization: at least reach the range level, the requirement is ref level, if it can be consts, it is best.
1) Consts There is at most one matching row (primary key or unique index) in a single table, and the data can be read during the optimization phase.
2) ref refers to using a normal index.
3) range performs range retrieval on the index
4) index means reading directly from the disk
You can also see from the above figure that we use The ref
About the difference between index and key:
When we create an index, we often have this question, what is the difference between index and key? . Key is a key value, which is part of the relational model theory, such as primary key (Primary Key), foreign key (Foreign Key), etc., which are used for data integrity checking and uniqueness constraints. Index is at the implementation level. For example, you can index any column of a table. Then when the indexed column is in the Where condition in the SQL statement, you can get fast data location and thus fast retrieval. As for Unique Index, it is just one type of Index. The establishment of Unique Index means that the data in this column cannot be repeated
The above is the detailed content of Detailed explanation of MySQL indexes. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
 How to view sql database error
Apr 10, 2025 pm 12:09 PM
How to view sql database error
Apr 10, 2025 pm 12:09 PM
The methods for viewing SQL database errors are: 1. View error messages directly; 2. Use SHOW ERRORS and SHOW WARNINGS commands; 3. Access the error log; 4. Use error codes to find the cause of the error; 5. Check the database connection and query syntax; 6. Use debugging tools.
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
